Downloaded 79 times


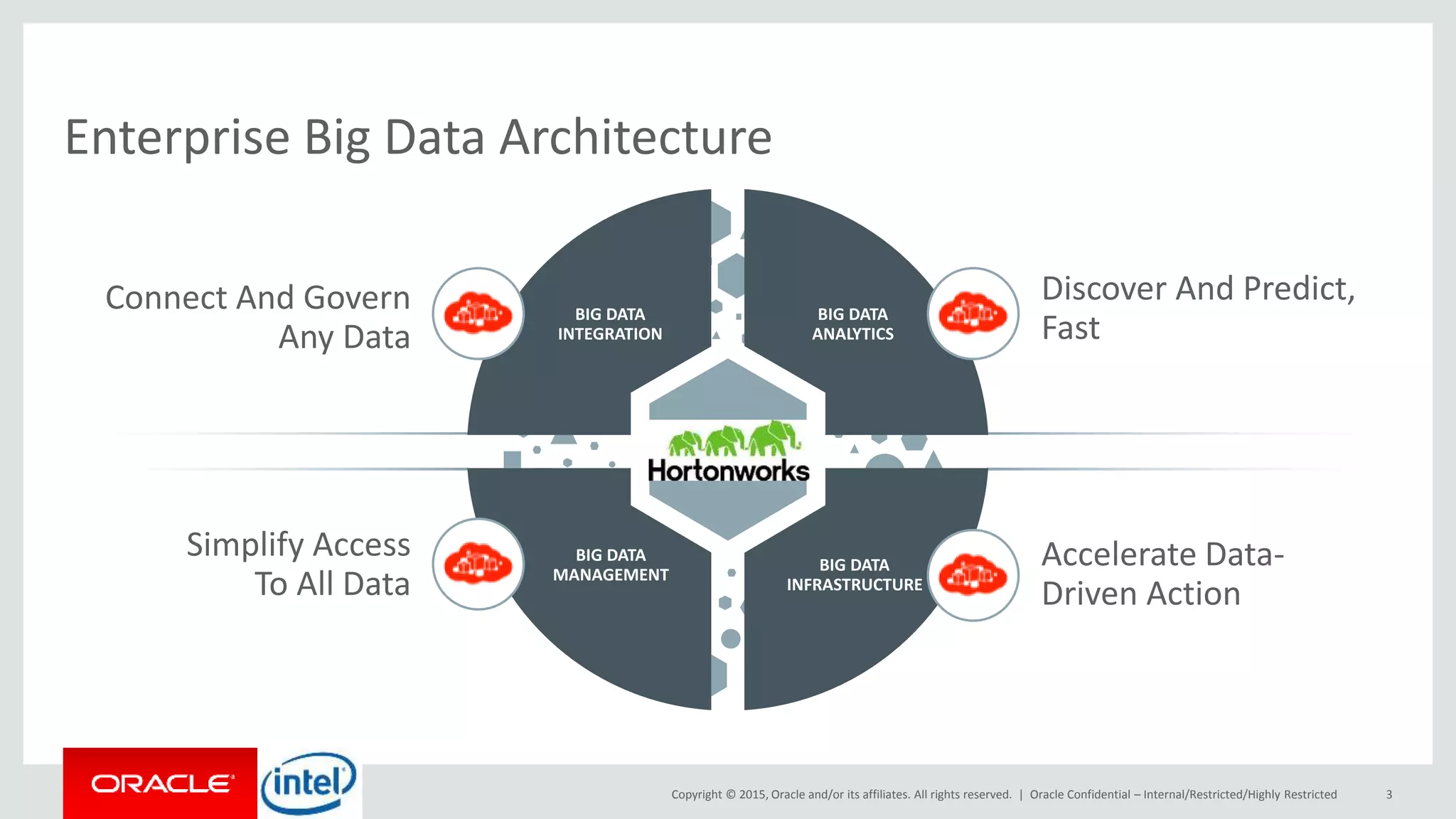
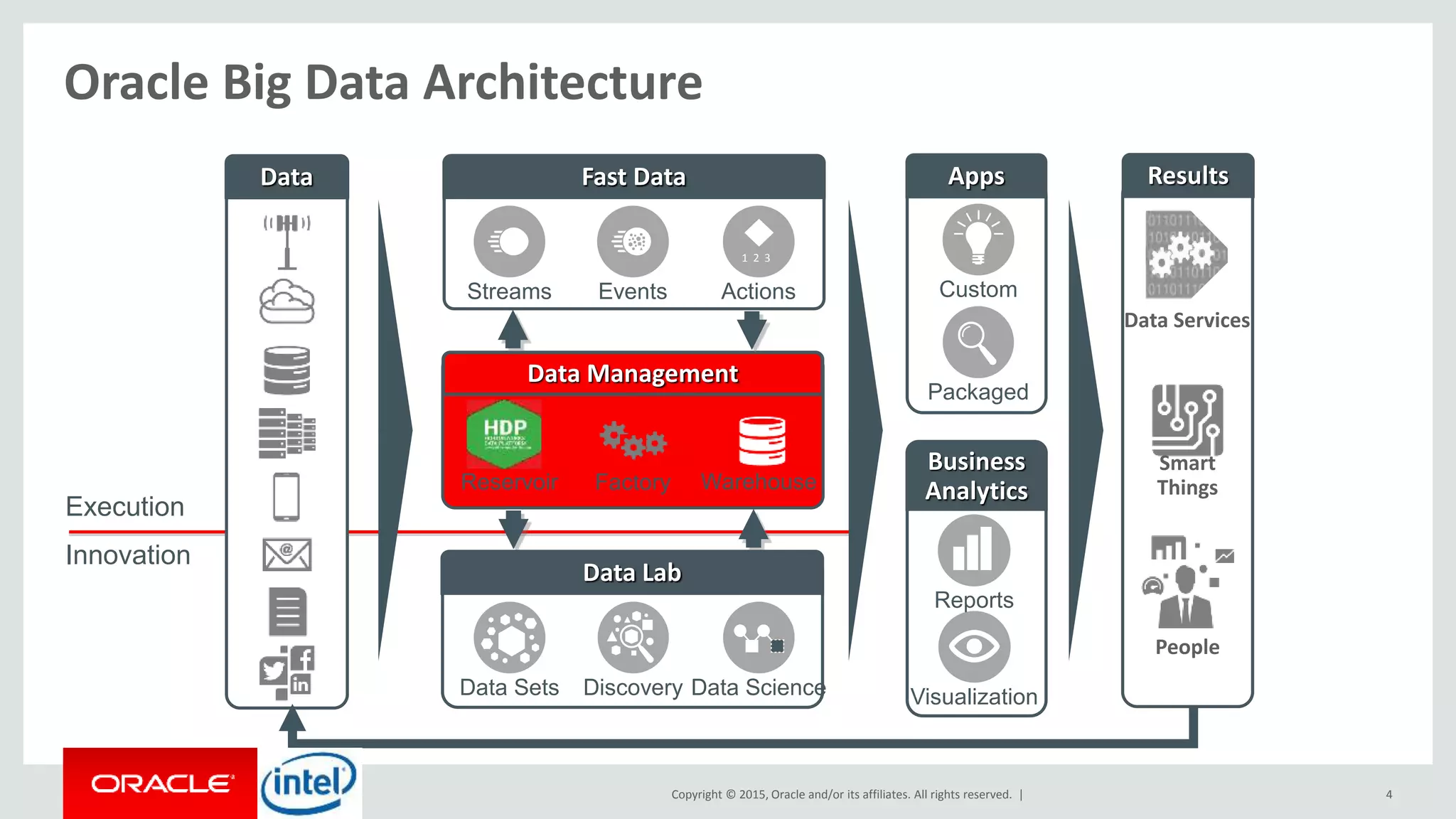
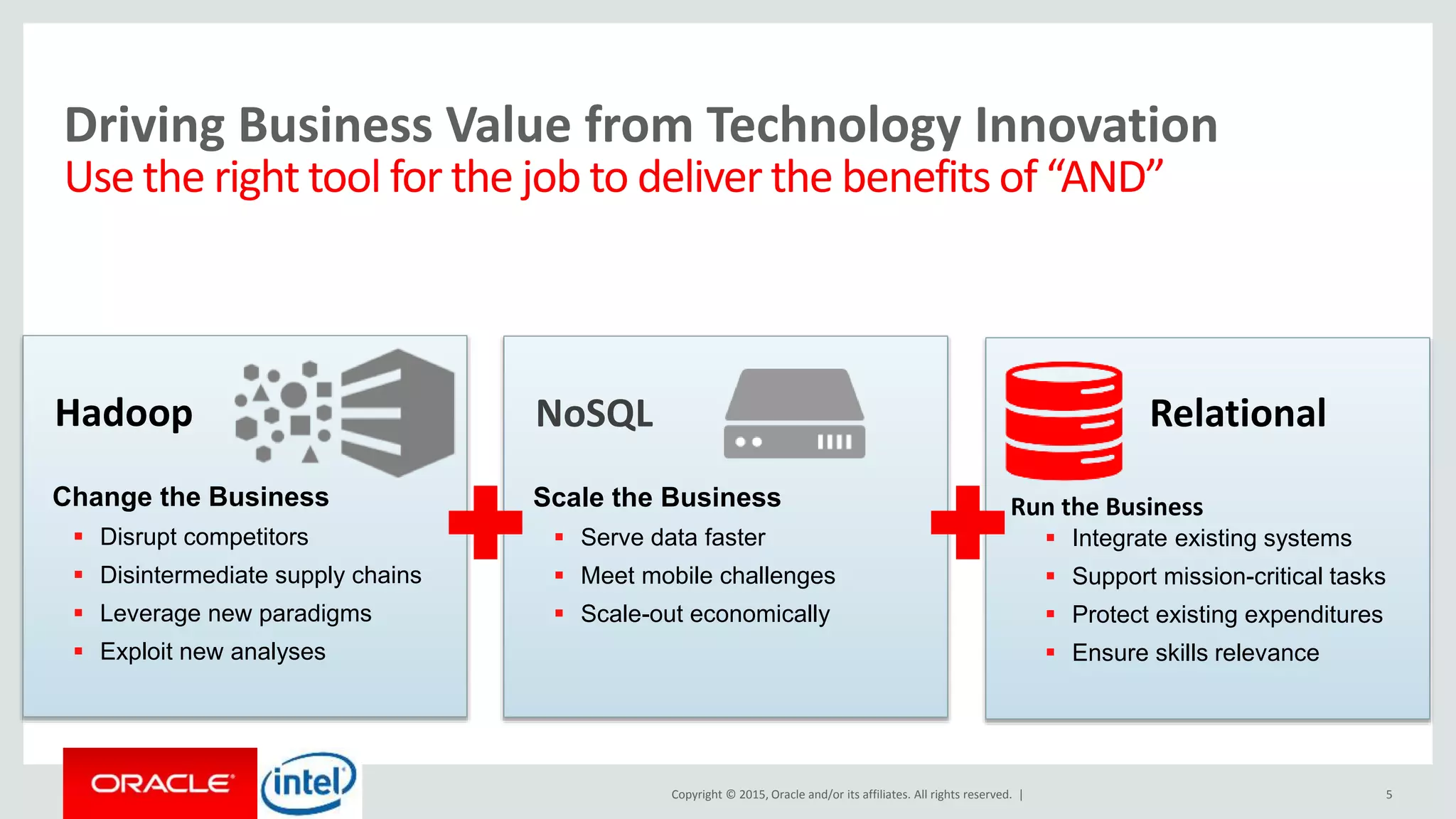
