

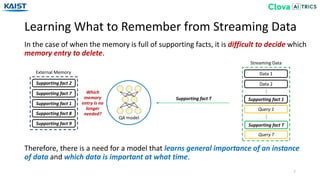
![Memory Encoder (EMR-Independent)
16
Similar to [Gülçehre18], EMR-Independent captures the relative importance of each
memory entry independently to the new data instance.
[Gülçehre18] Ç. Gülçehre, S. Chandar, K. Cho, Y. Bengio, Dynamic Neural Turing Machine with Continuous and Discrete Addressing Schemes. NC 2018
𝛼1
(𝑡)
𝑚1
(𝑡)
𝑚2
(𝑡)
𝑚3
(𝑡)
𝑚4
(𝑡)
𝑚5
(𝑡)
𝑚6
(𝑡)
External Memory
𝛼2
(𝑡)
𝛼3
(𝑡)
𝛼4
(𝑡)
𝛼5
(𝑡)
𝛾1
(𝑡)
𝛾2
(𝑡)
𝛾3
(𝑡)
𝛾4
(𝑡)
𝛾5
(𝑡)
𝑣1
(𝑡−1)
𝑣2
(𝑡−1)
𝑣3
(𝑡−1)
𝑣4
(𝑡−1)
𝑣5
(𝑡−1)
𝑔1
(𝑡)
𝑔2
(𝑡)
𝑔3
(𝑡)
𝑔4
(𝑡)
𝑔5
(𝑡)
Memory Encoder
(Independent)
Policy Network
Multi-layer
Perceptron
𝜋 𝑖 𝑀 𝑡
, 𝑒 𝑡
; 𝜃
Major drawback is that the evaluation of each memory depends only on the input.](https://image.slidesharecdn.com/10kaist-190919053214/85/Episodic-Memory-Reader-Learning-What-to-Remember-for-Question-Answering-from-Streaming-Data-16-320.jpg)
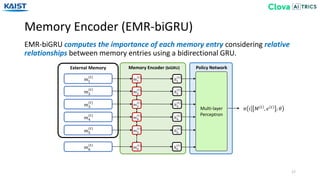
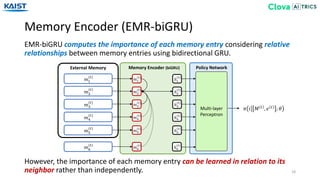
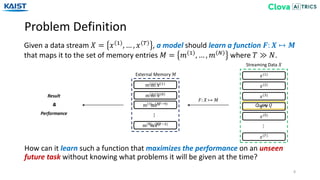
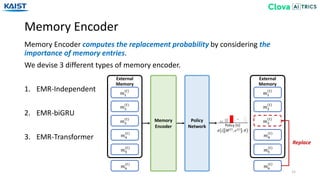
![Memory Encoder (EMR-Transformer)
19
EMR-Transformer computes the relative importance of each memory entry using a
self-attention mechanism from [Vaswani17].
[Vaswani17] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, Attention is All you Need. NIPS 2017
External Memory Memory Encoder
(Transformer)
Policy Network
Multi-layer
Perceptron
𝜋 𝑖 𝑀 𝑡
, 𝑒 𝑡
; 𝜃
𝑚1
(𝑡)
𝑚1
(𝑡)
𝑚2
(𝑡)
𝑚3
(𝑡)
𝑚4
(𝑡)
𝑚5
(𝑡)
𝑚6
(𝑡)
𝑚2
(𝑡)
𝑚3
(𝑡)
𝑚4
(𝑡)
𝑚5
(𝑡)
ℎ1
(𝑡)
ℎ2
(𝑡)
ℎ3
(𝑡)
ℎ4
(𝑡)
ℎ5
(𝑡)
𝑚6
(𝑡)
ℎ6
(𝑡)](https://image.slidesharecdn.com/10kaist-190919053214/85/Episodic-Memory-Reader-Learning-What-to-Remember-for-Question-Answering-from-Streaming-Data-19-320.jpg)
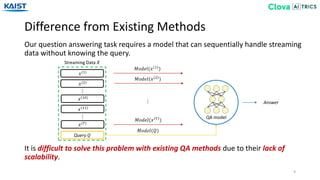
![Value Network
20
Two types of reinforcement learning are used – A3C [Mnih16] or REINFORCE [Williams92].
