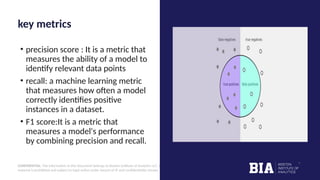
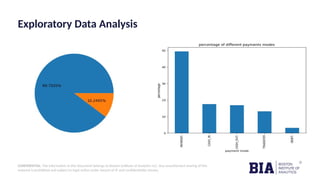
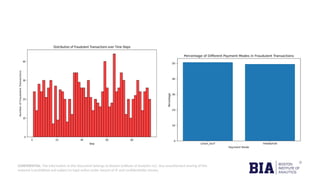
The document outlines a fraud detection analysis conducted by Boston Institute of Analytics for a company named Block Fraud, which aims to enter the Brazilian market with a pricing strategy based on their high accuracy. It describes the process of data cleaning, model training using logistic regression, and evaluation metrics, resulting in a high accuracy of 98.79% in detecting fraud. The conclusion emphasizes a positive financial impact from identifying fraudulent transactions, after accounting for missed and incorrectly labeled transactions.





































![PYTHON PROJECT[1] Online Fraud Fraud Detection Cybersecurity Anomaly Detec...](https://cdn.slidesharecdn.com/ss_thumbnails/pythonproject1-250421141954-bd5cebfc-thumbnail.jpg?width=640&height=640&fit=bounds)












































