Download to read offline
![Research Article
Online Adaptive Bearings Condition Assessment Using
Continuous Hidden Markov Models
Francesco Cartella1
and Hichem Sahli1,2
1
Electronics and Informatics Department (ETRO), Vrije Universiteit Brussel (VUB),
1050 Brussels, Belgium
2
Interuniversity Microelectronics Center (IMEC), 3001 Leuven, Belgium
Correspondence should be addressed to Francesco Cartella; fcartell@etro.vub.ac.be
Received 2 July 2014; Accepted 9 October 2014
Academic Editor: Xiaotun Qiu
Copyright © F. Cartella and H. Sahli. This is an open access article distributed under the Creative Commons Attribution License,
which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Condition assessment (CA) of bearings can be performed by using left-right hidden Markov models, because of the monotonically
increasing pattern of the bearings degradation. Classical CA approaches assume that all possible system states are fixed and known a
priori. The training of the system is performed offline at once with data from all of the system states. These assumptions significantly
impede condition assessment applications in case that all the possible states of the system are not known in advance, or changes in
environmental or operative conditions occur during the tool’s usage. To overcome these limitations, we propose combining left-right
continuous HMMs (CHMM) with a change point detection algorithm for (i) estimating, from historical observations, the initial
number of the CHMM states and the initial guess of its model parameters and (ii) updating the state space as well as the model
parameters during monitoring. Moreover, to deal with multidimensional sensor measurements, we propose using kernel principal
component analysis for dimensionality reduction. Qualitative and quantitative evaluations of the proposed methodology have been
performed using both simulated and real data from the NASA benchmark repository. Compared to state of the art techniques, the
proposed methodology results in (i) an improvement of the HMM training phase in terms of iterations number; (ii) the detection
of unknown states at an early stage; and (iii) an effective change of the CHMM’s structure to represent the degradation processes
more accurately in presence of unknown conditions.
1. Introduction
Machines and equipments breakdown in industrial environ-
ments can have significant impact in the profitability of a
business. Maintaining the engineering assets in operating
conditions is an industrial and economical requirement.
Nowadays optimization strategies for maintenance are an
important part of research for companies [1, 2], since, next
to energy costs, maintenance spending due to equipment or
machine failure can be the largest part of the operational
budget [3].
Corrective maintenance [1, 4], which is the system main-
tenance strategy subject of this work, is based on condition
monitoring and is performed after a degradation modality
emerges in a system, with the goal of preventing the system
from failing. A fundamental requirement of this strategy is
the detection of the abnormal behavior, that will lead to the
system failure, at an early stage in order to give enough time
to perform the repair operations.
Industrial equipments and their components are often
characterized by a very complex structure. For this reason
the usage of mathematical models for condition monitoring
can represent an arduous task. On the other hand, industrial
machines are usually equipped with monitoring devices (sen-
sors placed in critical parts of the system under study) which
are able to record and collect large amount of measurements.
Given the availability of these huge amounts of data, the
methodology proposed in this paper will focus on data-
driven models [5], which are based on machine learning
approaches.
The classical usage of data-driven techniques consists of
two phases: a first training phase in which a preprocessing
of the historical raw sensory data is performed in order to
extract relevant features, which will be then exploited to
Hindawi Publishing Corporation
Advances in Mechanical Engineering
Article ID 758785](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-1-320.jpg)
![2 Advances in Mechanical Engineering
learn the parameters of behavioral models of the considered
machine and a second application phase, during the runtime
of the system, in which the trained model is used along with
runtime measurement to evaluate the health condition of
the machine. The advantage of such approaches is that, for
a well monitored system, there is no need for knowledge
of the system’s internal physical mechanism or for a prior
mathematical model to represent the system degradation.
Several data-driven models for condition monitoring
have been proposed, such as clustering techniques [6],
data-mining approaches [7], support vector machines [8],
dynamic Bayesian networks [9], and hidden Markov models
[10, 11]. Hidden Markov models (HMMs) have been shown
to be effective pattern recognition tools in a large variety
of recognition tasks. They have been successfully applied to
condition monitoring of manufacturing machines [12, 13] as
well as in other application domains ranging from speech
recognition [14] to intrusion detection in computer systems
[15].
The common usage of hidden Markov hodels, especially
for condition assessment applications, consists of dividing
the degradation pattern of the historical data of the system
under study into different degradation levels, from normal
to deeper degradation (i.e., good, partially worn, seriously
worn, broken), and training either several HMMs, each one
corresponding to observations (features) from a particular
degradation level [16–19] or training a single HMM using
historical observations corresponding to the normal behavior
of the system [19–23]. Online condition assessment is then
performed by selecting the HMM that, on new incoming
data, gives the highest likelihood or by detecting an abnor-
mality if the likelihood is lower than a threshold defined
for the normal behavior [19]. However, the latter approach
is not well suited to condition assessment of industrial
systems, as it can be used only for anomaly detection. Indeed,
such approach is only able to detect a condition that is
different from the considered normal behavior in the training
phase.
Another approach [14] consists of training a single HMM
by using the sensor measurements corresponding to the
entire lifetime of the system, by setting the number of states
equal to the number of degradation stages contained in the
training history. By using this approach, the model maps each
degradation phase to a state of the HMM. The condition
assessment is performed online on new incoming data by
calculating the Viterbi path [24] which returns the most
probable state sequence.
The approaches described above assume that all possible
system condition states are known a priori and that training
data sets from the associated states are available. In addition,
the training procedure has to be performed offline and only
once at the beginning, with the available training set. For
this reason, the trained models are able to recognize only
the conditions contained in the training data. These assump-
tions significantly impede component diagnosis applications
when:
(i) it is difficult to identify and train all of the possible
states of the system in advance;
(ii) environmental factors or operative conditions change
during the tool’s usage.
Since industrial machines are constantly subjected to
updates, changes of configurations or changes of working
conditions, a need for models that are able to automati-
cally adapt to new situations, by dynamically learning the
structure and the parameters, is required. To the best of our
knowledge, such approach has only been used by Lee et al.
[25], whom proposed a modified hidden Markov model with
variable state space to estimate the current state of system
degradation as well as to detect unknown faults at an early
stage. A multivariate statistical process control is used to
detect the occurrence of an unknown condition by measuring
the deviation of the current signal from a reference signal
representing prior known states; then the HMM is updated
by including a new state. The limitation of this approach is
that (i) one should collect reference signal representing prior
known states and (ii) define a parametric model (Gaussian in
the case of [25]) of the observation signals.
To overcome the abovementioned drawbacks of most
of the state of the art HMM-based condition assessment
approaches, we proposed in [26] a methodology based on
HMMs which is able to perform (i) an automatic estimation
of the initial parameters and number of states of the model
and (ii) an online adaptation of the model structure, together
with the online learning of the parameters, in presence of not
stable conditions. The proposed approach aims to diagnose
the degradation processes of industrial systems using a
variable state space left-right continuous HMM (CHMM), by
integrating a change point detection (CPD) algorithm [27].
The CPD algorithm allows detecting the dynamic changes
of machine condition and hence of the HMM parameters,
by discovering time points at which the properties of the
input time-series data change, corresponding to the (signal)
segmentation of the observed data stream. The detected
segments correspond to the different states of the machine. In
this work, as a further contribution, we evaluate the reliability
of the data driven identification of the number of (possible)
system’s states by means of clustering techniques and the
Dunn’s validity indexes [28].
Concerning the online condition assessment, the com-
parison between the estimated most-likely state, by the
Viterbi algorithm [24], and the CPD detected segments
(states) allows fast failures detection. Moreover, since the
CPD algorithm is independent from the density model of the
observation, in comparison with the method of Lee et al. [25],
our proposal is more effective as it is independent of prior
data and allows faster detection of unknown conditions.
The used CPD algorithm is able to handle 1-dimensional
time series, while industrial machines are usually equipped
with several sensors for which multiple features can be
extracted, resulting in a multidimensional observation vector.
To have an accurate modeling for real world cases, it is
essential to consider as much information as possible related
to system changes, carried by multiple signals. In this work
we propose applying kernel principal component analysis
(KPCA) [29–31] for dimensionality reduction. KPCA, being
able to effectively deal with nonlinear data, embeds the](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-2-320.jpg)
![Advances in Mechanical Engineering 3
information coming from all the measurements in to a 1-
dimensional time series and allows a faster detection of
condition changes by the CPD algorithm.
