Download as PDF, PPTX

















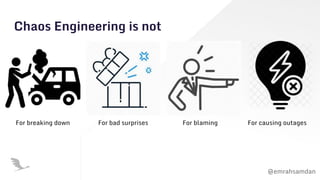


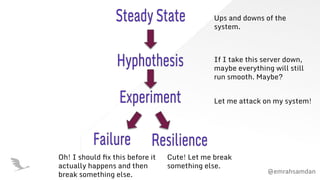











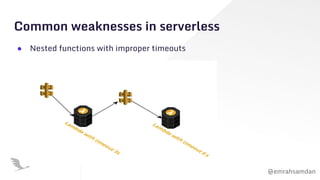

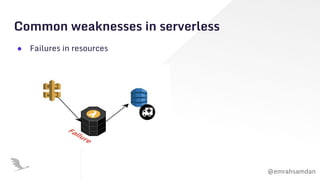

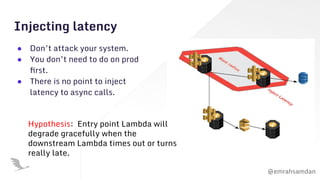




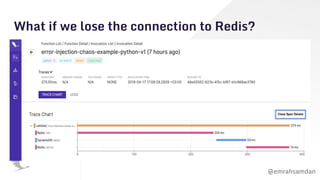





The document discusses chaos engineering, emphasizing its role in building resilient serverless applications by purposefully experimenting on systems to withstand adverse conditions. It highlights the importance of understanding system weaknesses, conducting chaos experiments safely, and learning from failures to improve system reliability. The presentation encourages proactive measures and communication to enhance software robustness rather than seeking to blame or cause disruptions.














































