Download to read offline


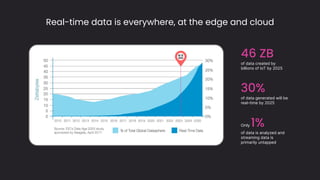

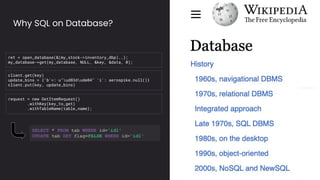


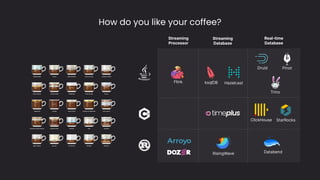

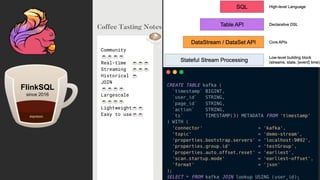
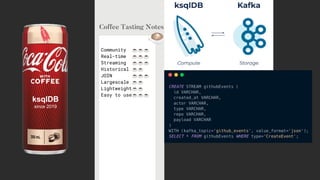
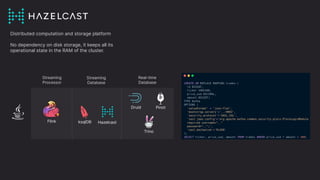

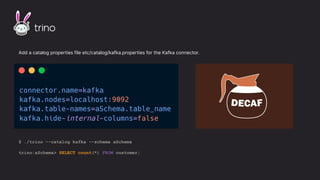

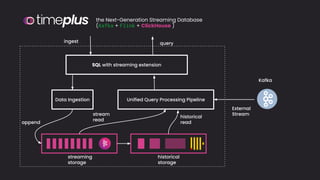
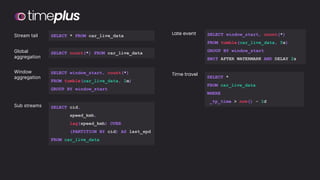
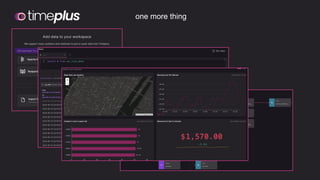
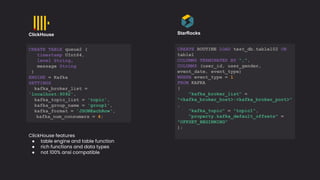

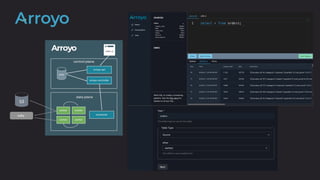
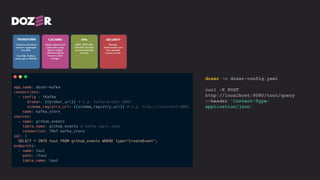
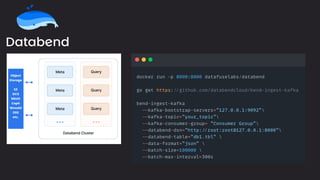
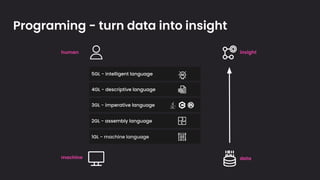





The document discusses the importance and benefits of using SQL on Kafka for real-time data analytics, emphasizing that only a small percentage of generated data is currently analyzed. It outlines various use cases across sectors such as fintech, DevOps, security, and IoT, highlighting the need for reliable and efficient data processing solutions. Additionally, it mentions several technologies and platforms that facilitate real-time data queries, including ClickHouse, Apache Flink, and Druid.



































































