Download to read offline






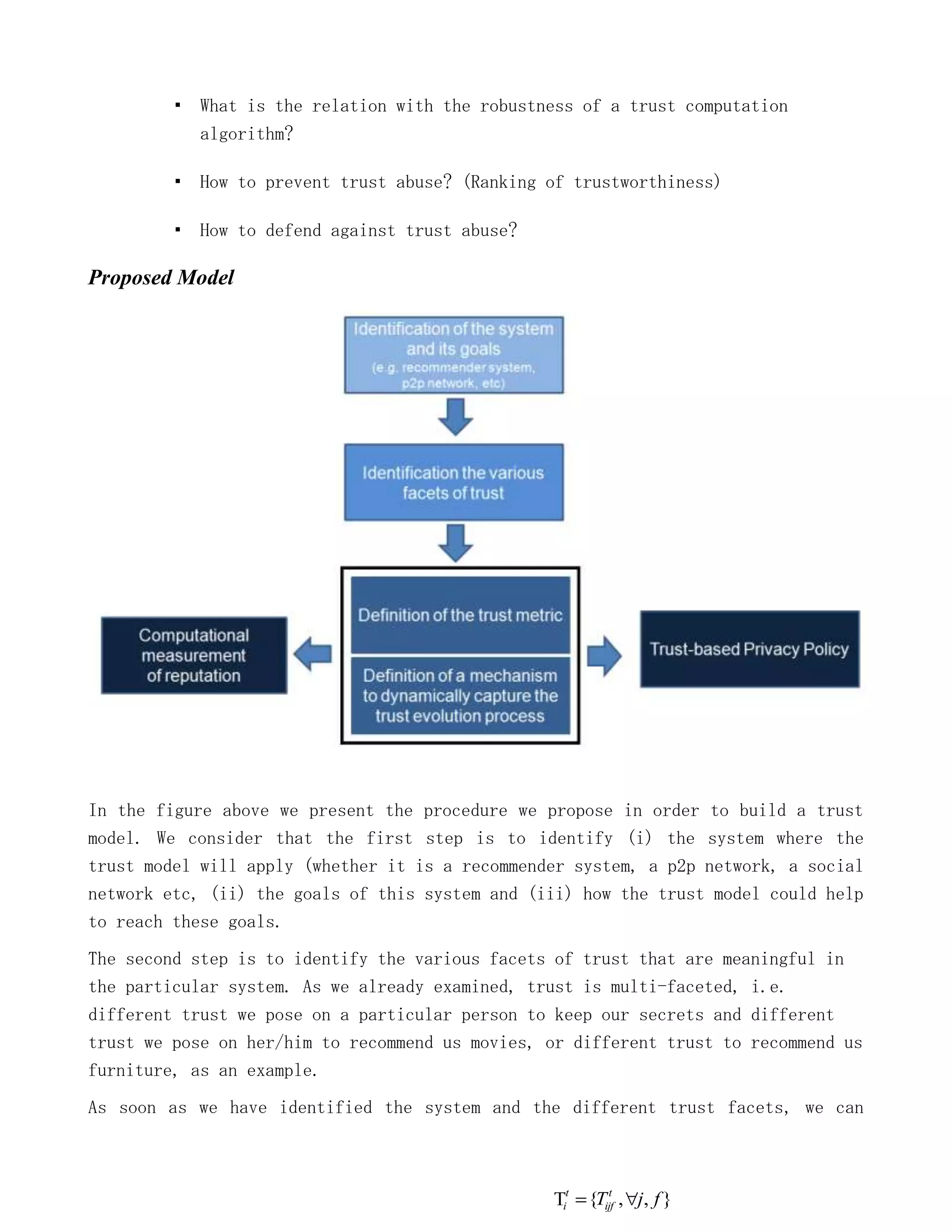


The document explores the relationship between trust in offline and online social interactions, aiming to map offline trust mechanisms to the online realm while considering factors of reputation and privacy. It calls for a multi-disciplinary investigation into how trust is built and evolved, as well as the unique challenges present in online contexts such as anonymity and data retention. The research poses several critical questions about the nature of trust and its dynamics across different platforms and suggests a model for understanding and measuring trust within specific systems.












































![[participants Communicating Privacy Risks to Users] EINS summer school](https://cdn.slidesharecdn.com/ss_thumbnails/participantscommunicatingprivacyriskstouserseinssummerschool-120817091954-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





































