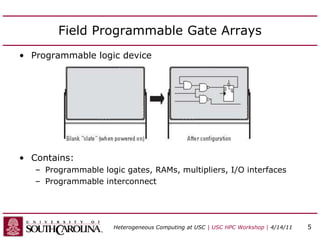
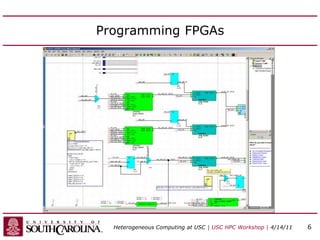
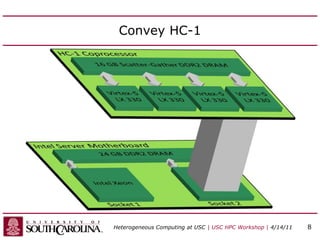
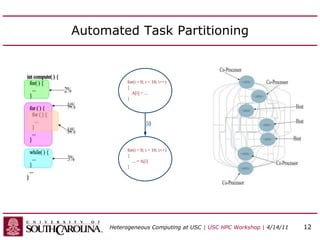
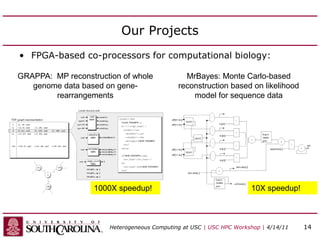
This document discusses heterogeneous computing research at the University of South Carolina. It summarizes that heterogeneous computing uses general-purpose CPUs combined with specialized processors like FPGAs and GPUs. The research group's goals are to adapt applications to heterogeneous models and build development tools. Examples of applications accelerated with FPGAs and GPUs include computational biology algorithms, sparse matrix arithmetic, sequence alignment, and logic minimization.











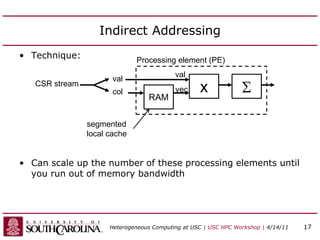
![Sparse Matrix-Vector Multiply
• Code for Ax = b
– A is matrix stored in val, col, ptr
row = 0
for i = 0 to number_of_nonzero_elements do
if i = ptr[row+1] then row=row+1, b[row]=0.0
b[row] = b[row] + val[i] * x[col[i]]
end
recurrence (reduction)
non-affine (indirect) indexing
Heterogeneous Computing at USC | USC HPC Workshop | 4/14/11 16](https://image.slidesharecdn.com/epscortalk2-220920024221-d368c578/85/epscor_talk_2-pptx-16-320.jpg)








![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201103-cudabasicsshare-110209024624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[Harvard CS264] 02 - Parallel Thinking, Architecture, Theory & Patterns](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201102-archtheorypatternshare-110206154047-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