Although it is adaptable to a wide range of health
estimation problems, we applied the proposed methodology
on bearings condition monitoring. This choice derives from
the fact that, being the most common mechanical elements in
industry, bearings are the components which most frequently
fail in rotating machines [32]. Furthermore, given the nature
of the component, we can assume that the degradation pat-
tern of bearings is monotonically increasing and, therefore,
the use of left-right HMMs is well-motivated.
The rest of the paper is organized as follows. Section 2
gives a short overview of the used concepts and methods,
namely, continuous left-right hidden Markov models, the
preprocessing and features extraction techniques, and the
change point detection algorithm. In Section 3, we provide
a detailed description of the proposed approach. In Section 4
experimental results are discussed. The conclusion and future
research directions are given in Section 5.
2. Methods and Algorithms
Before going into a more detailed discussion of the proposed
approach, an overview of the techniques used in this paper is
given in this section.
2.1. Left-Right Continuous Hidden Markov Models. Left-
right vontinuous hidden Markov models (CHMMs) [14] are
dynamic models in which there are two types of variables:
a state variable describing the system state, which is never
observed/measured directly (hidden), and an observation
variable which is related to the hidden state.
A left-right CHMM 𝜆 = (𝐴, 𝐶, 𝜇, 𝑈, 𝜋) is characterized by
the following:
(1) 𝑁, the number of states in the model, 𝑆 = {𝑆1, . . . , 𝑆 𝑁}
the set of states, and 𝑠𝑡 the state at time 𝑡,
(2) the state transition probability distribution 𝐴 = {𝑎𝑖𝑗}
where
𝑎𝑖𝑗 = 𝑃 (𝑠𝑡+1 = 𝑆𝑗 | 𝑠𝑡 = 𝑆𝑖) , 1 ≤ 𝑖, 𝑗 ≤ 𝑁, (1)
(3) X𝑡, the continuous observation vector emitted from
the state at time 𝑡,
(4) the observation density, represented by a finite mix-
ture:
𝑏𝑗 (X) =
𝑀
∑
𝑚=1
𝑐𝑗𝑚ℵ (X, 𝜇 𝑗𝑚, U 𝑗𝑚) , 1 ≤ 𝑗 ≤ 𝑁, (2)
where X is the vector being modeled, 𝑐𝑗𝑚 the mixture
coefficient for the mth mixture in state 𝑗, and ℵ is any
log-concave or elliptically symmetric density (usually
a Gaussian), with mean vector 𝜇𝑗𝑚 and covariance
matrix U 𝑗𝑚 for the mth mixture component in state 𝑗.
The parameters 𝑐𝑗𝑚, 𝜇𝑗𝑚, and U 𝑗𝑚, are the coefficients
of 𝐶, 𝜇 and 𝑈, respectively,
(5) the initial state distribution 𝜋 = {𝜋𝑖} where
𝜋𝑖 = 𝑃 (𝑠1 = 𝑆𝑖) , 1 ≤ 𝑖 ≤ 𝑁. (3)
It is proved that the probability density function of (2)
can be used to approximate, arbitrarily closely, any finite,
continuous density function [33]. Hence it can be applied to
a wide range of problems.
The left-right topology has the property that the state
index can either increase or stay the same, as time goes on.
In this case, the following holds for the coefficients of the
transition matrix:
𝑎𝑖𝑗 = 0, 𝑗 < 𝑖, (4)
𝑎𝑖𝑗 = 0, 𝑗 > 𝑖 + Δ, (5)
𝑎 𝑁𝑁 = 1, (6)
𝑎 𝑁𝑖 = 0, 𝑖 < 𝑁, (7)
where (4) avoids transition to previous states and (5) avoids
jumps of more than Δ states, while the state 𝑁 is an absorbing
state. Moreover, since the model starts from state 𝑆1, the initial
state probabilities have the following property:
𝜋𝑖 = {
0 𝑖 ̸= 1
1 𝑖 = 1.
(8)
For CHMMs applied to condition monitoring, learning
and inference procedures can be used.
(1) Learning: adjust the model parameters 𝜆 = (𝐴, 𝐶, 𝜇,
𝑈, 𝜋) in order to maximize the probability 𝑃(X | 𝜆);
that is, for the considered CHMM structure, find the
model parameters that better fit the historical sensor
measurements X. This problem is solved through the
Baum-Welch algorithm [34].
(2) Decoding: given a model 𝜆 = (𝐴, 𝐶, 𝜇, 𝑈, 𝜋) and a se-
quence of sensor measurements X = X1, X2, . . . , X 𝑇,
find the hidden state sequence 𝑆 = 𝑠1, 𝑠2, . . . , 𝑠 𝑇 that
has most likely produced the observation sequence.
The solution of this problem is given by the Viterbi
algorithm [24].
In the next section we will describe how we can fit
the multidimensional time-series input coming from the
machine sensors into a CHMM model.
2.2. Feature Extraction and Dimensionality Reduction. In
this paper, the inputs are vibration signals originating from
sensors on the machine under study. For this purpose, one
accelerometer or more accelerometers are placed in the
component housing and are used to translate the vibrations
emitted to an electric continuous signal. For each sensor,
the electric signal measured is then sampled at a predefined
sampling frequency. The monitoring system of the machine
acquires and stores such samples one at a time, under the
form of a digital signal, which represents the raw input data,
referred to as 𝑟(𝑡) with 1 ≤ 𝑡 ≤ 𝑇. It is assumed that a](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-3-320.jpg)
![4 Advances in Mechanical Engineering
r(t)
Window
1
Window
2
Window
3
Window
n − 1
Window
n
X(1) X(2) X(3) X(n − 1) X(n)· · ·
· · ·
Figure 1: Feature extraction from raw signals.
characteristic shape of the measured vibration is related to the
actual condition of the component.
Due to the high sampling frequency that is often used, a
high-dimensional signal is measured. Moreover, consecutive
values of a time series are usually not independent but
highly correlated; thus there is a lot of redundancy. Hence,
rather than looking at each point in time sequentially to
detect anomalies, it is common to use sliding windows
of length 𝐿. Within each window, 𝑘 and 𝑑 features are
calculated, resulting in a vector of 𝑑 components X(𝑘) =
[𝑥1(𝑘), 𝑥2(𝑘), . . . , 𝑥 𝑑(𝑘)] 𝑇
. Finally, the raw signal 𝑟(𝑡) is trans-
formed in a multivariate time series as (10). The process is
illustrated in Figure 1. Consider
Raw signal: 𝑟 (𝑡) = 𝑟 (1) , . . . , 𝑟 (𝑇)
↓ features extraction,
X (𝑡) = [X (1) , . . . , X (𝑛)] ,
(9)
X (𝑡) =
[
[
[
[
[
[
𝑥1 (1)
...
𝑥 𝑑 (1)
]
]
]
, . . . ,
[
[
[
𝑥1 (𝑛)
...
𝑥 𝑑 (𝑛)
]
]
]
]
]
]
. (10)
In this work, as also explained in Sections 4.2.1 and 4.2.3,
we considered windows of size 𝐿 = 20480 (fixed by the used
data set) and 𝑑 = 3 time domain features, namely, the mean,
the root mean square, and the kurtosis, of the sensory signals.
It has to be noted that frequency [35] (i.e., Fourier transform)
or time-frequency [36, 37] (i.e., wavelet transform) domain
features could be used as well.
Since the considered CPD algorithm is able to process
1-dimensional signals, a further dimensionality reduction
technique has to be applied on the 𝑑-dimensional features
vectors. In this paper, kernel principal component analysis
(KPCA) [29–31] is applied as a technique for dimensionality
reduction.
In the literature, principal component analysis (PCA) has
been extensively used as a features extraction technique for
condition assessment applications [18]. However, KPCA has
been shown to perform better than the standard PCA for
processes with particularly nonlinear characteristics [31]. The
basic idea of KPCA is that when the variations are nonlinear,
the data can always be mapped into a higher-dimensional
space, by means of nonlinear kernel functions, in which they
vary linearly. In this work Gaussian radial basis kernels have
been used. The reader is referred to [29, 31] for the details on
KPCA.
The main advantages of KPCA are the fact that (i) it does
not involve nonlinear optimization [29] since it requires only
linear algebra, making it as simple as standard PCA which
requires only the solution of an eigenvalue problem; (ii) due
to its ability to use different kernels, it can handle a wide
range of nonlinearities; (iii) it does not require the number of
components to be extracted be specified prior to modeling.