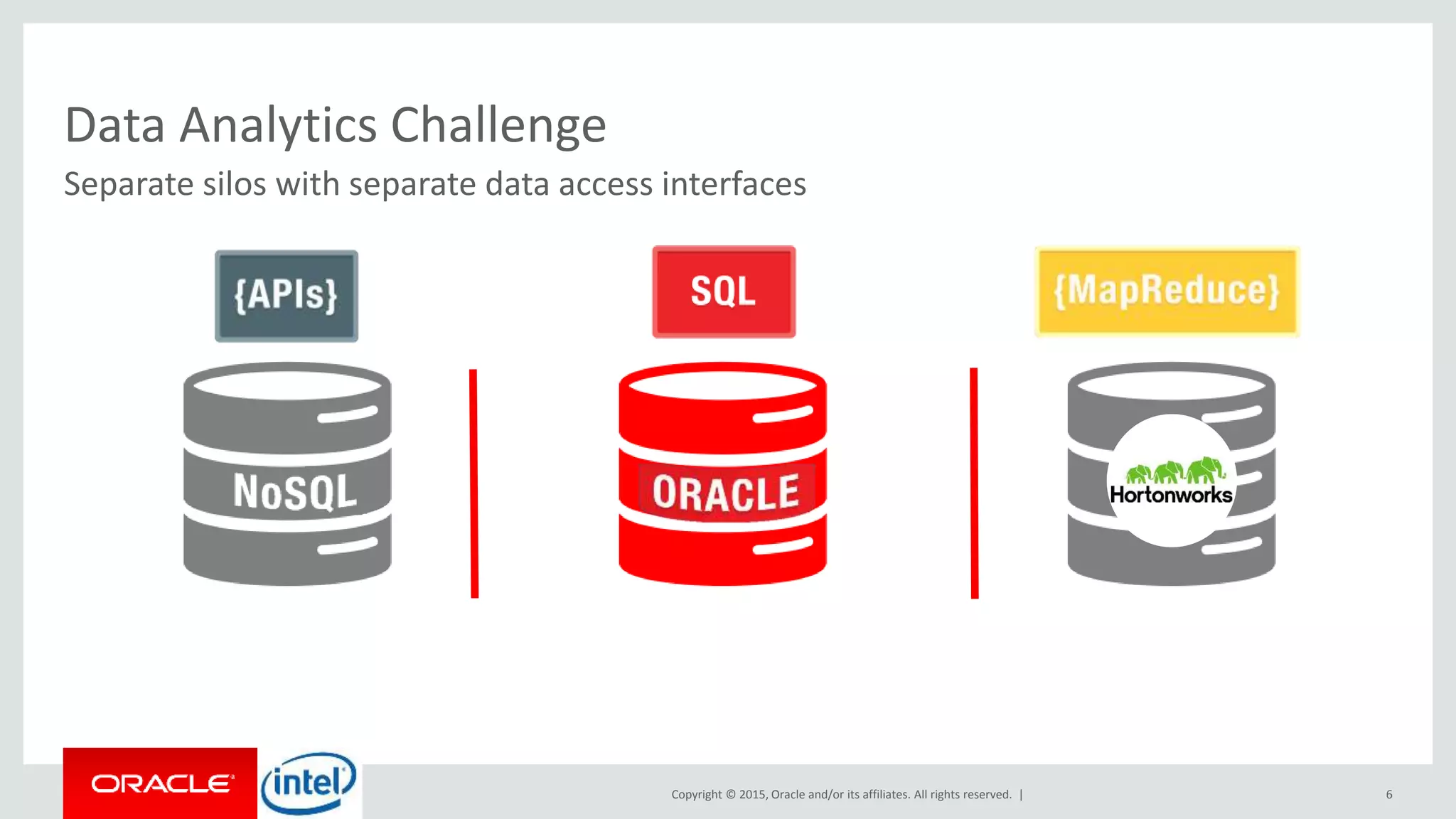
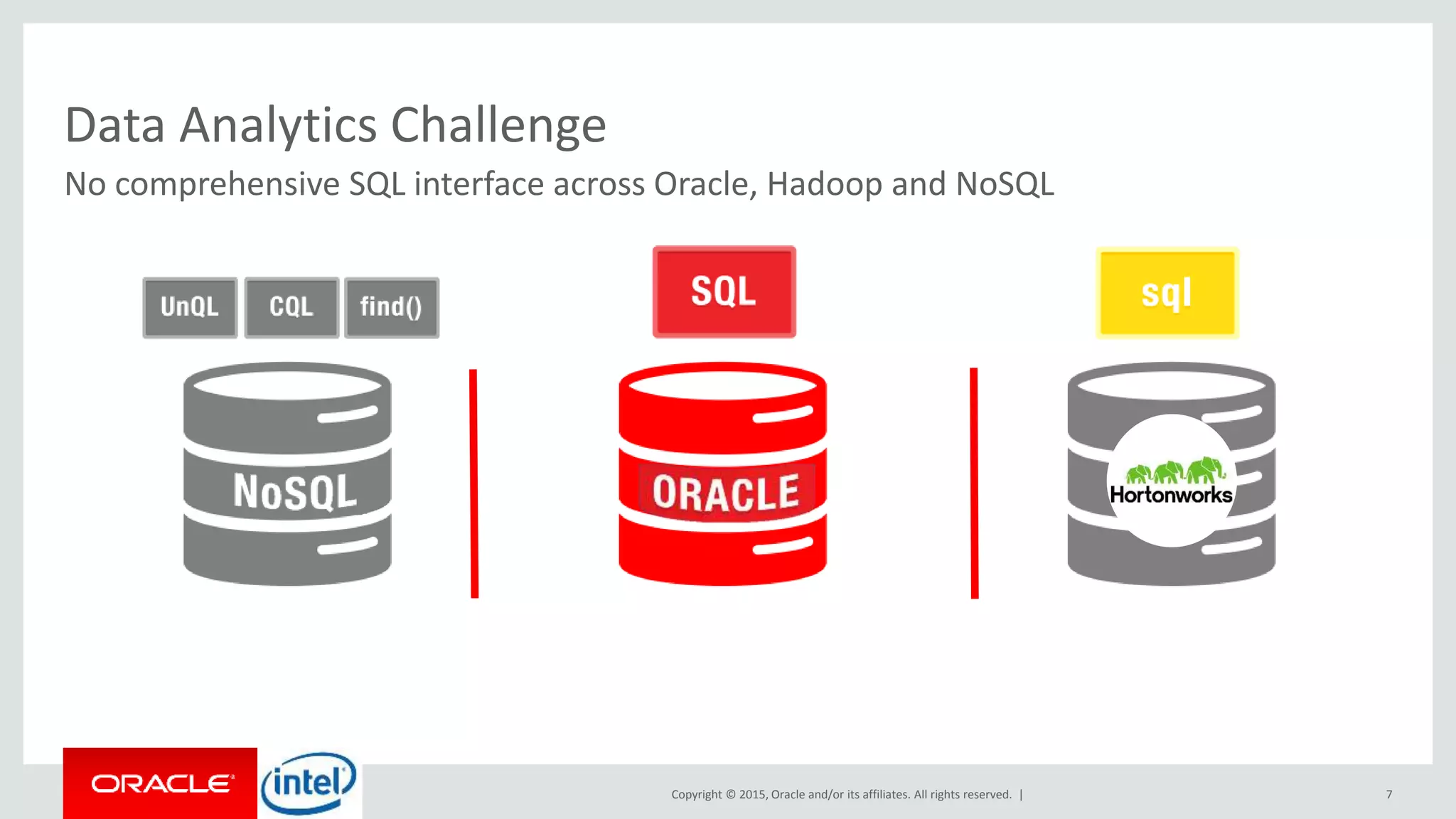
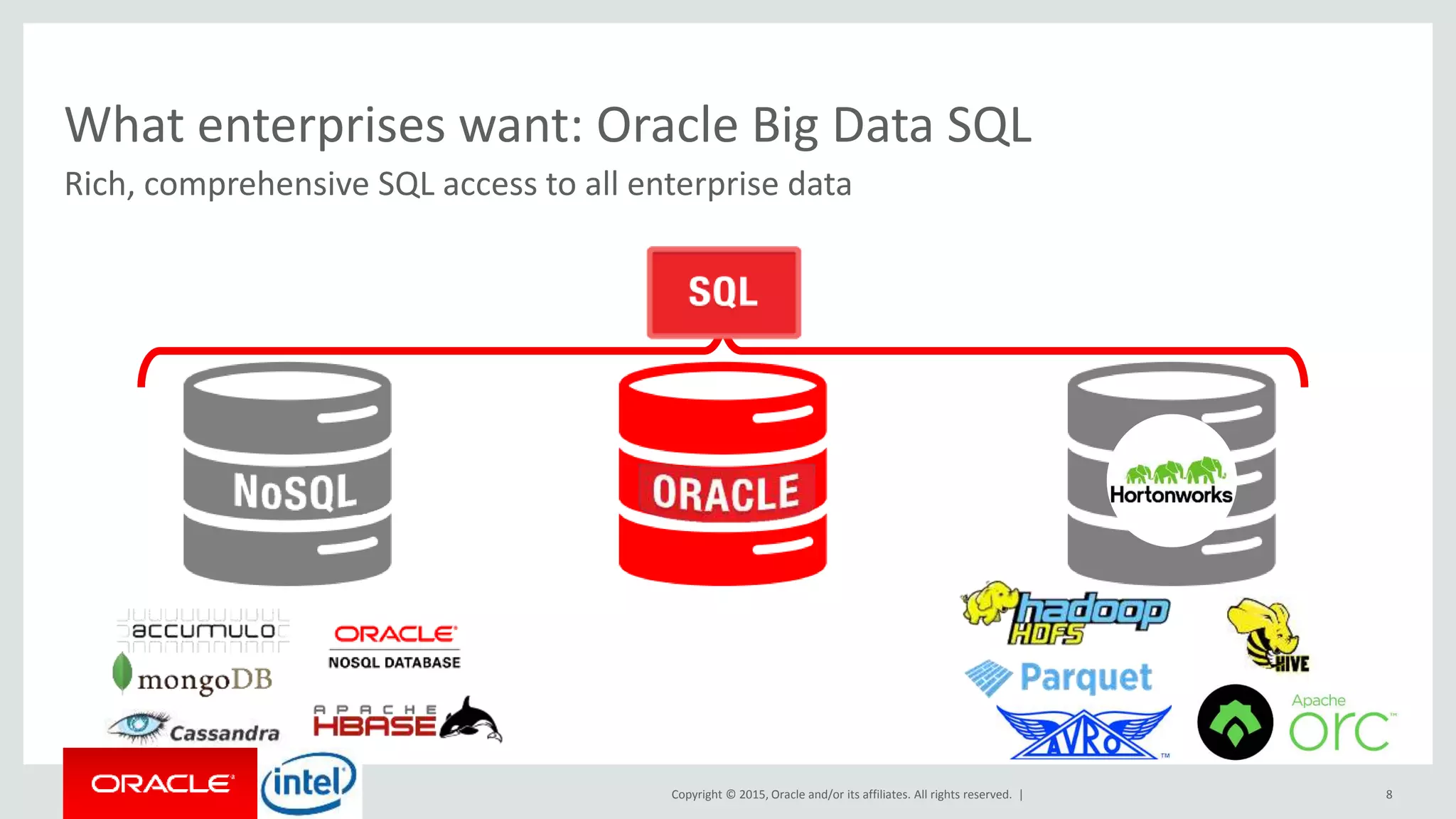
