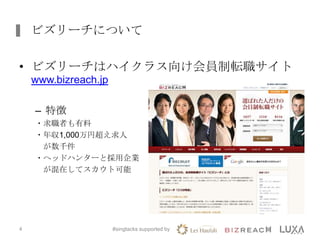
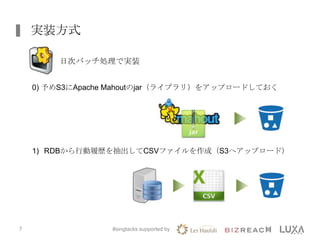
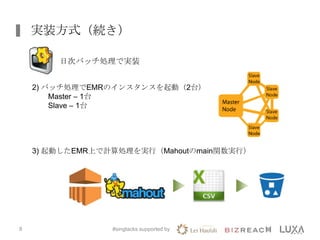
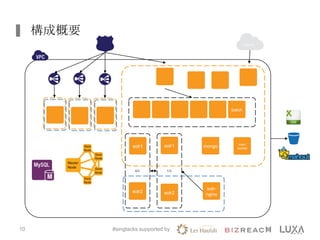
株式会社ビズリーチにおける、簡易レコメンデーションシステムを構築する際に利用したElastic MapReduce(EMR)の活用事例について、簡単にまとめたスライドです。 ※2013年9月27日 AWSJapan様主催のセミナーで発表したもの


















![[社内勉強会]ELBとALBと数万スパイク負荷テスト](https://cdn.slidesharecdn.com/ss_thumbnails/elbalb-160822022623-thumbnail.jpg?width=640&height=640&fit=bounds)







































![The Road to Talent [Infographic]](https://cdn.slidesharecdn.com/ss_thumbnails/the-road-to-talent-hireright-infographic-150326145908-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)