Applying KPCA on feature vectors X(𝑡) generates a 1-
dimensional time-series, 𝑦(𝑡), (𝑡 = 1, . . . , 𝑛), which can be
used as input to the CPD algorithm.
2.3. Change Point Detection Algorithm. The change point
detection approaches apply data mining techniques to iden-
tify the time points at which the changes, that is, events, occur.
This has been discussed in several applications such as fraud
detection [38], rare event discovery [39], event/trend change
detection [27], and activity monitoring [40].
In [27] a method has been proposed for the detection
of the appropriate set of number of points that minimizes
the error in fitting a predefined function using maximum
likelihood. There is no fixed number of change-points to be
detected. Moreover, no constraints are imposed on the class
of functions that will be fitted to the subsequences between
successive change-points.
Following the notation in [27], let 𝑦(𝑡), (𝑡 = 1, . . . , 𝑛), be
the time series to be segmented. It is assumed that the time
series can be modeled mathematically, where each model
is characterized by a set of parameters. The problem of
change-points detection is formulated as finding a piecewise
segmented model, given by the following:
𝑌 = 𝑓1 (𝑡, V1) + 𝑒1 (𝑡) , (1 < 𝑡 ≤ 𝜃1) ,
= 𝑓2 (𝑡, V2) + 𝑒2 (𝑡) , (𝜃1 < 𝑡 ≤ 𝜃2) ,
= ⋅ ⋅ ⋅
= 𝑓𝑙 (𝑡, V𝑙) + 𝑒𝑙 (𝑡) , (𝜃𝑙−1 < 𝑡 ≤ 𝑛) ,
(11)
where 𝑓𝑖(𝑡, V𝑖) is the function (with its vector of parameters V𝑖)
that is fitted to the segment 𝑖. The 𝜃𝑖’s are the change-points
between successive segments, and 𝑒𝑖(𝑡)’s are error terms.](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-4-320.jpg)
![Advances in Mechanical Engineering 5
Several types of basis functions, 𝑓𝑖(𝑡, V𝑖), can be consid-
ered, for example, algebraic polynomials, wavelet, Fourier,
and so forth [41]. In our current implementation polynomial
fitting functions have been selected, since they represent a
good compromise between expressiveness power and com-
putational effort.
In [27], two CPD approaches have been proposed, the
batch (offline) and the incremental (online). In the batch
version, the entire data set is available in advance, from
which the best set of change-points is determined. In the
incremental version, the algorithm receives new data points
one at a time and determines if the new observation causes
a new change-point to be discovered. Both approaches are
summarized here after. Details on the implementation can be
found in [27].
2.3.1. Batch Algorithm. The batch CPD algorithm assumes
that the entire time series data is available before the analysis
begins. Let 𝑆 be the residual sum of squares for the selected
fitting function that maintains time points 𝑡𝑖, 𝑡𝑖+1, . . . , 𝑡𝑗. In
this paper we define the likelihood criterion as L(𝑖, 𝑗) = 𝑆
since we used a homoscedastic error model [27].
The key idea behind the algorithm in [27] is that, at every
iteration, each segment is examined to see whether it can be
split into two significantly different segments. The splitting
procedure can be illustrated by a consideration of the first
stage, since all subsequent stages consist of equivalent scaled-
down problems.
Let the data set cover the time points 𝑡1, 𝑡2, . . . , 𝑡 𝑛. The
change-point in the first stage is the 𝑗 minimizing L(1, 𝑗) +
L(𝑗 + 1, 𝑛), say 𝑗∗
. Here 𝑗∗
is defined as follows:
L (1, 𝑗∗
) + L (𝑗∗
+ 1, 𝑛) = min
𝑝≤𝑗≤𝑛−𝑝
L (1, 𝑗) + L (𝑗 + 1, 𝑛) .
(12)
The range of 𝑗 depends on the fact that at least 𝑝 points are
needed for model fitting in each segment.
At the second stage, the best candidate change-points 𝑐1
and 𝑐2 of each of the two segments are located. The selection
of the better of these two candidates yields a division of the
original sequence into three segments. Assuming that point 𝑐1
is chosen, now the likelihood criteria of the model becomes
as follows:
L = (L (1, 𝑐1) + L (𝑐1 + 1, 𝑗∗
) + L (𝑗∗
+ 1, 𝑛))
< (L (1, 𝑗∗
) + L (𝑗∗
+ 1, 𝑐2) + L (𝑐2 + 1, 𝑛)) .
(13)
The procedure above is repeated until a stopping criterion
is reached. Once the algorithm has detected all “real” change-
points, adding any more change-points the likelihood will
increase. Therefore, the algorithm should stop when the like-
lihood criteria becomes stable or starts to increase. Formally,
if in iterations 𝑧 and 𝑧 + 1 the respective likelihood criteria
values are L 𝑧 and L 𝑧+1, the algorithm should stop if
(L 𝑧 − L 𝑧+1)
L 𝑧
< 𝑠, (14)
where 𝑠 is a user-defined stability threshold. When stability
threshold 𝑠 is set to 0%, the algorithm stops only when the
likelihood criteria starts increasing.
2.3.2. Incremental Algorithm. In an online setting, the
change-point detection must proceed concurrently with data
collection. The key idea of the incremental algorithm is that
if the next data point collected by the sensor reflects a signif-
icant change in phenomenon, then the likelihood of being a
change-point is going to be smaller than the likelihood that
it is not. However, if the difference in likelihoods is small,
we cannot definitively conclude that a change did occur,
since it may be the artifact of a large amount of noise in the
data. Therefore a user-defined likelihood increase threshold
is introduced. Consider
(Lno change − Lchange)
Lno change
> 𝛿, (15)
where 𝛿 is a user-defined likelihood increase threshold.
Suppose that the last change-point was detected at time
𝑡𝑙−1. At time 𝑡𝑙 the algorithm starts by collecting enough data
to fit the regression model. Suppose at time 𝑡𝑗 a new data
point is collected. The candidate change-point is found by
determining 𝑡𝑖, with likelihood criterion Lmin(𝑙, 𝑗), such that
Lmin (𝑙, 𝑗) = min
𝑙<𝑖≤𝑗
L (𝑙, 𝑖) + L (𝑖 + 1, 𝑗) . (16)
If this minimum is significantly smaller than L(𝑙, 𝑗), that
is, the likelihood criteria of no change-points from 𝑡𝑙 to
𝑡𝑗, then 𝑡𝑖 is a change-point. Otherwise, the process should
continue with the next point, that is, 𝑡𝑗+1.
In the incremental algorithm, execution time is a sig-
nificant factor. If enough information is stored, some of
the calculations can be avoided. Thus, at time 𝑡𝑗+1 to find
likelihood criteria
Lmin (𝑙, 𝑗 + 1) = min
𝑙<𝑖≤𝑗
L (𝑙, 𝑖) + L (𝑖 + 1, 𝑗 + 1) , (17)
it is only necessary to calculate L(𝑖 + 1, 𝑗 + 1), since (𝑙, 𝑖) was
calculated in the previous iteration.
It should be noted that if a change-point is not detected for
a long time, the successive computations become increasingly
expensive. A possible solution is to consider a sliding window
of only the last 𝑞 points.
3. Framework
The framework of the proposed approach is illustrated in
Figure 2. As discussed in the introduction, the methodology
is applied in two phases, the training (phase 1) and the online
application (phase 2).
3.1. Phase 1: Estimation of the Initial Number of States and
Parameters Initialization. During the first phase, we assume
that enough historical raw data have been collected from the
monitoring system of the machine under study. Such data can
be measurements from multiple sensor types (temperature,](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-5-320.jpg)

![Advances in Mechanical Engineering 7
uniform distribution, for each 𝑗 and 𝑚 : 𝑐𝑗𝑚 = 1/𝑀, 𝑀 being
the number of mixtures.
Together with the features extracted from the training
histories, the estimated initial parameters 𝜆0 are used as
inputs to the Baum-Welch procedure. The obtained optimal
model parameters, 𝜆∗
, of the 𝑁∗
-states left-right CHMM, are
then used in the following phase 2 for the online adaptive
condition assessment.
