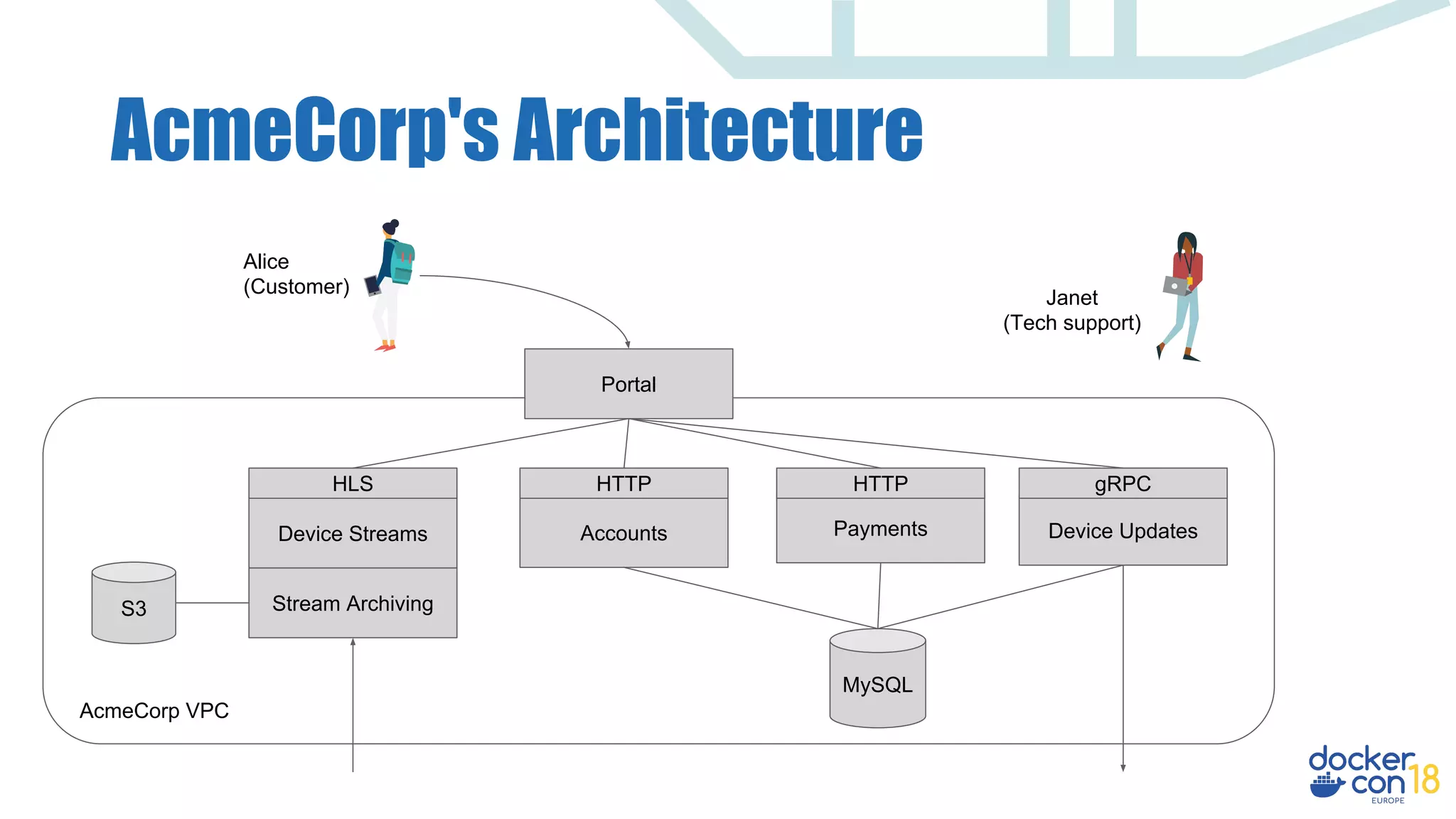