We adopt Deep Sets from [Zaheer17] to make set representation ℎ 𝑡
.
[Zaheer17] M. Zaheer, S. Kottur, S. Ravanbakhsh, B. Póczos, R. R. Salakhutdinov, A. J. Smola, Deep Sets. NIPS 2017
[Williams92] R. J. Williams, Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. ML 1992
[Mnih16] V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. P. Lillicrap, T. Harley, D. Silver, K. Kavukcuoglu, Asynchronous Methods for Deep Reinforcement Learning. ICML 2016
External Memory Memory Encoder
(Transformer)
Multi-layer
Perceptron
GRU Cellℎ(𝑡)
𝑉(𝑡)
ℎ(𝑡−1)
𝑚1
(𝑡)
𝑚1
(𝑡)
𝑚2
(𝑡)
𝑚3
(𝑡)
𝑚4
(𝑡)
𝑚5
(𝑡)
𝑚6
(𝑡)
𝑚2
(𝑡)
𝑚3
(𝑡)
𝑚4
(𝑡)
𝑚5
(𝑡)
ℎ1
(𝑡)
ℎ2
(𝑡)
ℎ3
(𝑡)
ℎ4
(𝑡)
ℎ5
(𝑡)
𝑚6
(𝑡)
ℎ6
(𝑡)
Value Network](https://image.slidesharecdn.com/10kaist-190919053214/85/Episodic-Memory-Reader-Learning-What-to-Remember-for-Question-Answering-from-Streaming-Data-20-320.jpg)

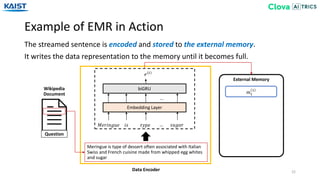
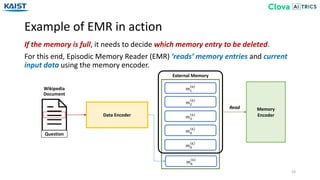
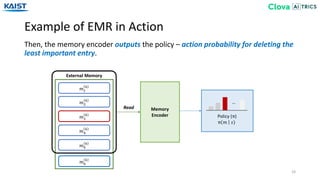
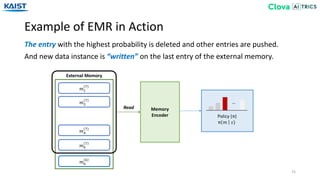
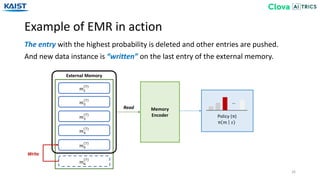
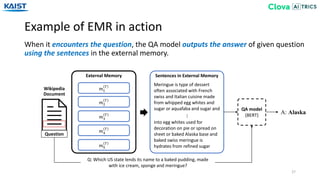
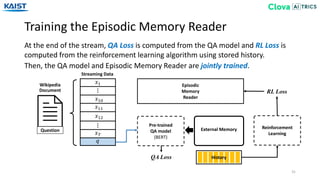
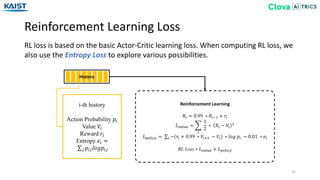
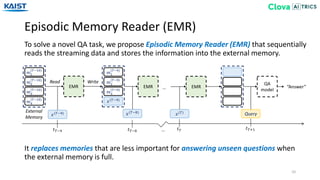
![Experiment - Baselines
33
EMR that makes the policy in an independent method based on Dynamic Least
Recently Used from [Gülçehre18].