3.2. Phase 2: Online Adaptive Condition Assessment. The
application phase is performed on new incoming data which
are referred to as testing signal in Figure 2. These raw data are
acquired online, during the normal runtime of the machine
under study and are collected one sample a time. When
a window of predefined length 𝐿 of points are acquired,
the feature extraction procedure is executed to produce
multidimensional features. Two parallel process are then
executed: the trained CHMM is used to estimate the current
system’s state, while the online CPD algorithm keeps track
of the encountered changes of conditions to possibly detect
previously unknown situations. In particular:
(i) for condition assessment, the multidimensional fea-
tures signal is input to the inference algorithm, using
the current 𝑁∗
-states left-right CHMM model and its
optimal parameters 𝜆∗
, to calculate, via the Viterbi
algorithm [14], the most probable state sequence,
given the observations up to that moment. The last
state in the inferred sequence is then selected as the
actual condition of the machine;
(ii) for possible HMM state and parameters update, we
map the multidimensional features to 1-dimensional
signal using the out-of-sample extension according to
the kernel PCA parameters calculated in the training
phase. The obtained 1-dimensional signal is input to
the online CPD algorithm to detect possible changes,
which could correspond to state changes. Here, we
assume that an unknown situation is experienced
by the system when the detected segments (change-
points) exceed 𝑁∗
, being the number of states of the
optimal CHMM of the previous phase or iteration.
In such case, when enough samples coming from
the new condition are acquired, a new state is added
to the CHMM, to obtain a new model with 𝑁∗
=
𝑁∗
+ 1 states. The model parameters, 𝜆∗
, are also
adapted to the new situation, by performing the
training procedure as described above in phase 1,
using the current testing signal together with the
training histories.
4. Experimental Results
To verify the effectiveness of the proposed methodology, sev-
eral experiments have been performed both on simulated and
on real data. The simulated data were generated according
to the parameters described in the example reported in [25],
while condition monitoring data related to bearings taken
from the NASA benchmark repository [42] have been used
as real data. All the parameters concerning kernel PCA and
CPD algorithms have been carefully estimated through linear
searches.
4.1. Simulated Experiment. In this section we illustrate the
performances of the proposed approach by means of a
numerical example proposed in [25]. The goal of these
experiments is to study the case in which some of the hidden
states of the CHMM are not known in advance, but they
appear during the normal functioning of the system.
To better illustrate the effectiveness of the proposed
methodology we compare it to method of Lee et al. [25],
denoted here after as modified HMM approach. Moreover, we
evaluate the results according to two criteria:
(i) the classification accuracy, defined as the percentage
of states correctly classified by the Viterbi algorithm
with respect to the true known state sequence,
(ii) the detection time, defined as the moment in time in
which the unknown state is detected.
4.1.1. Data Generation. A training set composed of 5 histories
from a 4-state CHMM has been generated. Supposing that
two signals (𝑋1 and 𝑋2) are monitored, the observation
density follows a two-jointly Gaussian distribution. The
CHMM parameters used to generate the training data are as
follows:
𝜋 =
[
[
[
[
1
0
0
0
]
]
]
]
, 𝐴 =
[
[
[
[
0.99 0.01 0 0
0 0.99 0.01 0
0 0 0.99 0.01
0 0 0 1
]
]
]
]
,
𝜇1 = [
20
20
] , 𝜇2 = [
20
35
] ,
𝜇3 = [
35
35
] , 𝜇4 = [
35
20
] ,
𝑈1 = [
20 0
0 20
] , 𝑈2 = [
15 0
0 15
] ,
𝑈3 = [
15 −2
−2 15
] , 𝑈4 = [
5 0
0 5
] .
(22)
For each history, 500 data points have been sampled.
One possible example of observable signals is illustrated in
Figure 3.
To evaluate the behavior of the proposed methodology
under the presence of an unknown situation, we sampled
the testing case using a CHMM with 5 states: for the first 4
states we used the same parameters as the training set, while
a fifth (previously unknown) state has been added, with the
following parameters:
𝜇5 = [
50
50
] , 𝑈5 = [
10 3
3 10
] . (23)
By knowing beforehand the true states sequence of the
testing case as well as the the switch time to the fifth state
(time 511), in the following we compare the classification
accuracy and the unknown state detection time obtained by
our method and by the modified HMM of Lee et al. [25].](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-7-320.jpg)
![8 Advances in Mechanical Engineering
5 10 15 20 25 30 35 40 45 50
5
10
15
20
25
30
35
40
45
50
Signal X1
SignalX2
State S1
State S2
State S3
State S4
Figure 3: Scatter plot of the first simulated case. For the artificial
experiment, 500 observation samples from a 4-state CHMM with
2 monitored signals (𝑋1 and 𝑋2, following a 2-joint Gaussian
observation distribution) have been sampled for 5 histories.
4.1.2. Proposed Approach. For each training history, we
applied kernel PCA, using a Gaussian kernel with variance
which is equal to 1, in order to reduce the 2-dimensional
observation to a 1-dimensional signal. An example of dimen-
sionality reduction is illustrated in Figure 4 for the first
training history.
The obtained 1-dimensional signals have been input to the
batch CPD algorithm to perform the initial states numbers
estimation. As shown in Figure 5, the 4 segments are correctly
detected. The selected parameters of the batch CPD algorithm
are as follows: a second degree polynomial fitting function
and a stability threshold 𝑠 = 0.01 (see equation (14)).
Once the initial number of segments is obtained, we
consider a 𝑁∗
= 4-state left-right CHMM model for which
the parameter 𝜆 has to be estimated using the Baum-Welch
algorithm. To evaluate the efficiency of the proposed initial
parameters estimation approach, we performed 11 runs of the
Baum-Welch algorithm using as initial values the estimated
𝜆0 as described in Section 3.1 and 10 randomly set 𝜆0’s.
For these experiments, we selected a single Gaussian as
observation density of the CHMM and a maximum number
of 15 iterations.
Figure 6 shows that the learning procedure converges in
4 iterations when the initial parameters are set using the pro-
posed approach, compared to the randomly set parameters.
Moreover, the final likelihood value is comparable with the
best random initialization.
The 4-state CHMM trained model is then used to perform
the online condition assessment as described in Section 3.2.
For these experiments we employed the following parameters
for the online CPD algorithm: a first order polynomial fitting
function and a likelihood threshold 𝛿 = 0.4 (see equation
(15)).
As illustrated in Figure 7(d), until time 522, the trained
4-state CHMM has been used, and the Viterbi path correctly
assesses the four states. At time 512 (denoted by the last cross
in Figure 7(c)), the online CPD detects a further state. After
10 more data have been acquired, the CHMM is enriched with
a new state, and the training procedure is executed again to
estimate the paramters of a 5-state CHMM. From the time
point 522 on, the new 5-state CHMM is used, for which the
Viterbi path correctly assesses the fifth state until the end of
the experiment. The accuracy achieved by the Viterbi path is
97.23% of correctly classified states in the sequence.
4.1.3. Modified HMM Approach [25]. The results above have
been compared to the ones using the approach of Lee et al.
[25] that, in contrast to the proposed methodology which
employs data mining and curve fitting techniques, is based
on multivariate statistical tests.
The detection of a new state is performed by evaluating
a statistically significant shift in the mean of the observation
signal using the hotelling multivariate control chart (referred
to as hotelling MCC as follows). Hotelling MCC considers
as measure of similarity the Mahalanobis distance, denoted
as 𝐷2
(O, 𝜇𝑖), between the empirical mean O of the last
𝑏 observations (set to 10 in our experiments) and the 𝜇𝑖
parameter relative to the state 𝑖, which is the most probable
state given by the Viterbi path:
𝐷2
(O, 𝜇𝑖) = 𝑏 (O − 𝜇𝑖)
𝑇
U−1
𝑖 (O − 𝜇𝑖) , (24)
where U𝑖 is the covariance matrix relative to the most
probable state 𝑖. If this statistic exceeds a certain threshold,
called upper control limit (UCL), for more than 𝑅 consecutive
times, then a significant change is assumed in the process
and a new state is added. 𝑅 can be seen as a measure of the
detection sensitivity of the algorithm, if 𝑅 is increased, the
detection algorithm may become more robust against false
detections caused by the process randomness itself; on the
other hand, the algorithm may respond more slowly to the
unknown state.