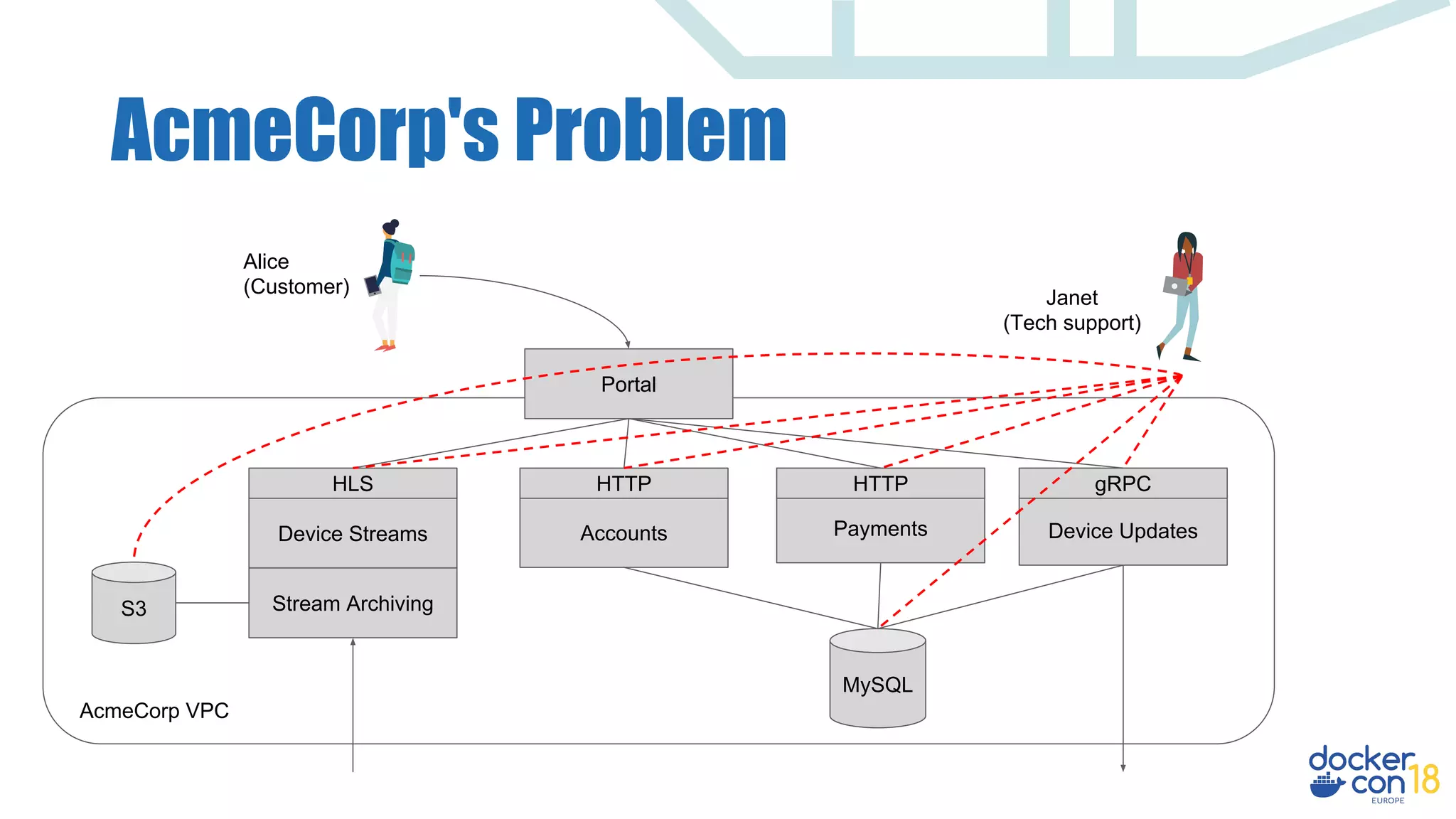
