Download as PDF, PPTX














![Indexes
Analyze slow queries to find out what attributes
you can capitalize on.
When building a compound index, don’t include
fields that only appear in $or queries as part of
multi-attribute queries.
db.toasters.find({
slots: 4,
canBagel: true,
$or: [
{ material: "stainless-steel"},
{ price: {$lte: 50}},
]
})](https://image.slidesharecdn.com/oliverdodd-findinglovewithmongo-130308111802-phpapp01/75/Finding-Love-with-MongoDB-20-2048.jpg)
![Queries – Ranges
Translate "between" queries to in clauses when
dealing with discrete values.
$and: [
{a: { $gte: 0}},
{a: { $lte: 5}}
]
becomes
a: { $in: [0,1,2,3,4,5]}](https://image.slidesharecdn.com/oliverdodd-findinglovewithmongo-130308111802-phpapp01/75/Finding-Love-with-MongoDB-21-2048.jpg)




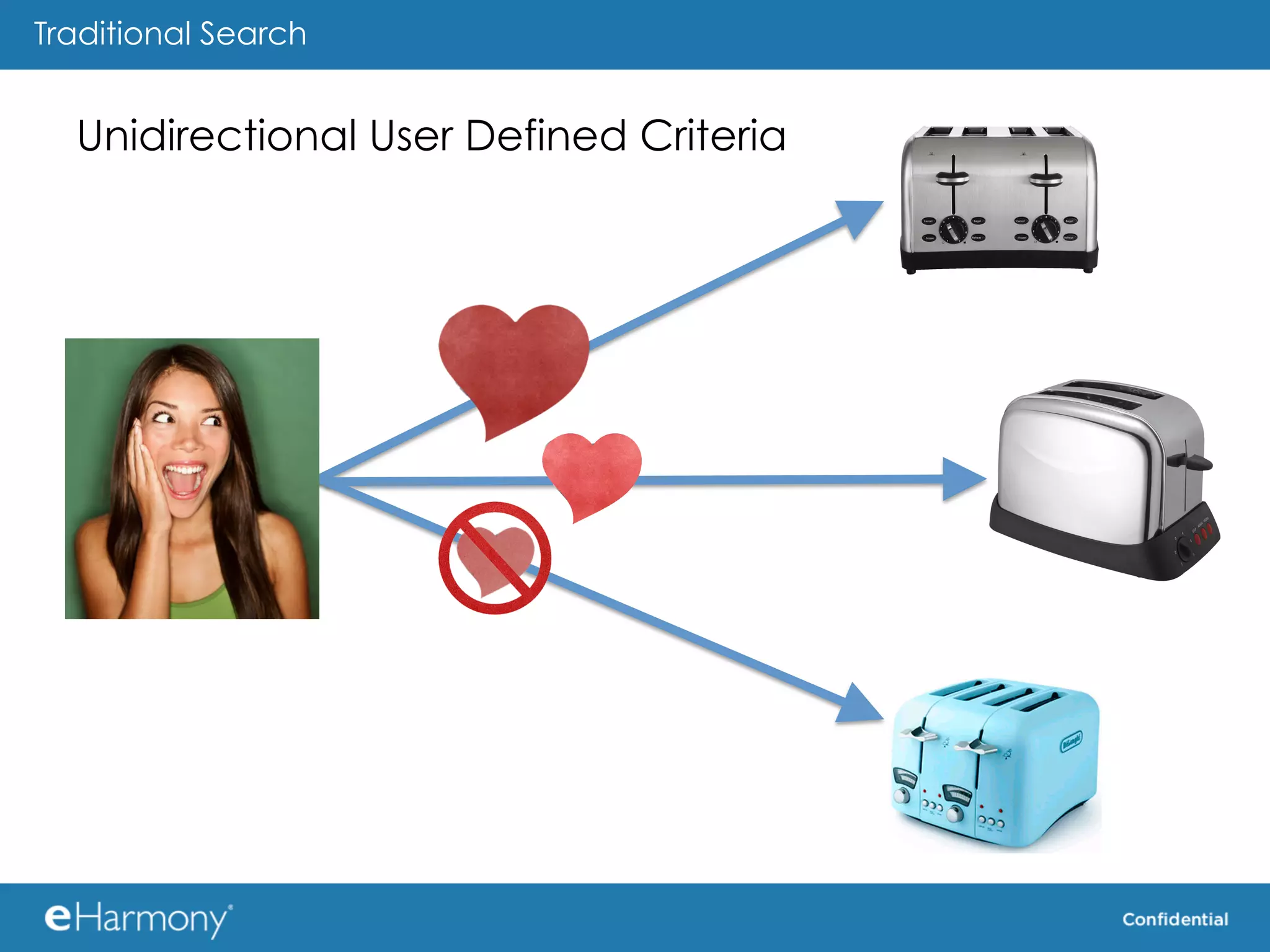
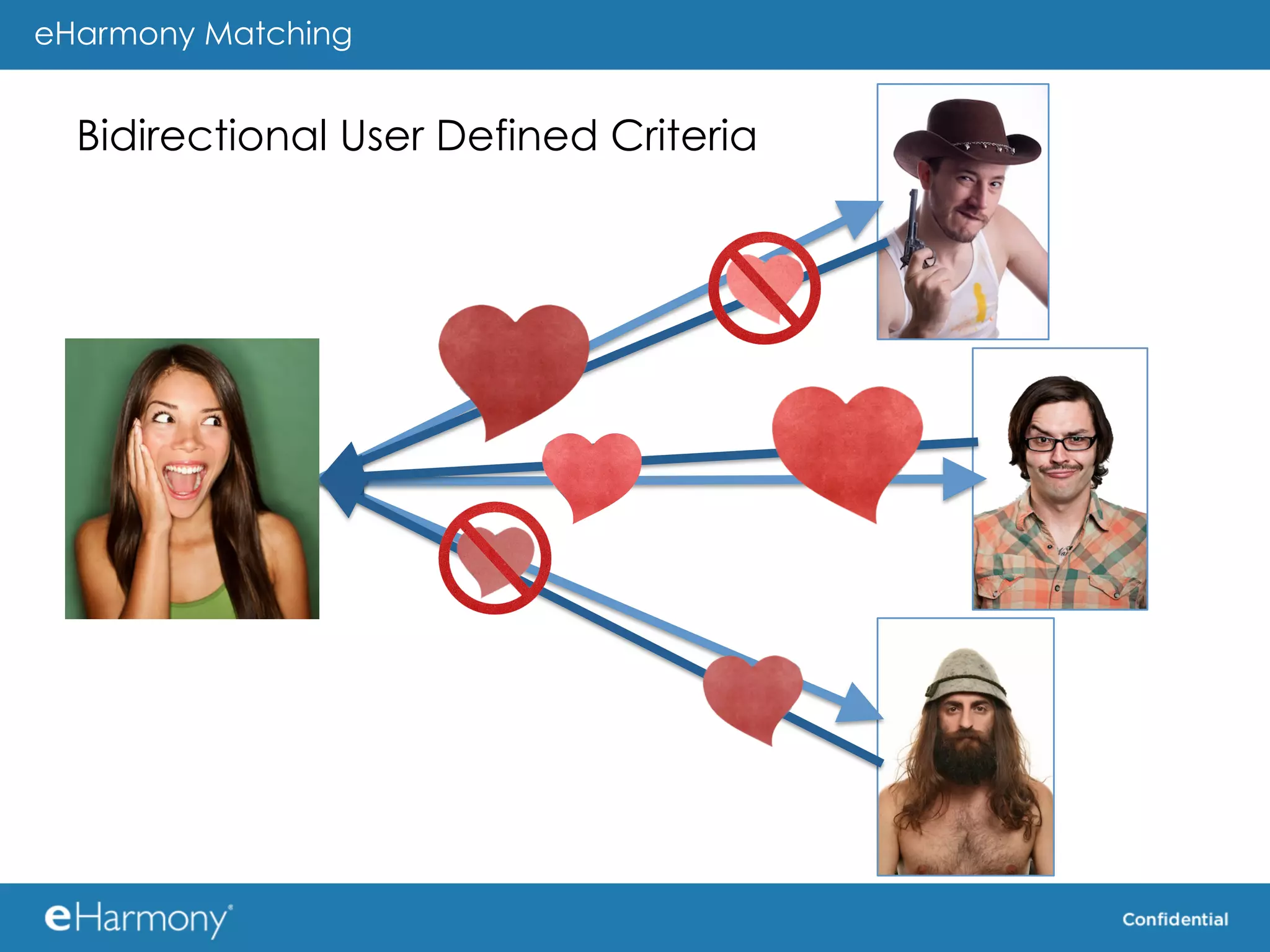
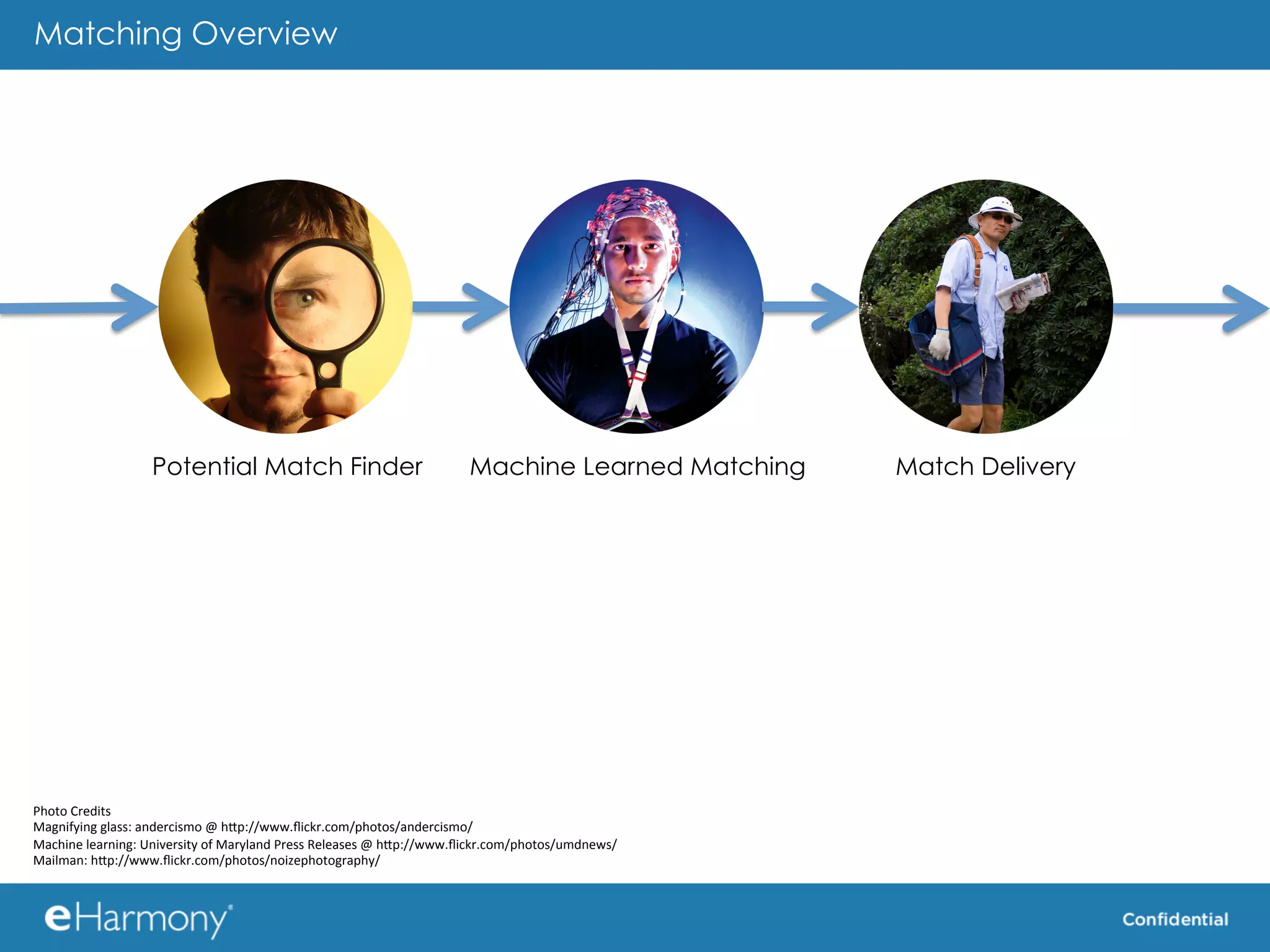
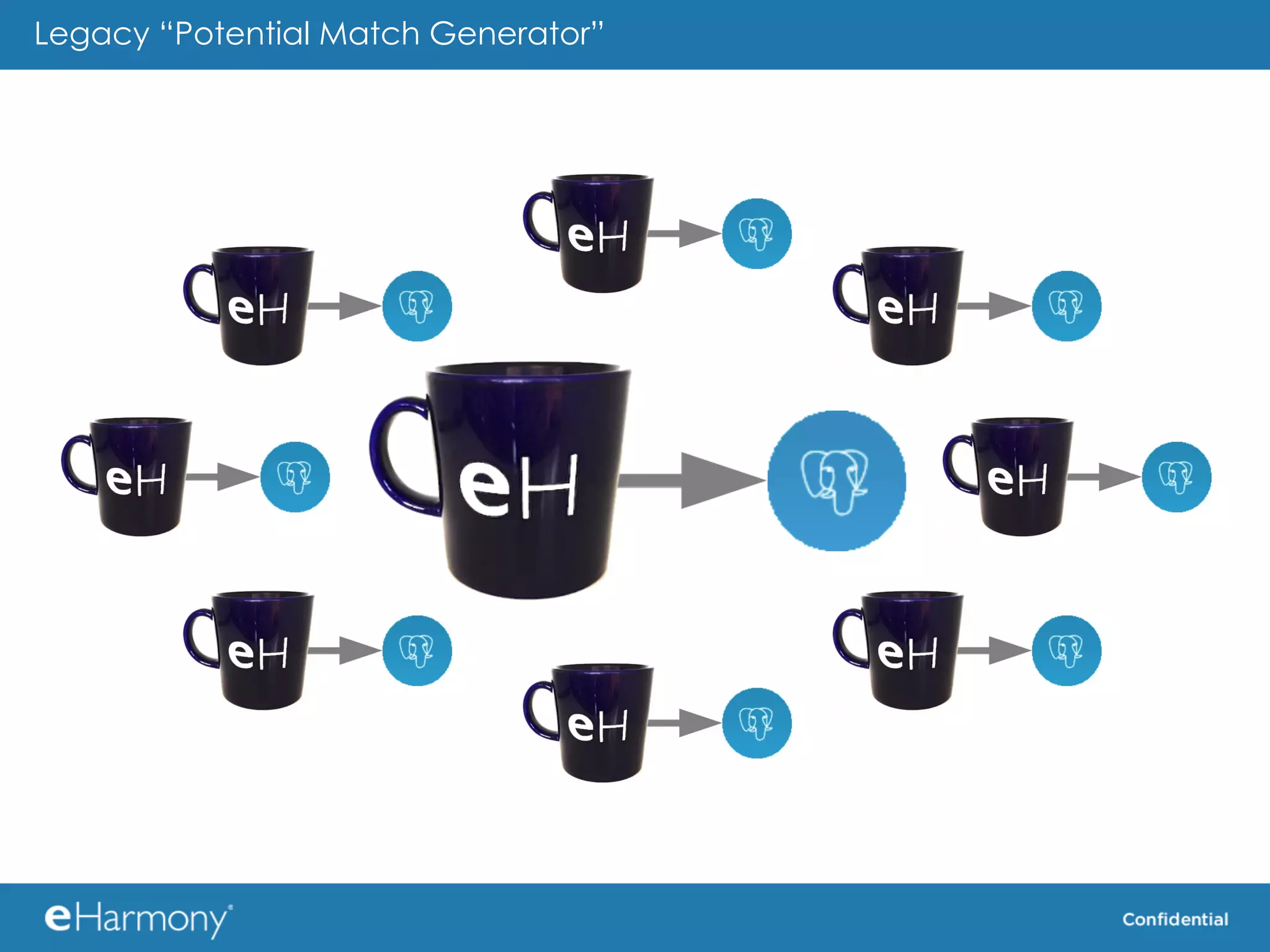
The document discusses using MongoDB as the data store for the "Potential Match Generator" component of an online dating service called eHarmony. Some key benefits of MongoDB cited include its scalability, built-in sharding and replication, and flexible schema. The document provides some tips for using MongoDB effectively, such as using real queries and data during testing, minimizing property names, using appropriate indexes, and considering how to shard data.








































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)