• FIFO (First-In First-Out) • Uniform • LIFO (Last-In First-Out)
• EMR-Independent
𝑚1
6
𝑚2
6
𝑚3
6
𝑚4
6
𝑚5
6
External Memory
𝑚1
6
𝑚2
6
𝑚3
6
𝑚4
6
𝑚5
6
External Memory
𝑚1
6
𝑚2
6
𝑚3
6
𝑚4
6
𝑚5
6
External Memory
Policy (π)
π 𝑚 𝑠)
𝑚5
6
Policy (π)
π 𝑚 𝑠)
𝑚5
6
Policy (π)
π 𝑚 𝑠)
We experiment our EMR-biGRU and EMR-Transformer against several baselines.
[Gülçehre18] Ç. Gülçehre, S. Chandar, K. Cho, Y. Bengio, Dynamic Neural Turing Machine with Continuous and Discrete Addressing Schemes. NC 2018](https://image.slidesharecdn.com/10kaist-190919053214/85/Episodic-Memory-Reader-Learning-What-to-Remember-for-Question-Answering-from-Streaming-Data-33-320.jpg)
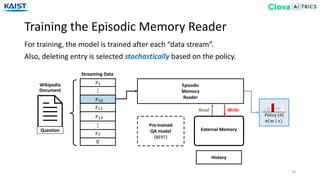
![Dataset (bAbI Dataset)
34
We evaluate our models and baselines on three question answering datasets.
[Weston15] S. Sukhbaatar, A. Szlam, J. Weston, R. Fergus: End-To-End Memory Networks. NIPS 2015
• bAbI [Weston15]: A synthetic dataset for episodic question answering,
consisting of 20 tasks with small amount of vocabulary.
Original Task 2 Noisy Task 2
Index Context
Mary journeyed to the bathroom
Sandra went to the garden
Sandra put down the milk there
1
2
6
…
…
Where is the milk? Garden [2, 6]
Daniel went to the garden
Daniel dropped the football
8
17
…
…
Where is the football? Bedroom [12, 17]
Index Context
Sandra moved to the kitchen
Wolves are afraid of cats
Mary is green
1
2
6
…
…
Where is the milk? Garden [1, 4]
Mice are afraid of wolves
Mary journeyed to the kitchen
38
42
…
…
Where is the apple? Kitchen [34, 42]
→ It can be solved by remembering a person or an object.](https://image.slidesharecdn.com/10kaist-190919053214/85/Episodic-Memory-Reader-Learning-What-to-Remember-for-Question-Answering-from-Streaming-Data-34-320.jpg)
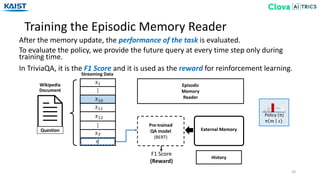
![Dataset (TriviaQA Dataset)
35
We evaluate our models and baselines on three question answering datasets.
[Joshi17] M. Joshi, E. Choi, D. S. Weld, L. Zettlemoyer, TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. ACL 2017
[Context]
001 World War I (WWI or WW1), also known as the First World War, or the Great War, was a global war originating in …
002 More than 70 million military personnel, including 60 million Europeans, were mobilised in one of the largest wars in …
550 Some war memorials date the end of the war as being when the Versailles Treaty was signed in 1919, …
770 Britain, rationing was finally imposed in early 1918, limited to meat, sugar, and fats (butter and margarine), but not bread.
……
[Question]
Where was the peace treaty signed that brought World War I to an end?
[Answer]
Versailles castle
• TriviaQA [Joshi17]: a realistic text-based question answering dataset,
including 95K question-answer pairs from 662K documents.
→ It requires a model with high-level reasoning and capability for reading
large amount of sentences in document.](https://image.slidesharecdn.com/10kaist-190919053214/85/Episodic-Memory-Reader-Learning-What-to-Remember-for-Question-Answering-from-Streaming-Data-35-320.jpg)
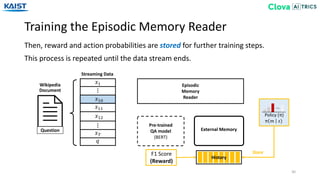
![Dataset (TVQA Dataset)
36
We evaluate our models and baselines on three question answering datasets.