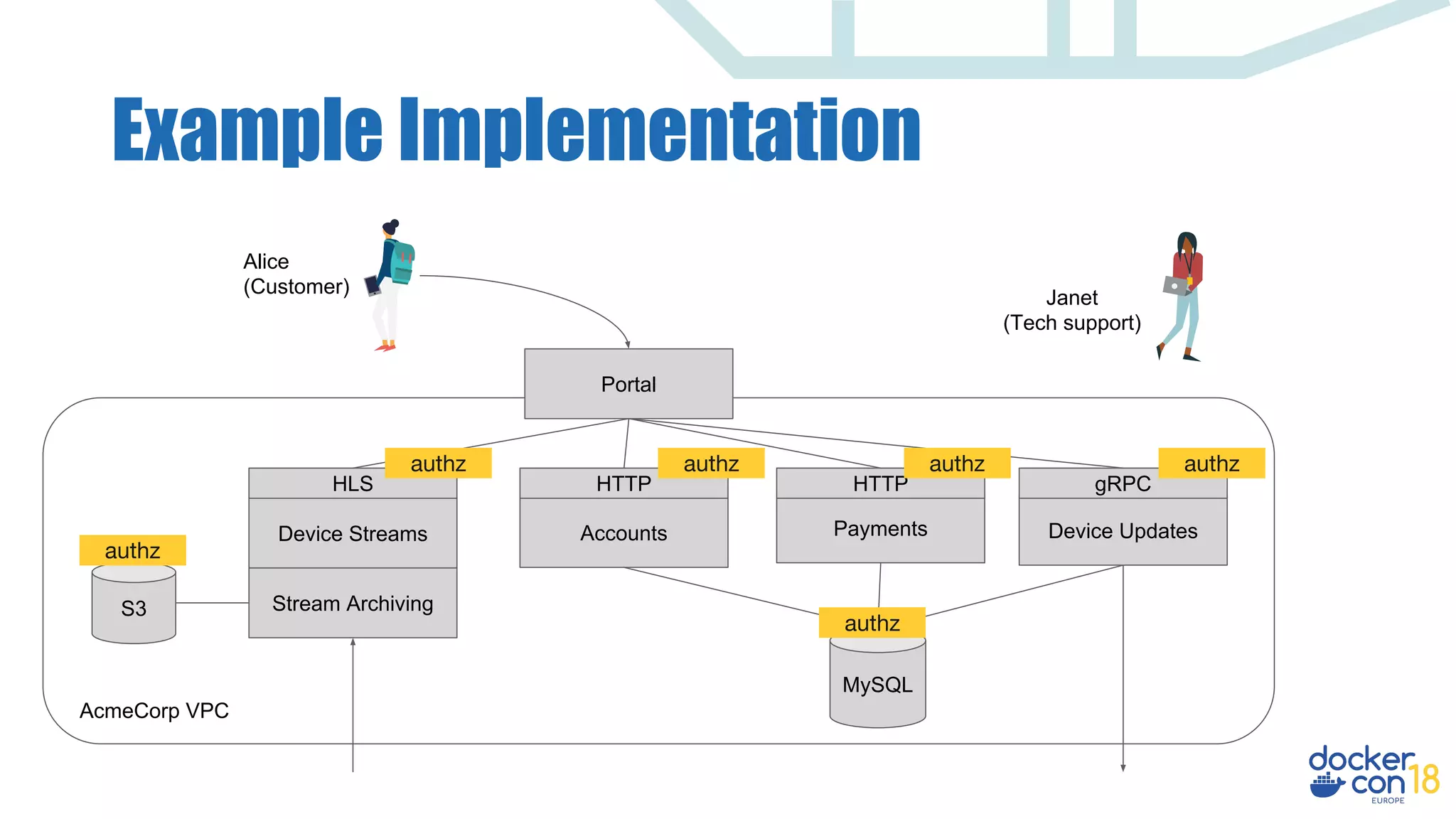