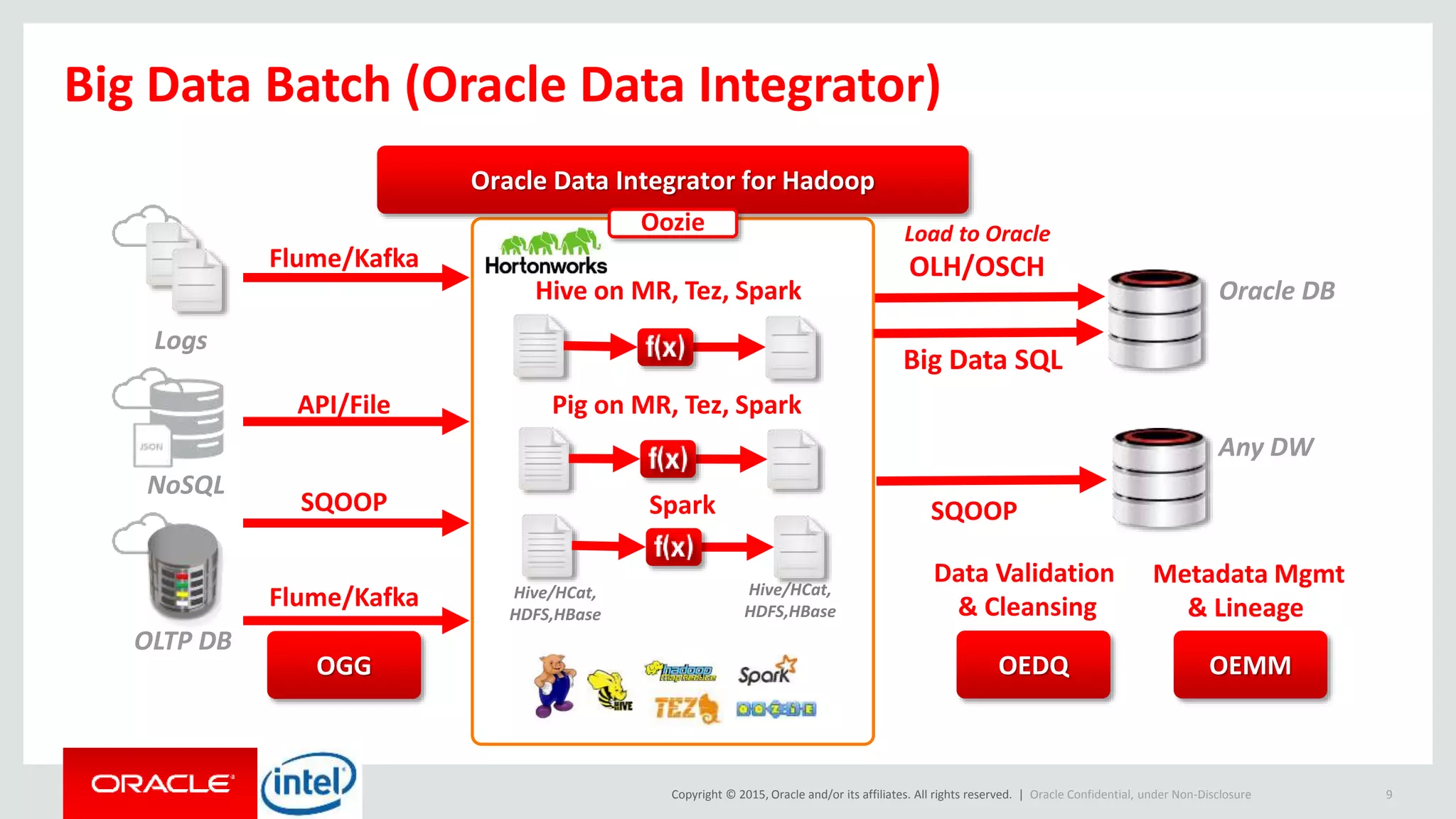
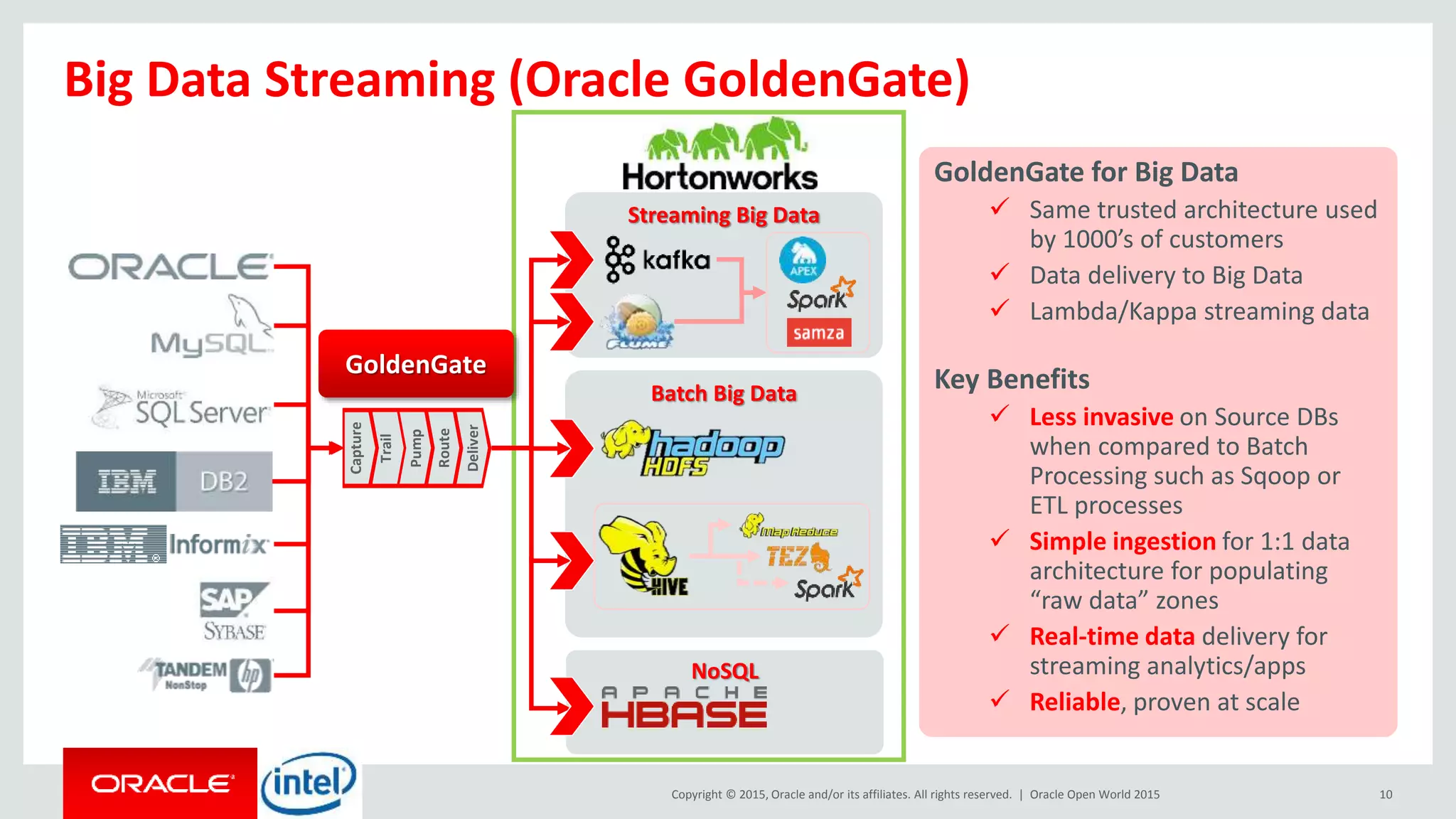
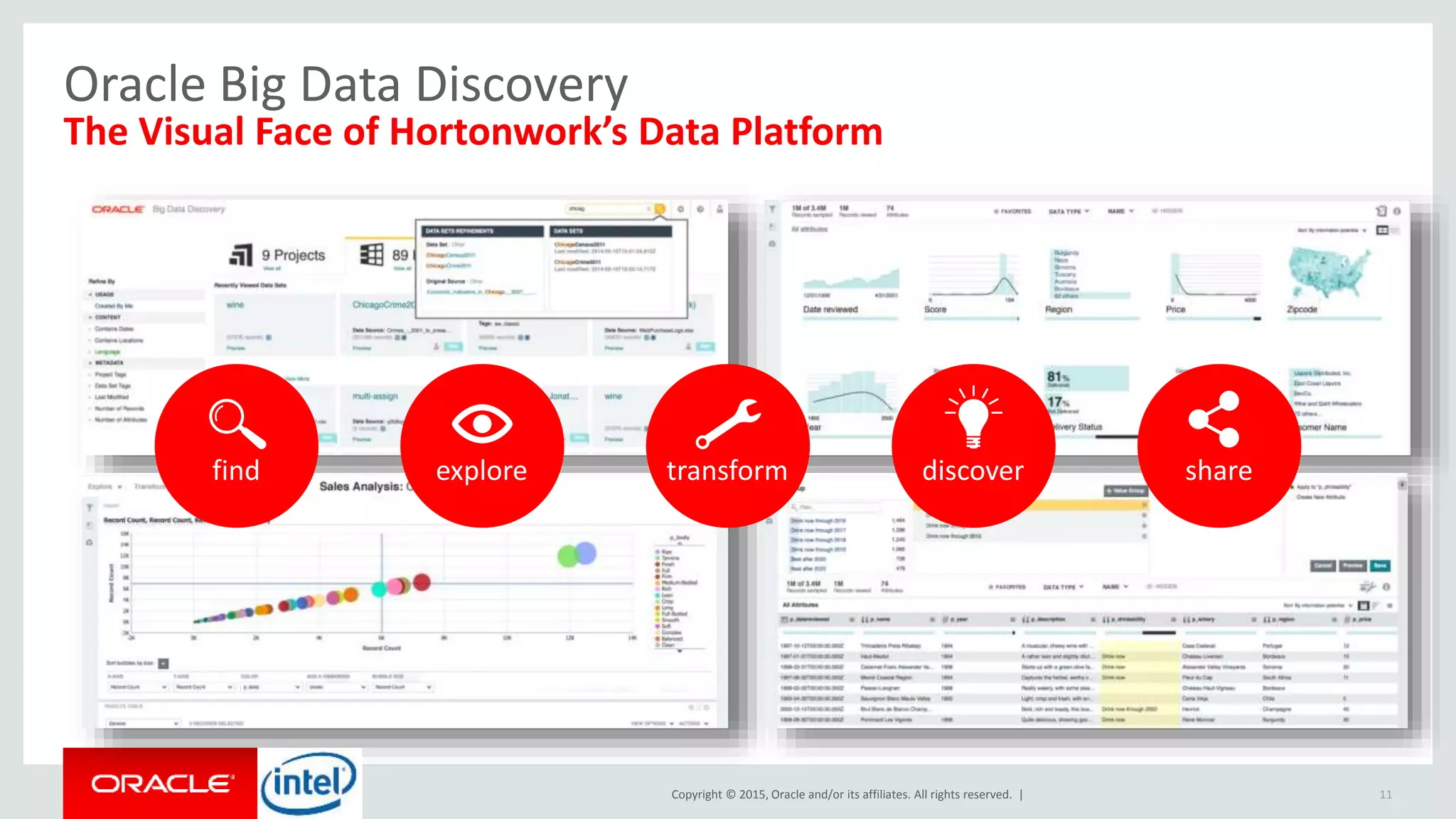
