Evolving On-demand Infrastructure for Hadoop 2.0

Prime Dimensions' Hadoop 2.0 Big Data infrastructure features YARN, a distributed data operating system and development platform that extends the batch processing functionality of MapReduce by allowing multiple types of applications to be deployed directly across Hadoop clusters. YARN represents a paradigm shift in processing, managing and analyzing Big Data. The real benefit of YARN is that it allows Hadoop clusters to execute workloads beyond MapReduce. With YARN, Hadoop now has a generic resource-management and distributed application framework, in which multiple data processing applications can run natively in Hadoop. YARN provides extensibility and scalability in Hadoop by splitting the roles of the Hadoop Job Tracker into two processes: (1) the resource management controls access to the clusters resources (memory, CPU, etc.), and (2) the application manager controls task execution. In conjunction with YARN, Prime Dimensions is also offering integration support for other Apache projects, such as Spark, an open source, in-memory data analytics platform that is compatible with Hadoop. Together, YARN and Spark make it possible to establish domain-specific enclaves over multi-tenant compute clusters, creating a virtualized data environment and unified analytics platform, as enterprises evolve from “systems of records” to “systems of engagement.” This often requires deploying in-memory, high performance, petascale technologies, but YARN and Spark offer new options for organizations seeking these analytic capabilities in Hadoop. As Hadoop gains widespread adoption not only as a Big Data technology but also as a data warehouse augmentation strategy, its basic functionality is evolving to meet the demands of increased performance and high scalability. YARN is not simply a new release; it represents a revolutionary advancement of Hadoop. We see tremendous opportunity for the adoption of YARN and Spark as enterprise solutions for generating advanced analytics with reduced time-to-value. There will be significant demand to upgrade early adopters to Hadoop 2.0. Moreover, with the advanced features and capabilities of YARN, the use cases that arise from this new paradigm span across industries with seemingly profound, endless possibilities. There are advantages of bringing together NoSQL, relational and/or in-memory solutions, both Open Source and proprietary, to establish a unified analytics environment.
Recommended

Recommended
More Related Content
Viewers also liked
Viewers also liked (16)
Recently uploaded
Recently uploaded (20)
Evolving On-demand Infrastructure for Hadoop 2.0
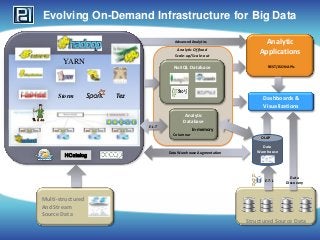
- 1. Evolving On-Demand Infrastructure for Big Data Analytic Offload Scale-up/Scale-out Analytic Applications NoSQL Database REST/JSON APIs Advanced Analytics YARN Storm Tez Dashboards & Visualizations Analytic Database E-L-T In-memory Columnar HCatalog Data Warehouse Augmentation OLAP Data Warehouse E-T-L Multi-structured And Stream Source Data Data Discovery Structured Source Data
Editor's Notes
- Distributed DW architecture. The issue in a multi-workload environment is whether a single-platform data warehouse can be designed and optimized such that all workloads run optimally, even when concurrent. More DW teams are concluding that a multi-platform data warehouse environment is more cost-effective and flexible. Plus, some workloads receive better optimization when moved to a platform beside the data warehouse. In reaction, many organizations now maintain a core DW platform for traditional workloads but offload other workloads to other platforms. For example, data and processing for SQL-based analytics are regularly offloaded to DW appliances and columnar DBMSs. A few teams offload workloads for big data and advanced analytics to HDFS, discovery platforms, MapReduce, and similar platforms. The result is a strong trend toward distributed DW architectures, where many areas of the logical DW architecture are physically deployed on standalone platforms instead of the core DW platform. Big Data requires a new generation of scalable technologies designed to extract meaning from very large volumes of disparate, multi-structured data by enabling high velocity capture, discovery, and analysisSource of second graphic: http://www.saama.com/blog/bid/78289/Why-large-enterprises-and-EDW-owners-suddenly-care-about-BigDatahttp://www.cloudera.com/content/dam/cloudera/Resources/PDF/Hadoop_and_the_Data_Warehouse_Whitepaper.pdfComplex Hadoop jobs can use the data warehouse as a data source, simultaneously leveraging the massively parallel capabilities of two systems. Any MapReduce program can issue SQL statements to the data warehouse. In one context, a MapReduce program is “just another program,” and the data warehouse is “just another database.” Now imagine 100 MapReduce programs concurrently accessing 100 data warehouse nodes in parallel. Both raw processing and the data warehouse scale to meet any big data challenge. Inevitably, visionary companies will take this step to achieve competitive advantages.Promising Uses of Hadoop that Impact DW Architectures I see a handful of areas in data warehouse architectures where HDFS and other Hadoop products have the potential to play positive roles: Data staging. A lot of data processing occurs in a DW’s staging area, to prepare source data for specific uses (reporting, analytics, OLAP) and for loading into specific databases (DWs, marts, appliances). Much of this processing is done by homegrown or tool-based solutions for extract, transform, and load (ETL). Imagine staging and processing a wide variety of data on HDFS. For users who prefer to hand-code most of their solutions for extract, transform, and load (ETL), they will most likely feel at home in code-intense environments like Apache MapReduce. And they may be able to refactor existing code to run there. For users who prefer to build their ETL solutions atop a vendor