Concerning the UCL, since 𝜇𝑖 and U𝑖 are known, the 𝐷2
statistic follows the 𝜒2
distribution with 𝑝 degrees of freedom,
where 𝑝 is the number of multivariates, that is, the number
of features considered as observations. Thus, the UCL can be
obtained as UCL = 𝜒2
𝛼,𝑝, where 𝛼 is the risk level.
An example of the Lee et al. [25] approach with 𝑅 =
3 is illustrated in Figure 8. A zoom of Figure 8(c), which
represents the Mahalanobis distance, is presented in Figure 9.
Here it is more clear that, after the three points exceeding the
UCL (denoted by out of control) have been detected and the
new state is added to the HMM, the Mahalanobis distance
comes back again under control.
Table 1 summarizes the classification accuracy (percent-
age of states correctly classified by the Viterbi algorithm) and
the detection time of the new state (knowing that the switch to
state 5 happened at time 511 in the ground truth data), for both
our proposed approach and the one of [25]. The classification
accuracy of the Lee et al. [25] method clearly depends on the
choice of the parameter 𝑅: if it is increased, the detection](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-8-320.jpg)
![Advances in Mechanical Engineering 9
0 500
0
3
Sample
−3
Signal X1
(a) Signal 𝑋1 versus time
0 500
0
3
Sample
−3
Signal X2
(b) Signal 𝑋2 versus time
0 500
0
1
Sample
KPCA
−1
(c) Dimensionality reduction with KPCA
Figure 4: Dimensionality reduction with KPCA. The information available in the two-dimensional signal shown in plots (a) and (b) is
combined in a single signal shown in plot (c) using KPCA. This transformation keeps information related to changes in the original signals.
0 500
0
0.6
Samples
KPCA
1-dimensional signal
Change-points
−0.6
(a) Offline CPD on training history #1
0 500
0
0.6
Samples
KPCA
1-dimensional signal
Change-points
−0.6
(b) Offline CPD on training history #2
Figure 5: Initial states number estimation with batch CPD. The 4 segments associated with the 4 CHMM states are correctly detected.
algorithm may become more robust against false detections
caused by the process randomness itself; on the other hand,
the algorithm may respond more slowly to the unknown state.
4.1.4. Discussion. From the obtained results we can conclude
that the proposed method
(i) is effective in estimating correctly the initial number
of HMM states as well as the initial parameters;
(ii) improves the convergency speed of the learning algo-
rithm;
(iii) outperforms the Lee et al. [25] approach in terms
of classification accuracy and earlier detection of the
new condition.
4.2. Real Data. In this section we describe the application
of our approach to a real case study. With the aim of
investigating the case in which a failure condition is unknown
during the training phase, we consider bearing monitoring
data taken from the NASA benchmark repository [42], which
have been used in several other works [37, 43–45]. As the
available data set does not contain any explicit information
about the bearing conditions, we use the detection time of the
Table 1: Comparison of the classification accuracy and detection
time (real new state switch time = 511).
𝑅 Accuracy Detection time
Proposed method 97.23% 512
Hotelling MCC 2 96.31% 531
Hotelling MCC 3 95.23% 541
Hotelling MCC 4 93.69% 551
failure state as a measure of model performance. In addition,
we evaluate the reliability of the proposed CPD methodology,
for the identification of the initial number of system’s states,
compared to clustering techniques and the Dunn’s Cluster
Validity Indexes [28]. Moreover, similarly to the simulated
experiment, we compare our approach with the one of Lee
et al. [25].
4.2.1. Data Description. The NASA benchmark repository
[42] contains monitoring measurements collected during
several run-to-failure tests performed on bearings under
constant load conditions on a special designed test rig (see
Figure 10). Four (4) bearings (bearing-1,. . .,bearing-4) were
installed on a rotating shaft and the test has been performed](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-9-320.jpg)
![10 Advances in Mechanical Engineering
0 5 10 15
Iterations
Loglikelihood
Proposed initialization
−2
−1.9
−1.8
−1.7
−1.6
−1.5
−1.4
−1.3
×104
(a) Learning curves
1 2 3 4 5 6 7 8 9 10 11
0
Loglikelihood
Initializations
Random initializations
Proposed initialization
−15000
−10000
−5000
(b) Final loglikelihood ranking
1 2 3 4 5 6 7 8 9 10 11
0
5
10
15
Numberofiterations
Initializations
Random initializations
Proposed initialization
(c) Number of iterations
Figure 6: Training Evaluation, the proposed 𝜆0 estimation versus 10 randomly set 𝜆0. By using the proposed approach for parameters
initialization the Baum-Welch algorithm converges after only 4 iterations (the fastest in this comparison) and the final likelihood value is
comparable with the best random initialization.
by keeping a constant rotation speed of 2000 rpm, while a
radial load of 6000 lbs has been added to the shaft and bearing
by a spring mechanism.
All the bearings are forcedly lubricated and the failure of
a bearing is detected by means of a magnetic plug installed
in the oil feedback pipe, that collects debris from the oil
as evidence of bearing degradation. When the accumulated
debris adhered to the magnetic plug exceeds a certain level,
causing an electrical switch to close, a failure of at least one of
the four bearings is assumed and the test stops [36].
The dataset consists of vibration signals collected by
means of accelerometers. On each bearing housing, two
accelerometers have been installed (one on the vertical 𝑌-
axis and one on the horizontal 𝑋-axis) for a total of 8
accelerometers (see Figure 10).
Three run-to-failure tests, test-1 to test-3, have been
performed on the test rig. One-second snapshot data were
collected at a sampling rate of 20 kHz (20480 samples for each
snapshot) every 20 minutes for test-1 and every 10 minutes
for test-2 and test-3. At the end of the first run-to-failure
experiment a crack was found near the shoulder of bearing-3,
while test-2 and test-3 ended up with an outer race defect in
bearing-1 and bearing-3, respectively (see Figure 11).
In our experiments we considered as training set 4
histories of bearings that did not experience failure (channels
𝑋 and 𝑌 of the first and the second bearing in test-1), and for
testing we used the history of a bearing that ended with failure
(the third in test-1).
The raw data of the training set have been preprocessed
by extracting three time-domain features: mean, root mean
square (RMS), and kurtosis within windows of length 𝐿 =
20480, which is, for simplicity, the same length of the given
snapshots. Figure 12 shows the raw vibration data and the
resulting RMS signal of length 2156.](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-10-320.jpg)
![Advances in Mechanical Engineering 11
0 100 200 300 400 500 600 700
0
20
40
60
Sample
SignalX1
(a) Testing signal: observation 1
0 100 200 300 400 500 600 700
0
20
40
60
Sample
SignalX2
(b) Testing signal: observation 2
0 100 200 300 400 500 600 700
0
0.5
1
KPCA
Sample
−1
−0.5
1-dimensional signal
Change-points
Detection time
(c) Online change point detection
0 100 200 300 400 500 600 700
1
2
3
4
5
States
Sample
(d) Viterbi path
Figure 7: Online condition assessment using the online CPD algorithm on the testing case. At time 512 the online CPD algorithm detects a
further state, which is added to the original 4-state CHMM. From time 522 on, the fifth state, which was unknown during the training phase,
is correctly assessed by the Viterbi algorithm.
0 100 200 300 400 500 600 700
0
20
40
60
Sample
SignalX1
(a) Testing signal: observation 1
0 100 200 300 400 500 600 700
0
20
40
60
Sample
SignalX2
(b) Testing signal: observation 2
0 100 200 300 400 500 600 700
Mahalanobis
distance
Sample
Under control
100
Out of control
UCL = 13.81 (𝛼 = 0.001)
(c) Hotelling multivariate control chart
0 100 200 300 400 500 600 700
1
2
4
3
5
States
Sample
(d) Viterbi path
Figure 8: Online condition assessment using the hotelling multivariate control chart. After 𝑅 = 3 consecutive times that the Mahalanobis
distance exceeds the upper control limit, an unknown situation is assumed and the fifth state is added to the CHMM.
4.2.2. Proposed Methodology Results. We applied KPCA, with
a Gaussian kernel of variance which is equal to 5, to the fea-
ture signals. The obtained 1-dimentional signal is illustrated
in Figure 13. As it can be seen, the obtained 1-dimensional
signal carries the relevant information contained in the three
extracted features (mean, RMS, and kurtosis).