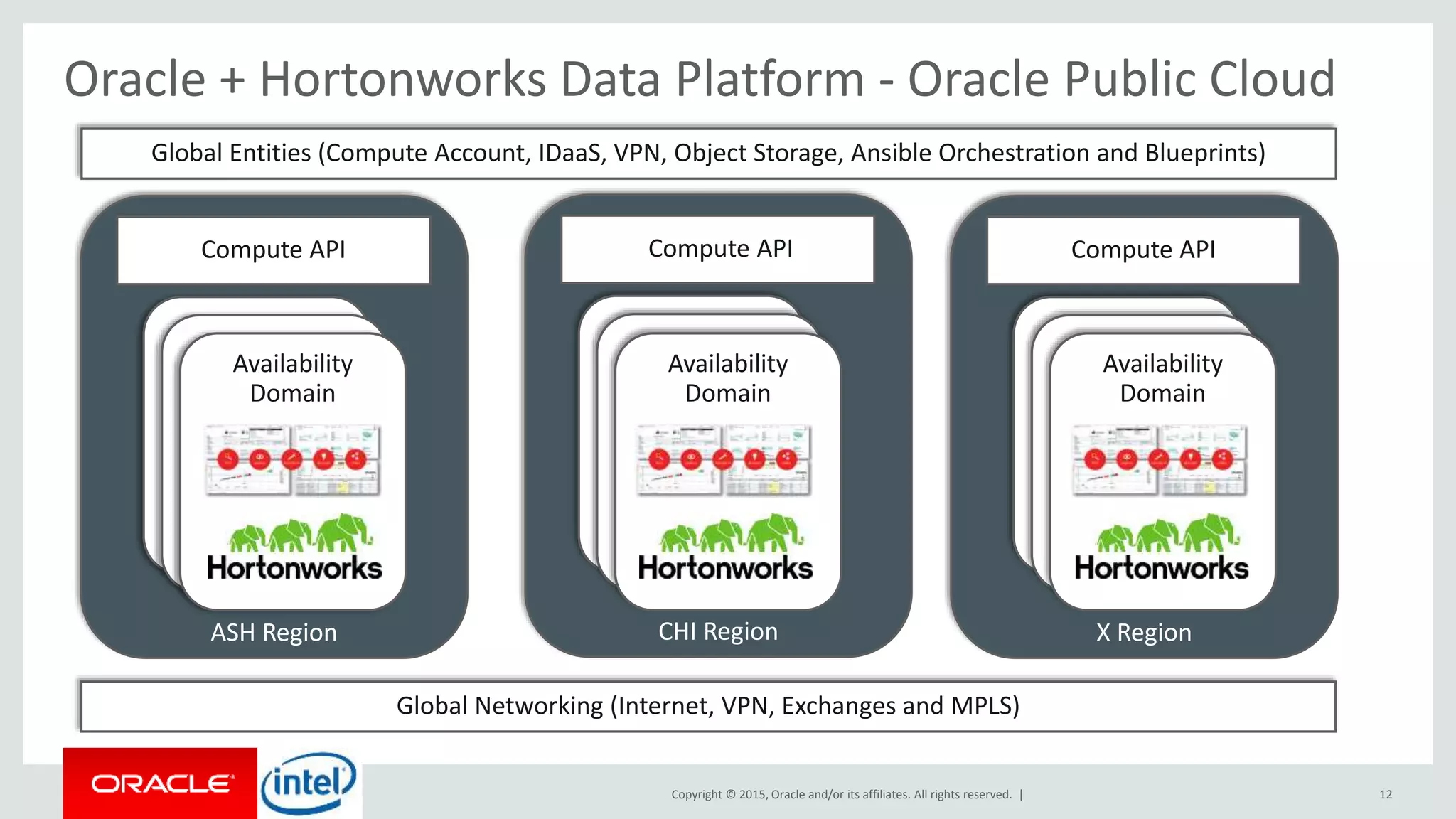
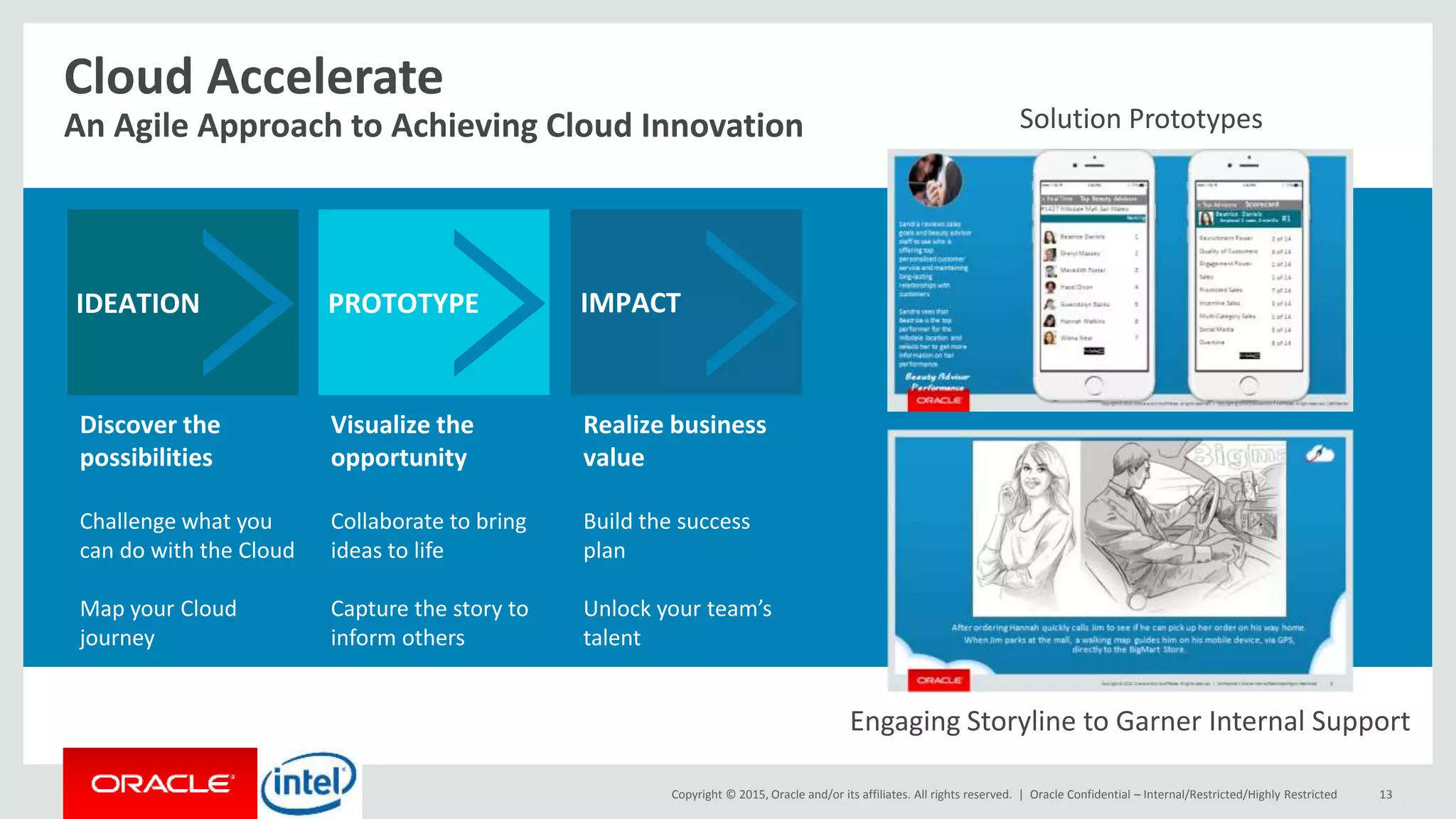
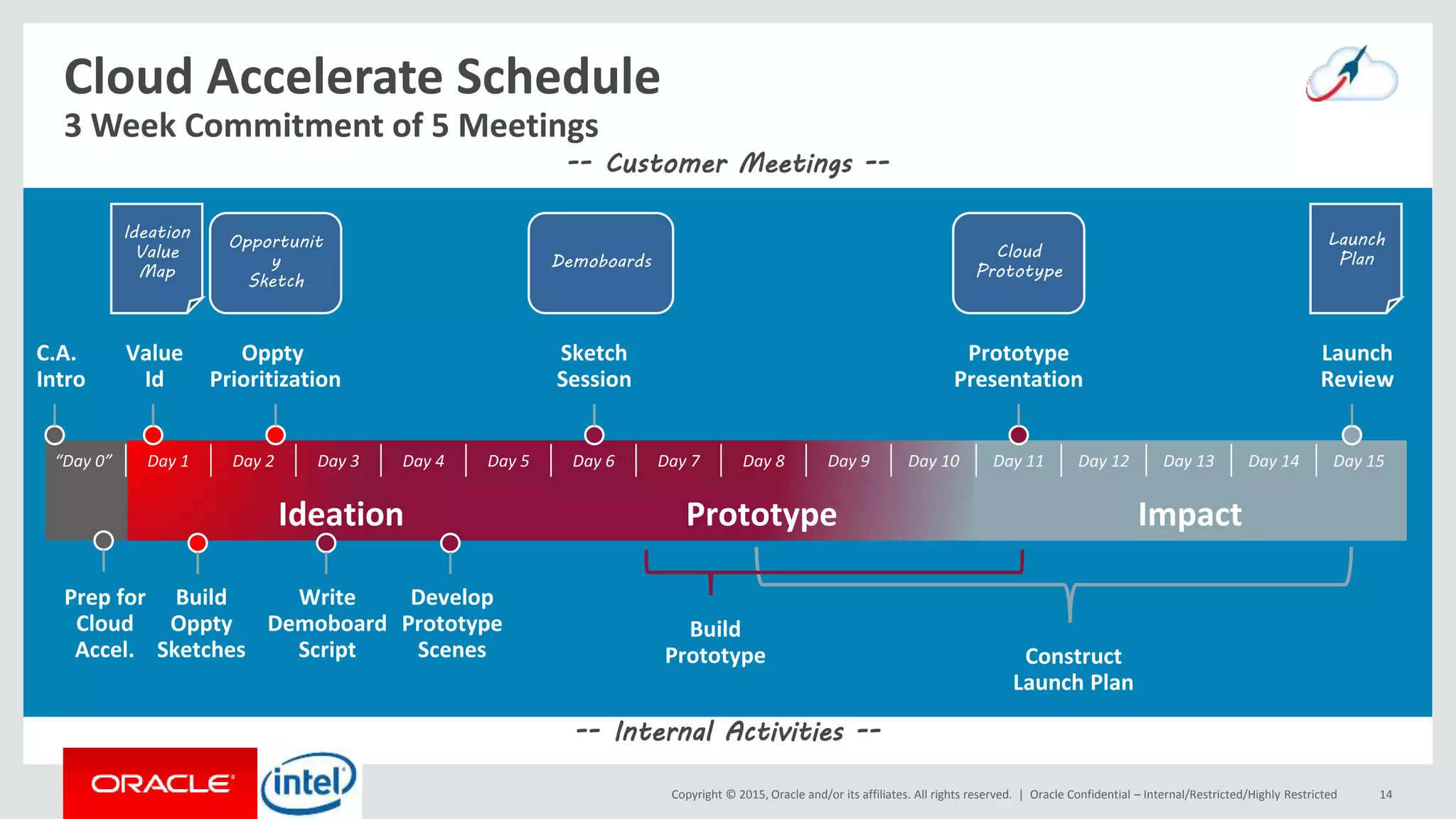

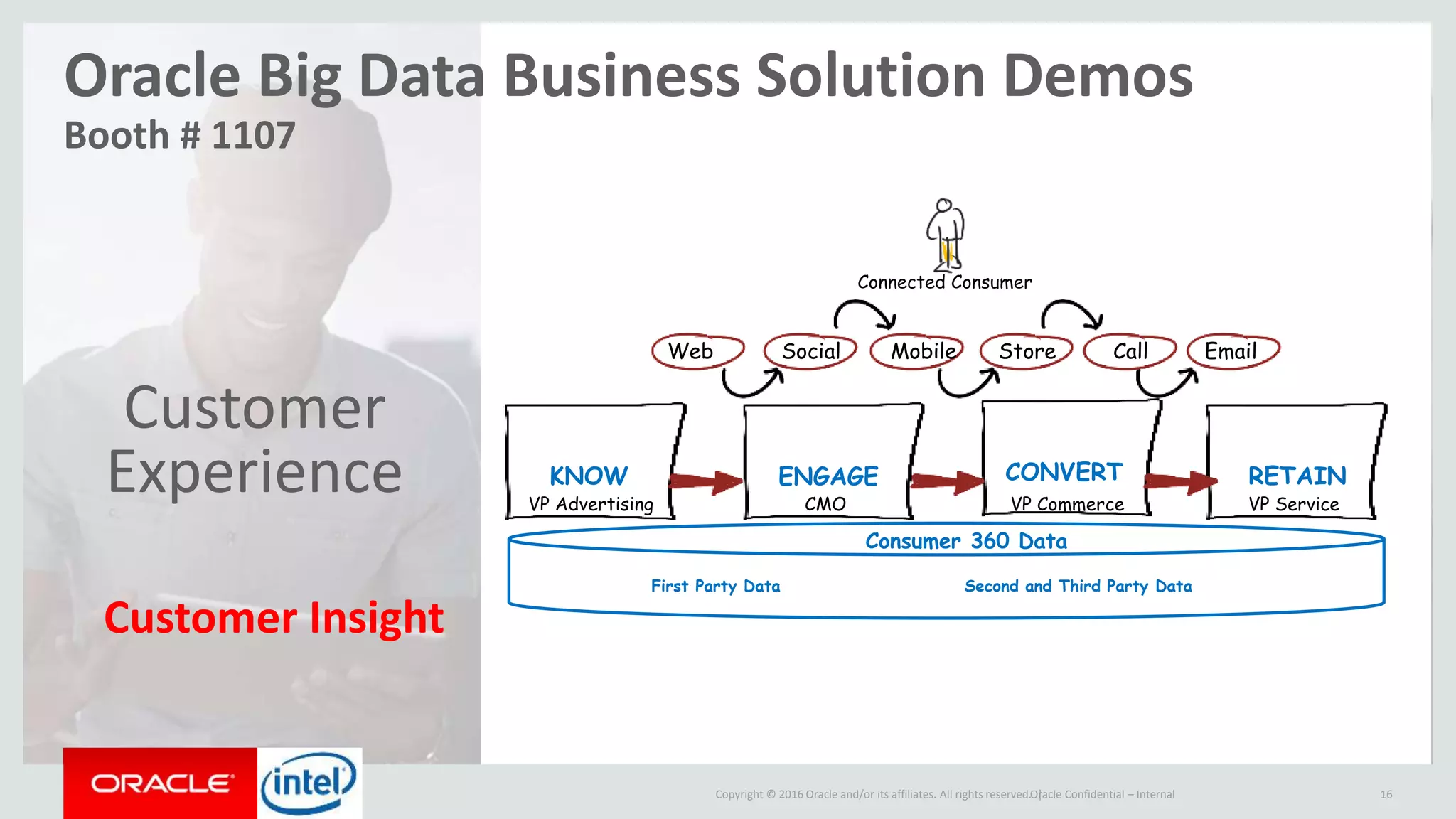

