Download to read offline











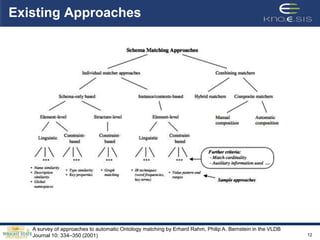












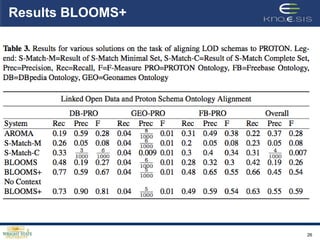






This document describes the BLOOMS+ approach for performing contextual ontology alignment of Linked Open Data datasets with an upper ontology. It presents the challenges of existing ontology matching approaches when applied to large, diverse LOD datasets. BLOOMS+ leverages structured knowledge from Wikipedia categories to generate "BLOOMS trees" representing different senses of concept names, and calculates similarity between trees to identify subclass, equivalence and other relationships between concepts in different datasets. It outperforms existing approaches on aligning three real-world LOD ontologies to the PROTON upper ontology. Future work aims to improve the weighting and identify additional contextual sources to assist with schema alignment across datasets.


































![[Evaldas Taroza - Master thesis] Schema Matching and Automatic Web Data Extra...](https://cdn.slidesharecdn.com/ss_thumbnails/5c1568bc-753d-44dc-88ac-dcf114742b88-150313043325-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)