We then applied the batch CPD algorithm (with a
polynomial degree of the fitting function which is equal to
1 and a stability threshold 𝑠 = 0.03) on the 1-dimensional
signal, resulting in the detection of 2 states, as illustrated in
Figure 14.
Since no explicit ground truth about the number of (bear-
ings) states has been made available in the benchmark data
[42], we propose using a clustering approach to estimate it. K-
means clustering, with varying number of clusters from 2 to
10, has been applied on the (historical) 3-dimensional features
observations. The generalized Dunn’s validity indexes [28]
have been used to determine the optimal number of clusters
corresponding to the number of bearing states. Figure 15
illustrates 5 of the 18 validity indexes (𝑉11, . . . , 𝑉51) of [28]
versus the number of clusters. High index values indicate
the optimal number of clusters, in this case 2. These results
confirm that the proposed CPD algorithm applied to the
1-dimensional signal obtained after KPCA dimensionality
reduction produces the correct number of bearing states.
For the next steps of bearing condition assessment, a
2-state CHMM is considered, for which, as illustrated in
Figure 16, the proposed CHMM parameters initialization
improves the convergence speed with a final likelihood com-
pared to the value obtained by the best random initialization.](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-11-320.jpg)
![12 Advances in Mechanical Engineering
0 10 20 30 40 50 60 70
Mahalanobisdistance
Under control
Out of control State change
10−3
10−2
10−1
100
101
102
103
104
Number of sample (sample size = 10)
UCL = 13.81 (𝛼 = 0.001)
Figure 9: The hotelling multivariate control chart for testing data. After the three points out of control have been detected and the new state
is added to the CHMM, the Mahalanobis distance comes back again under control.
Accelerometers
Radial load
Thermocouples
Motor
Bearing-1 Bearing-2 Bearing-3 Bearing-4
Figure 10: Testing rig and sensors positions [36]. The 4 bearings installed on a rotating shaft under a constant load and kept at a constant
rotation speed for 3 run-to-failure tests. The measurements available are collected by means of 2 accelerometers installed in each bearing case
(one on the vertical axis and one on the horizontal axis) for a total of 8 accelerometers.
(a) (b) (c)
Figure 11: Damaged bearings [36]. At the end of the first test the bearing-3 experienced a crack near the shoulder (a), while at the end of the
second and the third test an outer race defect occurred in bearing-1 (b) and bearing-3 (c), respectively.](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-12-320.jpg)
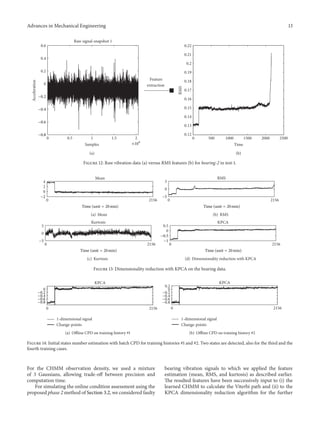
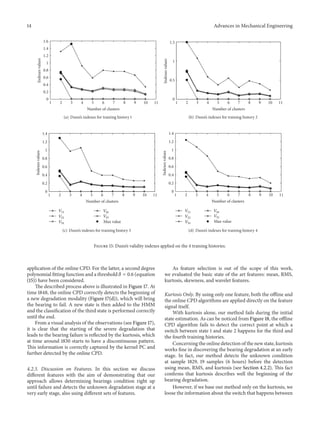
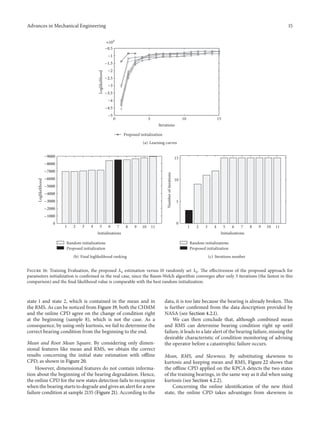
![16 Advances in Mechanical Engineering
0 2156
0
20
40
Mean
−20
(a) Testing signal: observation 1
0 2156
0
10
20
RMS
−10
(b) Testing signal: observation 2
0 2156
0
5
10
15
Kurtosis
−5
(c) Testing signal: observation 3
0 1848 2156
0
0.5
1
KPCA
1-dimensional signal
Change-points
Detection time
(d) Online change point detection
0 1848 2156
1
2
3
States
(e) Viterbi path
Figure 17: Online condition assessment using the proposed approach. The beginning of a new degradation modality is detected by the online
CPD algorithm at an early stage (time 1848), which allowed augmenting the CHMM with a new state. The augmented CHMM correctly
detects the degraded state of the bearing (Viterbi path).
0
0
2
4
Change-points
2156
Kurtosis
1-dimensional signal
−2
(a) Offline CPD on training history #3
0 2156
0
2
4
Kurtosis
1-dimensional signal
Change-points
−2
(b) Offline CPD on training history #4
Figure 18: Initial states number estimation with batch CPD for training histories #3 and #4 based on kurtosis only. The method fails to detect
the correct moment in which the state change occurs.
terms of earlier detection of the bearing degradation and
slightly outperforms the results obtained in Section 4.2.2. In
fact, it detects the third state at sample 1824, 8 hours before.
However, as shown in Figure 23, the Viterbi path of
the CHMM fails in detecting the correct state at the end.
Hence, we can conclude that, despite the earlier detection of
the bearing degradation, the configuration mean, RMS, and
skewness is not appropriate to determine bearing condition
right up until failure.
Wavelet Packet Transform. Finally, we tried our method on
time-frequency domain features extracted using the wavelet
packet transform (WPT). As described in the work of Pandya
et al. [46], we combined the energy and the kurtosis of wavelet
coefficients at the second level of the wavelet tree.
Figure 24 shows that offline CPD works fine in detecting
the two states of the training bearings, while Figure 25 shows
that our methodology detects the new bearing degradation
state at sample 1831 when applied on time-frequency features,
performing slightly better (around 5 hours earlier detection)
than when mean, RMS, and kurtosis are used.
From the feature study, one can conclude that the pro-
posed mean, RMS, and kurtosis features give good results
for condition monitoring of bearings. However, an extended](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-16-320.jpg)


![Advances in Mechanical Engineering 19
0 2156
0
10
20
30
WPT-coefficient 1 energy
−10
(a) Testing signal: observation 1
0 2156
0
10
20
30
WPT-coefficient 2 energy
−10
(b) Testing signal: observation 2
0 2156
0
5
10
15
WPT-coefficient 1 kurtosis
−5
(c) Testing signal: observation 3
0 2156
0
10
20
30
WPT-coefficient 2 kurtosis
−10
(d) Testing signal: observation 4
0 1831 2156
0
0.2
0.4
0.6
KPCA
1-dimensional signal
Change-points
Detection time
−0.4
−0.2
(e) Online change point detection
0 1831 2156
1
2
3
States
(f) Viterbi path
Figure 25: Online condition assessment using the proposed approach on the energy and the kurtosis of WPT tree’s second level coefficients.
The results obtained with the proposed time domain features are confirmed by using time-frequency domain features.
0 2156
0
20
40
Mean
−20
(a) Testing signal: observation 1
0 2156
0
10
20
RMS
−10
(b) Testing signal: observation 2
0 2156
0
5
10
15
Kurtosis
−5
(c) Testing signal: observation 3
0 2061
Mahalanobis distance
Under control
Out of control
10−10
10−5
100
105
UCL = 16.27 (𝛼 = 0.001)
(d) Hotelling multivariate control chart
0 2061
1
2
3
States
(e) Viterbi path
Figure 26: Online condition assessment using the hotelling multivariate control chart of [25]. The detection of the degradation modality
occurs at time 2061 (71 hours later than the proposed approach).](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-19-320.jpg)
![20 Advances in Mechanical Engineering
0 206
Mahalanobis distance
Under control
Out of control State change
Number of sample (sample size = 10)
10−1
100
101
102
103
104
UCL = 16.26 (𝛼 = 0.001)
Figure 27: The hotelling multivariate control chart for testing data.
The observations modeling through a joint Gaussian distribution is
highly sensitive to small differences between the mean of the testing
and the training observation signals. Due to this small difference,
several out of control points are observed at the beginning, that
would have wrongly brought the method to detect an unknown
situation.
analysis of feature extraction and selection should be made
depending on the problem in hand and on the used sensors.