[Lei18] J. Lei, L. Yu, M. Bansal, T. L. Berg, TVQA: Localized, Compositional Video Question Answering. EMNLP 2018
[Video Clip]
[Question] What is Kutner writing on when talking to Lawrence?
[Answer 1] Kutner is writing on a clipboard.
[Answer 2] Kutner is writing on a laptop.
[Answer 3] Kutner is writing on a notepad.
[Answer 4] Kutner is writing on an index card.
[Answer 5] Kutner is writing on his hand.
… …
• TVQA [Lei18]: a localized, compositional video question answering dataset
containing 153K question-answer pairs from 22K clips in 6 TV series.
→ It requires a model that is able to understand multi-modal information.](https://image.slidesharecdn.com/10kaist-190919053214/85/Episodic-Memory-Reader-Learning-What-to-Remember-for-Question-Answering-from-Streaming-Data-36-320.jpg)
![Sentence 3
Sentence N-14
Experiment on bAbI Dataset
37
We combine our model with MemN2N [Weston15] on bAbI dataset.
[Weston15] S. Sukhbaatar, A. Szlam, J. Weston, R. Fergus: End-To-End Memory Networks. NIPS 2015
In this experiment, we set varying memory size to evaluate the efficiency of our model.
EMR
QA
model
(MemN2N)
Sentence 1
Sentence 2
Query M
External Memory
Sentence 1
Sentence 2
Write
Sentence N-13
Sentence N
Streaming Data
Read
………
Sentence 2
Sentence 2
“Answer”
Query 1](https://image.slidesharecdn.com/10kaist-190919053214/85/Episodic-Memory-Reader-Learning-What-to-Remember-for-Question-Answering-from-Streaming-Data-37-320.jpg)
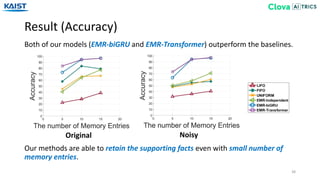

![Chunk 3 (20 words)
Chunk 2 (20 words)
Experiment on TriviaQA Dataset
40
We combine our model with BERT [Devlin18] on TriviaQA dataset.
[Devlin18] J. Devlin, M. Chang, K. Lee, K. Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL-HLT 2019
We extract the indices of span prediction since TriviaQA does not provide it.
We embed 20 words into each memory entry and hold 400 words at maximum.
Wikipedia
Document
Question
Chunk 1 (20 words)
Query
Chunk 16 (20 words)
Chunk N (20 words)
Streaming Data
……
EMR
QA
model
(BERT)
External MemoryWrite
Read
“Answer”
Chunk 3
Chunk N
Chunk 7
Chunk 17
Chunk N
…](https://image.slidesharecdn.com/10kaist-190919053214/85/Episodic-Memory-Reader-Learning-What-to-Remember-for-Question-Answering-from-Streaming-Data-40-320.jpg)

![Experiment on TVQA Dataset
42
Multi-stream model from [Lei18] is used as QA model with ours.
[Lei18] J. Lei, L. Yu, M. Bansal, T. L. Berg, TVQA: Localized, Compositional Video Question Answering. EMNLP 2018
A subtitle is attached to the frame which has the start of the subtitle.
One frame and the corresponding subtitle are jointly embedded into each memory
entry.
Frame | No Sub. 3
Frame | Subtitle 2
Video Clip
Question
Frame | Subtitle 1
Query
Frame | Subtitle 4
Frame | SubtitleN
Streaming Data
…
EMR
QA model
(Multi-stream)
External MemoryWrite
Read
“Answer”
Frame | Subtitle 2
Frame | SubtitleN
Frame | Subtitle 5
Frame | Subtitle9
Frame | No Sub. 5
…](https://image.slidesharecdn.com/10kaist-190919053214/85/Episodic-Memory-Reader-Learning-What-to-Remember-for-Question-Answering-from-Streaming-Data-42-320.jpg)
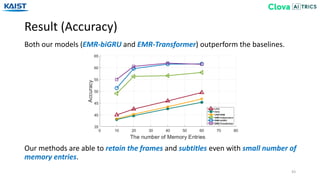
![Example of TVQA Result
44
[Question] < 00:55.00 ~ 01:06.33 >
Who enters the coffee shop after Ross shows everyone the paper?