tool, the community of vendors for ETL and other data management tools is rolling out new interfaces and functions for the entire Hadoop product family. Note that I’m assuming that (whether you use Hadoop or not), you should physically locate your data staging area(s) on standalone systems outside the core data warehouse, if you haven’t already. That way, you preserve the core DW’s capacity for what it does best: squeaky clean, well modeled data (with an audit trail via metadata and master data) for standard reports, dashboards, performance management, and OLAP. In this scenario, the standalone data staging area(s) offload most of the management of big data, archiving source data, and much of the data processing for ETL, data quality, and so on. Data archiving. When organizations embrace forms of advanced analytics that require detail source data, they amass large volumes of source data, which taxes areas of the DW architecture where source data is stored. Imagine managing detailed source data as an archive on HDFS. You probably already do archiving with your data staging area, though you probably don’t call it archiving. If you think of it as an archive, maybe you’ll adopt the best practices of archiving, especially information lifecycle management (ILM), which I feel is valuable but woefully vacant from most DWs today. Archiving is yet another thing the staging area in a modern DW architecture must do, thus another reason to offload the staging area from the core DW platform. Traditionally, enterprises had three options when it came to archiving data: leave it within a relational database, move it to tape or optical disk, or delete it. Hadoop’s scalability and low cost enable organizations to keep far more data in a readily accessible online environment. An online archive can greatly expand applications in business intelligence, advanced analytics, data exploration, auditing, security, and risk management. Multi-structured data. Relatively few organizations are getting BI value from semi- and unstructured data, despite years of wishing for it. Imagine HDFS as a special place within your DW environment for managing and processing semi-structured and unstructured data. Another way to put it is: imagine not stretching your RDBMS-based DW platform to handle data types that it’s not all that good with. One of Hadoop’s strongest complements to a DW is its handling of semi- and unstructured data. But don’t go thinking that Hadoop is only for unstructured data: HDFS handles the full range of data, including structured forms, too. In fact, Hadoop can manage just about any data you can store in a file and copy into HDFS. Processing flexibility. Given its ability to manage diverse multi-structured data, as I just described, Hadoop’sNoSQL approach is a natural framework for manipulating non-traditional data types. Note that these data types are often free of schema or metadata, which makes them challenging for SQL-based relational DBMSs. Hadoop supports a variety of programming languages (Java, R, C), thus providing more capabilities than SQL alone can offer. In addition, Hadoop enables the growing practice of “late binding”. Instead of transforming data as it’s ingested by Hadoop (the way you often do with ETL for data warehousing), which imposes an a priori model on data, structure is applied at runtime. This, in turn, enables the open-ended data exploration and discovery analytics that many users are looking for today. Advanced analytics. Imagine HDFS as a data stage, archive, or twenty-first-century operational data store that manages and processes big data for advanced forms of analytics, especially those based on MapReduce, data mining, statistical analysis, and natural language processing (NLP). There’s much to say about this; in a future blog I’ll drill into how advanced analytics is one of the strongest influences on data warehouse architectures today, whether Hadoop is in use or not.Analyze and Store Approach (ELT?)The analyze and store approach analyzes data as it flows through businessprocesses, across networks, and between systems. The analytical results can then bepublished to interactive dashboards and/or published into a data store (such as a datawarehouse) for user access, historical reporting and additional analysis. Thisapproach can also be used to filter and aggregate big data before it is brought into adata warehouse.There are two main ways of implementing the analyze and store approach:• Embedding the analytical processing in business processes. This techniqueworks well when implementing business process management and serviceorientedtechnologies because the analytical processing can be called as a servicefrom the process workflow. This technique is particularly useful for monitoring andanalyzing business processes and activities in close to real-time – action times ofa few seconds or minutes are possible here. The process analytics created canalso be published to an operational dashboard or stored in a data warehouse forsubsequent use.• Analyzing streaming data as it flows across networks and between systems.This technique is used to analyze data from a variety of different (possiblyunrelated) data sources where the volumes are too high for the store and analyzeapproach, sub-second action times are required, and/or where there is a need toanalyze the data streams for patterns and relationships. To date, many vendorshave focused on analyzing event streams (from trading systems, for example)using the services of a complex event processing (CEP) engine, but this style ofprocessing is evolving to support a wider variety of streaming technologies anddata. Creates stream analytics from many types of streamingdata such as event, video and GPS data.The benefits of the analyze and store approach are fast action times and lower datastorage overheads because the raw data does not have to be gathered andconsolidated before it can be analyzed.using HiveQL to create a load-ready file for a relational database.