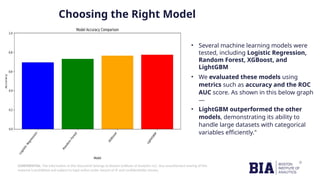
The document outlines a project focused on using machine learning to predict employee attrition, highlighting the importance of employee retention for organizations. Key components include data preparation, model selection, and optimization, ultimately achieving an 82% accuracy rate with the LightGBM model. Insights from this predictive model aim to assist HR teams in improving retention strategies and workforce stability.




















![IBM-HR-Analytics-Employee-Attrition-and-Performance[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ibm-hr-analytics-employee-attrition-and-performance1-251018181740-7e1d1f2b-thumbnail.jpg?width=640&height=640&fit=bounds)










































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)