4.2.4. Modified HMM Results. Figure 26 illustrates the
approach of Lee et al. [25], in which the detection sensitivity
parameter 𝑅 has been set as 𝑅 = 6. As it can be seen, the
detection of the unknown condition happens at time 2061.
Figure 27, which represents the Mahalanobis distance
versus number of sample, illustrates the limits of the approach
and its observations modeling, being a joint Gaussian distri-
bution and not a mixture of Gaussians. Hotelling MCC is in
fact highly sensitive to small differences between the mean
of the testing and the training observation signals. Hence, it
is applicable only when training and testing observations are
very similar. As demonstrated by the first part of Figure 27,
where there are several points out of control at the beginning
because the mean of the testing signals in this portion is
slightly different from the training set. Although such method
would have wrongly detected an unknown situation (a new
state would), it has been forced to avoid this behavior by
adjusting the parameter 𝑅.
4.2.5. Discussion. The above results highlight that the pro-
posed methodology
(i) overcomes the limitations imposed by the hotelling
MCC since a complex density can be used to model
the observations;
(ii) is parametric-free; the only parameters are the thresh-
olds of the CPD algorithms, which could be set
according to the sensor measurements during the
training phase;
(iii) is effective in detecting failure modalities at an early
stage.
5. Conclusion and Future Work
In this paper, a new approach to the online adaptive condition
monitoring has been introduced. The methodology is based
on continuous observation hidden Markov models that,
combined with the change point detection algorithm, are
enhanced to deal with variable state space and are used for
condition assessment and unknown state detection. More-
over, a new approach for the HMM initial states number
estimation has been provided, together with a method for the
parameters initialization. The obtained results illustrate that
the proposed methodology (1) correctly estimates the initial
number of states for the HMM; (2) improves the execution
speed of the training procedure in terms of iterations number
reduction with a final likelihood comparable with the best
random initialization; (3) classify the current state of the
system more effectively than the modified HMM coupled
with the hotelling multivariate control chart; (4) detects an
anomalous condition or an unknown state at an early stage;
and (5) changes the structure and the parameters of the HMM
to adapt the model to the new situations.
Our approach has been implemented in Matlab (version
8.3.0), under Windows 7 Enterprise 64-bit Operating System
on a desktop computer with an Intel Core i7 3.07 GHz CPU
and 16 GB RAM. In terms of computational cost, phase 1,
that is, the training phase, takes 296 seconds to learn the
CHMM parameters from historical data. It has to be noted
that this phase is applied only once for a given machine.
Phase 2, that is, the online adaptive condition assessment,
takes, on average, 0.2 seconds each time a new snapshot
of data is collected (20480 samples). As a consequence, the
algorithm can be used in real time condition assessment.
In terms of hardware cost, a 164 kBytes buffer is used to
store the incoming data, while for the CHMM the memory
consumption is proportional to the model structure. In
general terms, (𝑁 − 1) + (𝑁 − 1) ⋅ 𝑁 + 𝐷 ⋅ 𝑁 ⋅ 𝑀 + 𝐷 ⋅ 𝐷 ⋅ 𝑁 ⋅
𝑀 + (𝑀 − 1) ⋅ 𝑁 double-precision memory is required, with
𝑁 the number of states, 𝑀 the number of Gaussian mixtures
in the observation model, and 𝐷 the number of considered
features.
The present work highlights through experiments per-
formed on simulated and real data that the presented
methodology can be used in practice as a decision support
tool to corrective maintenance strategies. However, it has
some problems that must be considered. The dimensionality
reduction through kernel principal cmponent analysis causes
an inevitable loss of information in the signal used for the
change point detection algorithm. To avoid this problem,
future researches will consider the application of a modified
multidimensional CPD algorithm performed directly in the
features hyperplane. Moreover, by using left-right HMMs, it
has been assumed that the degradation pattern of the system
is characterized by a monotonically increasing evolution
which gradually crosses all the wearing phases until the
complete failure. Despite being reasonable for bearings, this
assumption does not hold for several real systems. In order
to render the methodology more generally applicable, it is
necessary to consider in future work a method which is able
to distinguish also intermediate states and to recognize if the](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-20-320.jpg)
![Advances in Mechanical Engineering 21
new detected state has been already encountered. Although
the present-time researches are oriented to clustering tech-
niques coupled with statistical similarity measures, other
methods will be taken into consideration, with the final goal
to use as degradation model the more general full ergodic
HMM.
Conflict of Interests
The authors declare that there is no conflict of interests
regarding the publication of this paper.
References
[1] T. Honkanen, Modelling industrial maintenance systems and the
effects of automatic condition monitoring [Ph.D. thesis], Helsinki
University of Technology, Information and Computer Systems
in Automation, Helsinki, Finland, 2004.
[2] R. Dekker, “Applications of maintenance optimization models:
a review and analysis,” Reliability Engineering & System Safety,
vol. 51, no. 3, pp. 229–240, 1996.
[3] L. Solomon, “Essential elements of maintenance improvement
programs,” in Production Control in the Process Industry: Pro-
duction Control in the Process Industry No 8: Proceedings of
the IFAC Workshop, Osaka, 29-31 and Kariya, Japan, 1-2 Nov.
1989 (Hardback), E. Oshima and C. van Rijn, Eds., pp. 195–198,
Pergamon Press, Oxford, UK, 1989.
[4] H. Wang, “A survey of maintenance policies of deteriorating
systems,” European Journal of Operational Research, vol. 139, no.
3, pp. 469–489, 2002.
[5] Y. Peng, M. Dong, and M. J. Zuo, “Current status of machine
prognostics in condition-based maintenance: a review,” The
International Journal of Advanced Manufacturing Technology,
vol. 50, no. 14, pp. 297–313, 2010.
[6] A. Sfetsos, “Short-term load forecasting with a hybrid clustering
algorithm,” IEE Proceedings: Communications, vol. 150, no. 3, pp.
257–262, 2003.
[7] R. Vilalta and M. Sheng, “Predicting rare events in temporal
domains,” in Proceedings of the 2nd IEEE International Confer-
ence on Data Mining (ICDM ’02), pp. 474–481, December 2002.
[8] C. Domeniconi, C.-S. Perng, R. Vilalta, and S. Ma, “A classi-
fication approach for prediction of target events in temporal
sequences,” in Proceedings of the 6th European Conference on
Principles of Data Mining and Knowledge Discovery (PKDD ’02),
pp. 125–137, Springer, London, UK, 2002.
[9] K. Medjaher, J.-Y. Moya, and N. Zerhouni, “Failure
prognostic by using dynamic Bayesian Networks,” in
Dependable Control of Discrete Systems, M. P. Fanti
and M. Dotoli, Eds., vol. 1, IFAC, Bari, Italy, 2009,
https://hal.archives-ouvertes.fr/hal-00402938/en/.
[10] P. Baruah and R. B. Chinnam, “HMMs for diagnostics and
prognostics in machining processes,” International Journal of
Production Research, vol. 43, no. 6, pp. 1275–1293, 2005.
[11] X. Zhang, R. Xu, C. Kwan, S. Y. Liang, Q. Xie, and L.
Haynes, “An integrated approach to bearing fault diagnostics
and prognostics,” in Proceedings of the IEEE American Control
Conference (ACC ’05), vol. 4, pp. 2750–2755, June 2005.
[12] Z. Li, Z. Wu, Y. He, and C. Fulei, “Hidden Markov model-
based fault diagnostics method in speed-up and speed-down
process for rotating machinery,” Mechanical Systems and Signal
Processing, vol. 19, no. 2, pp. 329–339, 2005.
[13] H. M. Ertunc, K. A. Loparo, and H. Ocak, “Tool wear condition
monitoring in drilling operations using hidden Markov models
(HMMs),” International Journal of Machine Tools and Manufac-
ture, vol. 41, no. 9, pp. 1363–1384, 2001.
[14] L. R. Rabiner, “A tutorial on hidden Markov models and selected
applications in speech recognition,” Proceedings of the IEEE, vol.
77, no. 2, pp. 257–286, 1989.
[15] N. Ye, Y. Zhang, and C. M. Borror, “Robustness of the Markov-
chain model for cyber-attack detection,” IEEE Transactions on
Reliability, vol. 53, no. 1, pp. 116–123, 2004.
[16] C. Bunks, D. McCarthy, and T. Al-Ani, “Condition-based main-
tenance of machines using hidden Markov models,” Mechanical
Systems and Signal Processing, vol. 14, no. 4, pp. 597–612, 2000.