[Answer]
1) Joey 2) Rachel 3) Monica 4) Chandler 5) Phoebe
[Video Clip]
00:01 00:02 00:03 1:32 1:33
…
[Subtitle]
00:03 UNKNAME: Hey. I got some bad news. What?
00:05 UNKNAME: That’s no way to sell newspapers ...
(Ellipsis)
01:31 UNKNAME: Your food is abysmal!
[Subtitle]
𝑚0 UNKNAME: No. Monica’s restaurant got a horrible review ...
𝑚1 UNKNAME: I didn’t want her to see it, so I ran around and ...
𝑚2 Joey: This is bad. And I’ve had bad reviews.
[Memory Information after Reading Streaming Data]
𝑚3 Monica: Oh, my God! Look at all the newspapers.
𝑚4 UNKNAME: They say there’s no such thing as …
𝑚0 𝑚1 𝑚2 𝒎 𝟑 𝑚4](https://image.slidesharecdn.com/10kaist-190919053214/85/Episodic-Memory-Reader-Learning-What-to-Remember-for-Question-Answering-from-Streaming-Data-44-320.jpg)




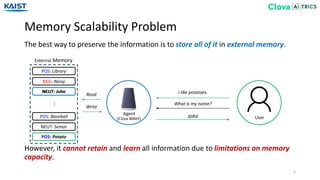
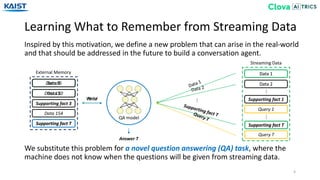
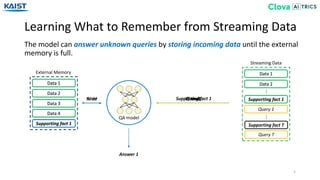
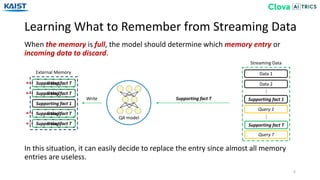
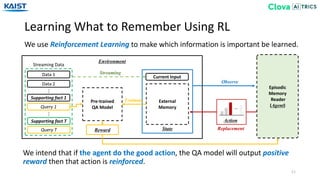
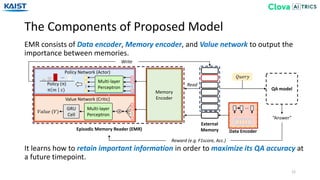
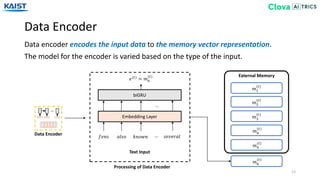
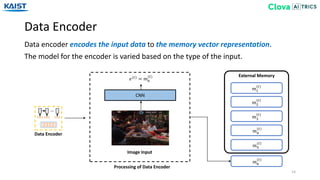
The document presents the Episodic Memory Reader (EMR), a model designed to enhance question answering from streaming data by selectively storing and managing relevant information in external memory. EMR addresses the scalability challenges of existing QA models by utilizing reinforcement learning to determine which data entries to retain or discard as new information arrives. The model performs sequentially with respect to streaming data, maximizing accuracy for unforeseen future tasks without prior knowledge of incoming queries.










![[PR12] PR-036 Learning to Remember Rare Events](https://cdn.slidesharecdn.com/ss_thumbnails/pr12pr-036learningtoremeberrareevents-170917140144-thumbnail.jpg?width=640&height=640&fit=bounds)























![[saltlux] KorQuAD v1.0 참관기](https://cdn.slidesharecdn.com/ss_thumbnails/05saltlux-190919052734-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)