Download as PDF, PPTX




![Dense Trajectories (DT) [Wang+, CVPR11]
• Trajectory-based representation
– A large amount of trajectories
– Feature description (HOG, HOF, MBH)
– Codeword vector is generated](https://image.slidesharecdn.com/161008eccv16bnmwslide-161009030000/85/ECCV-2016-BNMW-Human-Action-Recognition-without-Human-5-320.jpg)
![Two-Stream CNN [Simonyan+, NIPS14]
• Spatial and temporal convolution
– Spatial-stream: From a RGB image
– Temporal-stream: From a stacked flows
– Score fusion: Average or SVM](https://image.slidesharecdn.com/161008eccv16bnmwslide-161009030000/85/ECCV-2016-BNMW-Human-Action-Recognition-without-Human-6-320.jpg)
![Is background enough to classify actions?
• RGB input is too strong!
– The two-stream CNN[Simonyan+, NIPS14] reported spatial-stream can understand an
action more than expected
• 72.4% with spatial-stream (RGB) @UCF101
• “Human Action Recognition without Human”](https://image.slidesharecdn.com/161008eccv16bnmwslide-161009030000/85/ECCV-2016-BNMW-Human-Action-Recognition-without-Human-7-320.jpg)


![Framework
– Baseline: Very deep two-stream CNN [Wang+, arXiv15]
– Two different scenarios: without human and with human](https://image.slidesharecdn.com/161008eccv16bnmwslide-161009030000/85/ECCV-2016-BNMW-Human-Action-Recognition-without-Human-10-320.jpg)
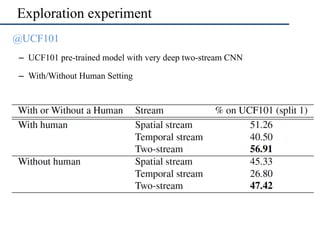





The document discusses human action recognition using motion representation techniques and compares systems with and without human presence in videos. Through experiments involving the UCF101 dataset, it reveals that a two-stream CNN can achieve significant accuracy even in the absence of human input, although human presence improves recognition. It emphasizes the need for improved motion representation systems focused solely on motion, highlighting the dependency of current methods on background information.
















































































