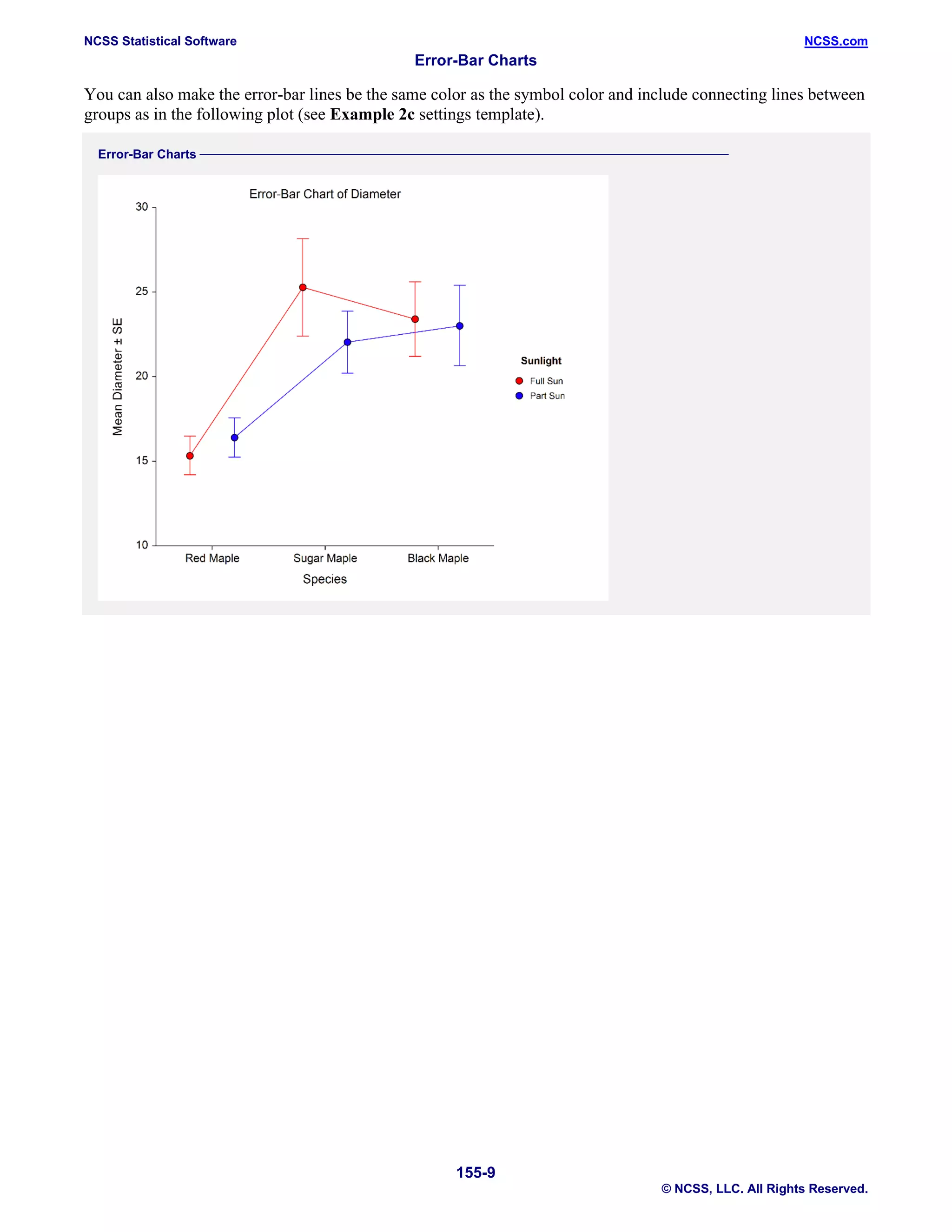
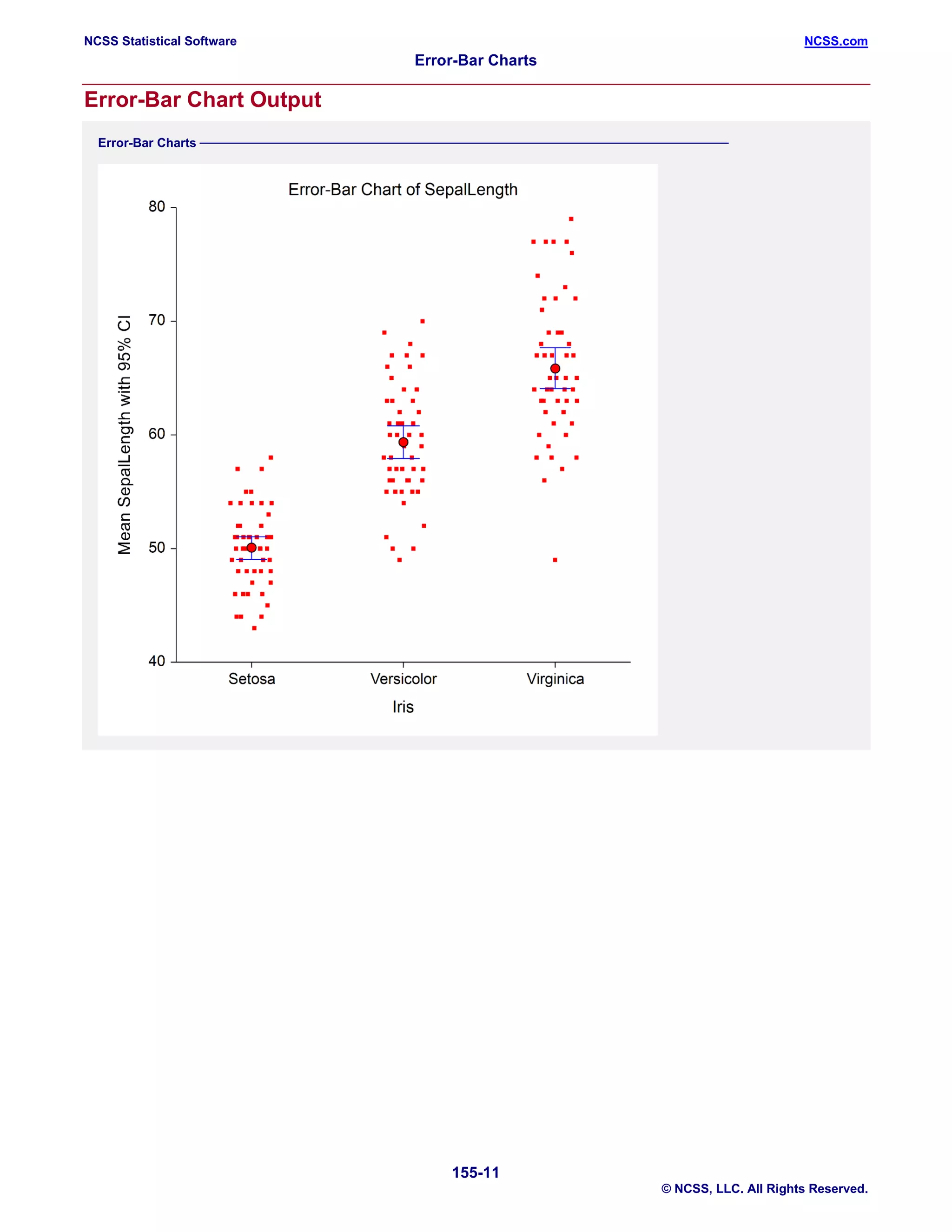
This document describes how to create error bar charts in NCSS statistical software. It includes:
1. Examples of different types of error bar charts that can be produced, including ones with standard deviation, standard error, confidence intervals, data range, or percentiles as the error bars.
2. Information on the data structure needed and options for customizing aspects of the error bar chart like the center line, bars, symbols, error bars, layout, and connecting lines.
3. Four examples showing how to generate different error bar charts using the Fisher iris and Tree datasets, including ones with subgroups, confidence intervals, and plotting medians instead of means.