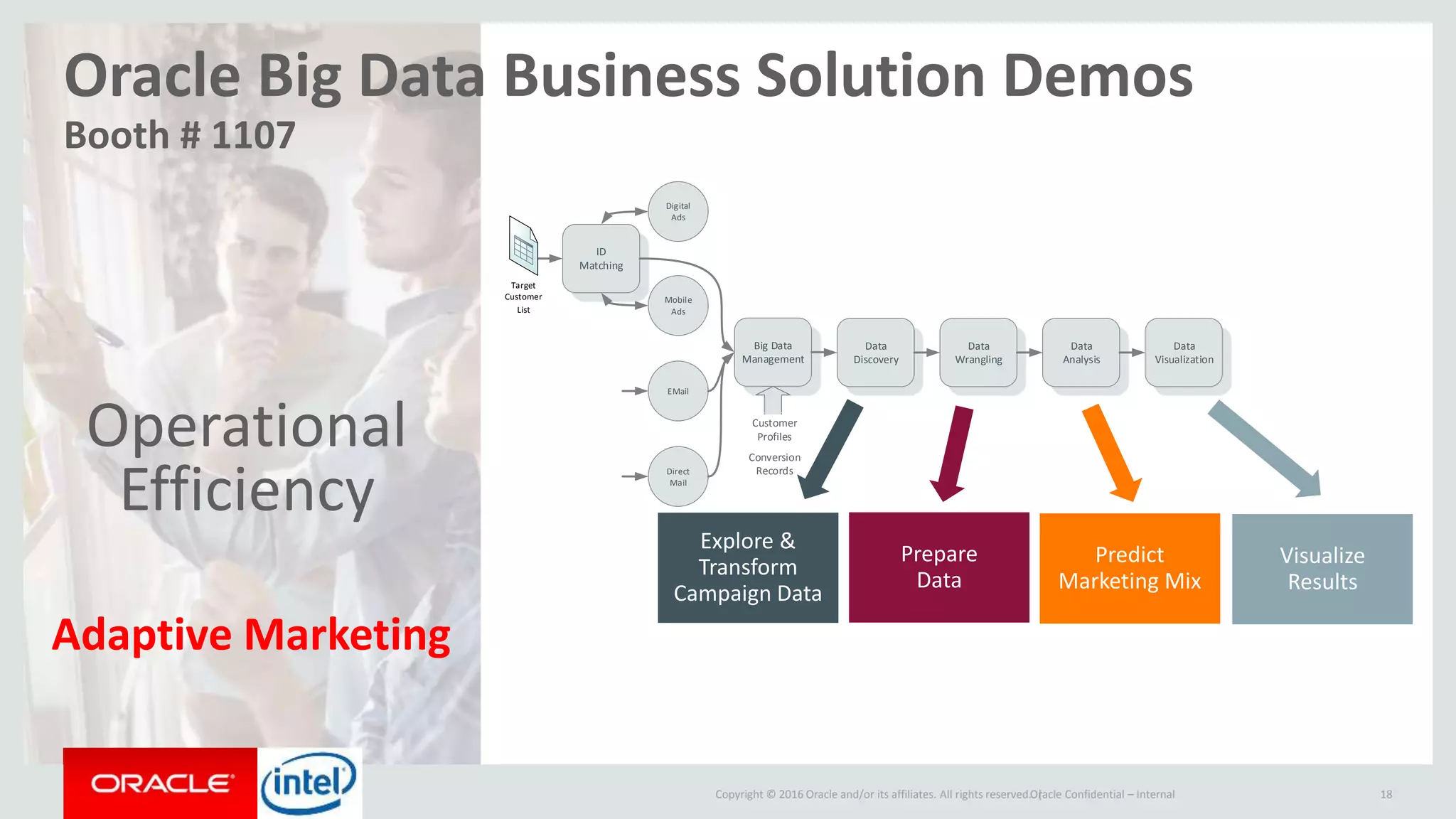




The document discusses Oracle's big data platform and how it can extend Hortonworks' data platform. It provides an overview of Oracle's enterprise big data architecture and the key components of its big data platform. It also discusses how Oracle's platform provides rich SQL access across different data sources and describes some big data solutions for adaptive marketing and predictive maintenance.























































































