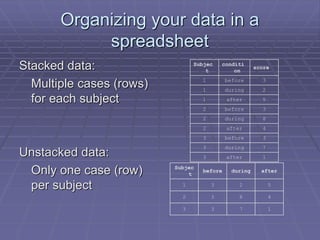
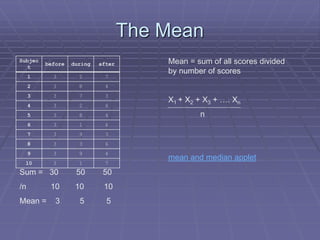
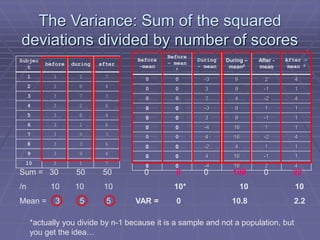
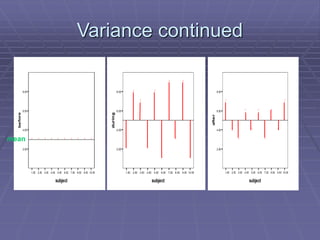
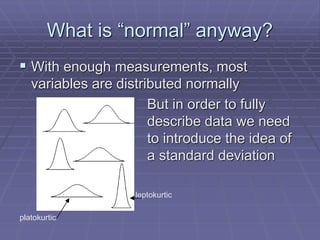
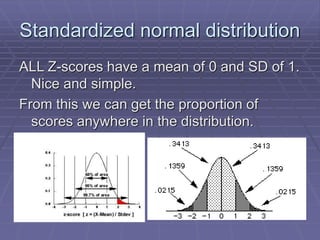
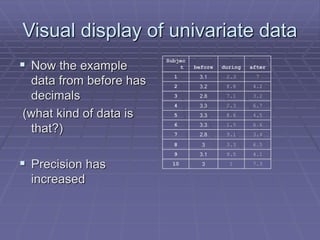
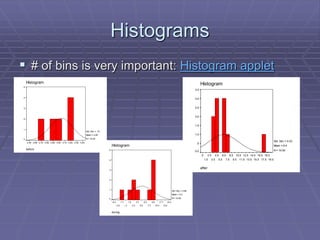
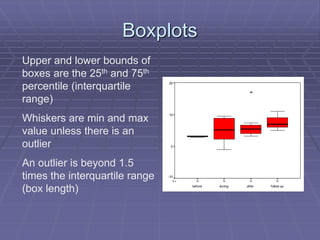
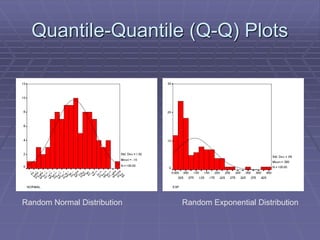
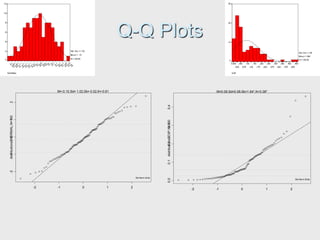
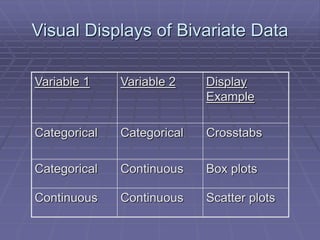
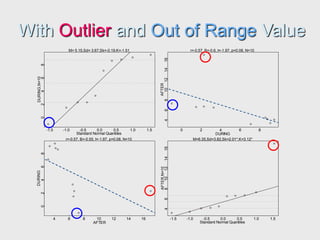
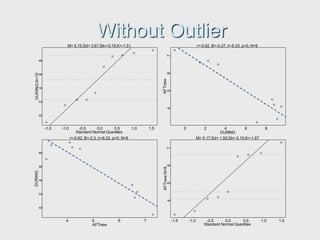
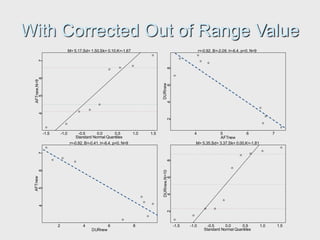
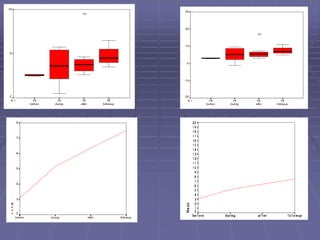
The document provides an extensive overview of exploratory data analysis (EDA), emphasizing the importance of understanding data types, measuring statistics, and identifying distribution characteristics before conducting further analysis. It covers various statistical concepts including central tendency, variability, and the significance of normal distributions, as well as practical techniques for visualizing and checking data integrity through graphs and plots. Ultimately, it highlights the necessity of addressing outliers, skewness, and assumptions in order to ensure valid statistical analyses.