[17] M. Bjerkeseth, Using hidden markov models for fault diagnostics
and prognostics in condition based maintenance systems [Ph.D.
dissertation], University of Agder, 2010.
[18] T. Liu, J. Chen, and G. Dong, “Application of continuous hide
markov model to bearing performance degradation assess-
ment,” in Proceedings of the 24th International Congress on
Condition Monitoring and Diagnostics Engineering Management
(COMADEM ’11), pp. 166–172, 2011.
[19] H. Ocak and K. A. Loparo, “A new bearing fault detection
and diagnosis scheme based on hidden Markov modeling
of vibration signals,” in Proceedings of the IEEE Interntional
Conference on Acoustics, Speech, and Signal Processing, pp. 3141–
3144, IEEE Computer Society, Washington, DC, USA, May
2001.
[20] G. Almeida and S. Park, “Process monitoring in chemical
industries—a hidden Markov model approach,” in Proceedings
of the 18th European Symposium on Computer Aided Process
Engineering (ESCAPE ’18), 2008.
[21] I. Strachan and D. Clifton, A Hidden Markov Model for Condi-
tion Monitoring of a Manufacturing Drilling Process, vol. 1, (IET)
Condition Monitoring, Dublin, Ireland, 2009.
[22] G. Almeida and S. Park, “Fault detection in continuous indus-
trial chemical processes: a new approach using the hidden
Markov modeling. Case study: a boiler from a Brazilian cellu-
lose pulp mill,” in Intelligent Data Engineering and Automated
Learning—IDEAL 2012, vol. 7435, pp. 743–752, Springer, Berlin,
Germany, 2012.
[23] T. Liu, J. Chen, X. N. Zhou, and W. B. Xiao, “Bearing per-
formance degradation assessment using linear discriminant
analysis and coupled HMM,” Journal of Physics: Conference
Series, vol. 364, no. 1, Article ID 012028, 2012.
[24] G. D. Forney Jr., “The Viterbi algorithm,” Proceedings of the
IEEE, vol. 61, pp. 268–278, 1973.
[25] S. Lee, L. Li, and J. Ni, “Online degradation assessment and
adaptive fault detection using modified hidden markov model,”
Journal of Manufacturing Science and Engineering, vol. 132, no.
2, Article ID 021010, 11 pages, 2010.
[26] F. Cartella, T. Liu, S. Meganck, J. Lemeire, and H. Sahli, “Online
adaptive learning of left-right continuous HMM for bearings
condition assessment,” Journal of Physics: Conference Series, vol.
364, no. 1, Article ID 012031, 2012.
[27] V. Guralnik and J. Srivastava, “Event detection from time
series data,” Proceedings of the 5th ACM SIGKDD International
Conference on Knowledge Discovery and Data Mining (KDD
’99), pp. 33–42, 1999.
[28] J. C. Bezdek and N. R. Pal, “Some new indexes of cluster
validity,” IEEE Transactions on Systems, Man, and Cybernetics
Part B: Cybernetics, vol. 28, no. 3, pp. 301–315, 1998.](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-21-320.jpg)
![22 Advances in Mechanical Engineering
[29] B. Sch¨olkopf, A. Smola, and K.-R. M¨uller, “Nonlinear compo-
nent analysis as a kernel eigenvalue problem,” Neural Computa-
tion, vol. 10, no. 5, pp. 1299–1319, 1998.
[30] S. Mika, B. Scholkopf, A. Smola, K. R. Muller, M. Scholz, and
G. Ratsch, “Kernel pca and de noising in feature spaces,” in
Advances in Neural Information Processing Systems, vol. 11, pp.
536–542, MIT Press, 1999.
[31] S. Romdhani, S. Gong, and A. Psarrou, “A multi-view nonlinear
active shape model using kernel pca,” in Proceedings of the
British Machine Vision Conference, pp. 483–492, 1999.
[32] P. O’Donnell, “Report of large motor reliability survey of indus-
trial and commercial installations, part II,” IEEE Transactions
on Industry Applications, vol. 21, no. 4, pp. 865–872, 1985.
[33] J. Q. Li and A. R. Barron, “Mixture density estimation,” in
Advances in Neural Information Processing Systems 12, pp. 279–
285, MIT Press, Cambridge, Mass, USA, 1999.
[34] A. P. Dempster, N. M. Laird, and D. B. Rubin, “Maximum
likelihood from incomplete data via the EM algorithm,” Journal
of the Royal Statistical Society B: Methodological, vol. 39, no. 1,
pp. 1–38, 1977.
[35] R. B. Randall, Frequency Analysis, Bruel and Kjaer, 1987.
[36] H. Qiu, J. Lee, J. Lin, and G. Yu, “Wavelet filter-based weak
signature detection method and its application on rolling
element bearing prognostics,” Journal of Sound and Vibration,
vol. 289, no. 4-5, pp. 1066–1090, 2006.
[37] D. A. Tobon-Mejia, K. Medjaher, N. Zerhouni, and G. Tripot,
“Estimation of the remaining useful life by using wavelet
packet decomposition and hmms,” in Proceedings of the IEEE
Aerospace Conference AIAA, pp. 1–10, IEEE Computer Society,
Los Alamitos, Calif, USA, 2011.
[38] P. Burge and J. Shaw-Taylor, “Detecting cellular fraud using
adaptive prototypes,” in Proceedings of the AI Approaches to
Fraud Detection and Risk Management, pp. 9–13, 1997.
[39] K. Yamanishi, J. Takeuchi, G. Williams, and P. Milne, “On-
line unsupervised outlier detection using finite mixtures with
discounting learning algorithms,” in Proceedings of the 6th ACM
SIGKDD International Conference on Knowledge Discovery and
Data Mining (KDD ’00), pp. 250–254, ACM Press, 2000.
[40] T. Fawcett and F. Provost, “Activity monitoring: noticing inter-
esting changes in behavior,” in Proceedings of the 5th ACM
SIGKDD International Conference on Knowledge Discovery and
Data Mining (KDD ’99), pp. 53–62, 1999.
[41] V. Cherkassky and F. Mulier, Learning from Data, Wiley-
Interscience, New York, NY, USA, 1998.
[42] NSF-I/UCRC, “Center for intelligent maintenance systems.
prognostic data repository: Bearing data set,” http://ti.arc.nasa
.gov/tech/dash/pcoe/prognostic-data-repository/.
[43] D. A. Tobon-Mejia, K. Medjaher, N. Zerhouni, and G. Tripot,
“A mix ture of gaussians hidden markov model for failure
diagnostic and prognostic,” in Proceedings of the 6th Annual
IEEE International Conference on Automation Science and
Engineering (CASE ’10), pp. 338–343, IEEE, August 2010.
[44] D. A. Tobon-Mejia, K. Medjaher, N. Zerhouni, and G. Tripot,
“Hidden Markov Models for failure diagnostic and prognostic,”
in Proceedings of the Prognostics and System Health Management
Conference (PHM-Shenzhen ’11), pp. 1–8, Shenzhen, China, May
2011.
[45] D. A. Tobon-Mejia, K. Medjaher, N. Zerhouni, and G. Tripot,
“A data-driven failure prognostics method based on mixture
of gaussians hidden markov models,” IEEE Transactions on
Reliability, vol. 61, no. 2, pp. 491–503, 2012.
[46] D. Pandya, S. Upadhyay, and S. P. Harsha, “Ann based fault
diagnosis of rolling element bearing using time-frequency
domain feature,” International Journal of Engineering Science
and Technology, vol. 4, pp. 2878–2886, 2012.](https://image.slidesharecdn.com/c7244ce0-aeee-4da1-9094-ea111b8815eb-150317201146-conversion-gate01/85/FCAME2014-22-320.jpg)


This document summarizes a research article that proposes using continuous hidden Markov models (CHMMs) with a change point detection algorithm for online adaptive bearings condition assessment. The approach aims to (1) estimate the initial number of CHMM states and parameters from historical data and (2) update the state space and parameters during monitoring to adapt to changes. Compared to existing techniques, the proposed approach improves HMM training, detects unknown states earlier, and better represents degradation processes with unknown conditions by changing the CHMM structure.
































































