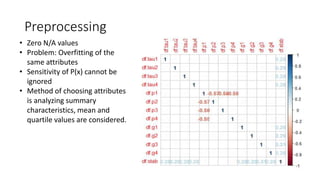
The document presents an analysis of electrical grid stability using a dataset from the UCI machine learning repository, focusing on classifying the stability into stable and unstable categories. Various machine learning methods, including Naïve Bayes, Random Forest, and Decision Tree, were employed, yielding high accuracy results, with Random Forest and Decision Tree achieving 100% accuracy. The study involves preprocessing data, attribute selection, and evaluating model performance through precision, recall, and F1 scores.



![Attributes Information
• Total - 14 predictive attributes, 1target attribute(2classes)
• tau[x] : Reaction time of participant (real from the range [0.5,10]s).
• p[x] : Nominal power consumed(negative)/produced(positive)(real).
• g[x] : Coefficient (gamma) proportional to price elasticity (real from
the range [0.05,1]s^-1).
• stab: The maximal real part of the characteristic equation root (if
positive - the system is linearly unstable)(real)
• stabf: The stability label of the system (stable/unstable)](https://image.slidesharecdn.com/projectpa-190702042501/85/Electrical-Grid-Stability-Simulated-Data-Set-analysis-using-R-4-320.jpg)






![Splitting the dataset
• Training Data Set: 95% [9091 11] • Testing Data Set: 5% [909 11]](https://image.slidesharecdn.com/projectpa-190702042501/85/Electrical-Grid-Stability-Simulated-Data-Set-analysis-using-R-12-320.jpg)
![Naïve Bayes Results
• Accuracy = 97.03%
• Precision [How many selected items are
relevant OR TP/(TP+FP)]= = 0.9558
• Recall [How many items are selected
relevant OR TP/TP+FN]= 0.9589
• F1 (Harmonic mean of precision and recall)=
(2 * 0.9558 * 0.9589) / (0.9558 + 0.9589) =
0.9573475](https://image.slidesharecdn.com/projectpa-190702042501/85/Electrical-Grid-Stability-Simulated-Data-Set-analysis-using-R-13-320.jpg)
![Random Forest Results
• Accuracy = 100%
• Precision [How many selected
items are relevant OR
TP/(TP+FP)]= 1
• Recall [How many items are
selected relevant OR TP/TP+FN]=
1
• F1 = (2 * 1* 1) / (1 + 1) = 1](https://image.slidesharecdn.com/projectpa-190702042501/85/Electrical-Grid-Stability-Simulated-Data-Set-analysis-using-R-14-320.jpg)
![Decision Tree Results
• Accuracy = 100%
• Precision [How many selected
items are relevant OR
TP/(TP+FP)]= 1
• Recall [How many items are
selected relevant OR TP/TP+FN]=
1
• F1 = (2 * 1 * 1) / (1 + 1) = 1](https://image.slidesharecdn.com/projectpa-190702042501/85/Electrical-Grid-Stability-Simulated-Data-Set-analysis-using-R-15-320.jpg)
















![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)





