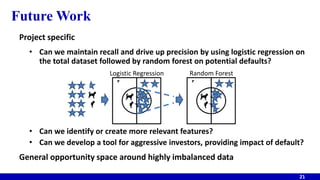
The document discusses a model developed to help investors forecast the probability of default in peer-to-peer lending, leveraging borrower data and macroeconomic indicators. It highlights the rapid growth of this market, with Lending Club as the leader, and outlines the complexities encountered in data modeling and analysis due to imbalanced datasets. The final model achieved high default recall but sacrificed precision, leading to calls for future work to improve feature relevancy and explore better classification techniques.



![Objectives
Current
Develop a tool to help
investors avoid loans likely
to default
A model to forecast
probability of default, given
loan information …
emphasize default recall
versus precision
4
Future Work
For investors interested in taking
more risk, develop a tool to
determine effective interest rate
A model forecasting impact of
default (x, fraction of loan value)
Effective interest rate (z) =
n√[(1+i)n - p*x]
where i = original interest
n = loan duration, yrs
p = probability of default](https://image.slidesharecdn.com/forecastingpeertopeerlendingrisk-160925054627/85/Forecasting-peer-to_peer_lending_risk-4-320.jpg)






























































![ai it hw mst prac[1] - Read-Offnly.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiithwmstprac1-read-only-250118093323-c97d352c-thumbnail.jpg?width=640&height=640&fit=bounds)




