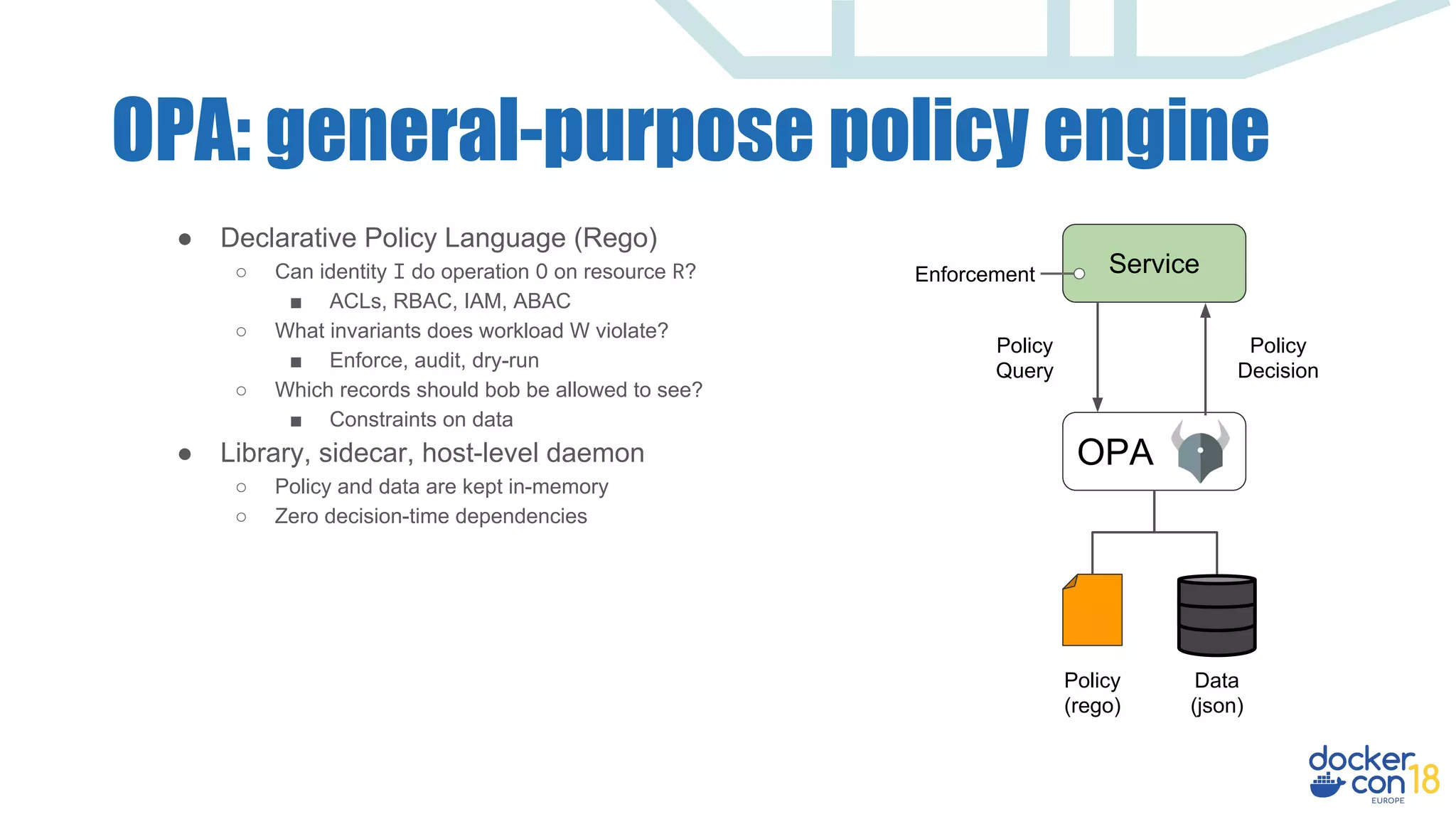
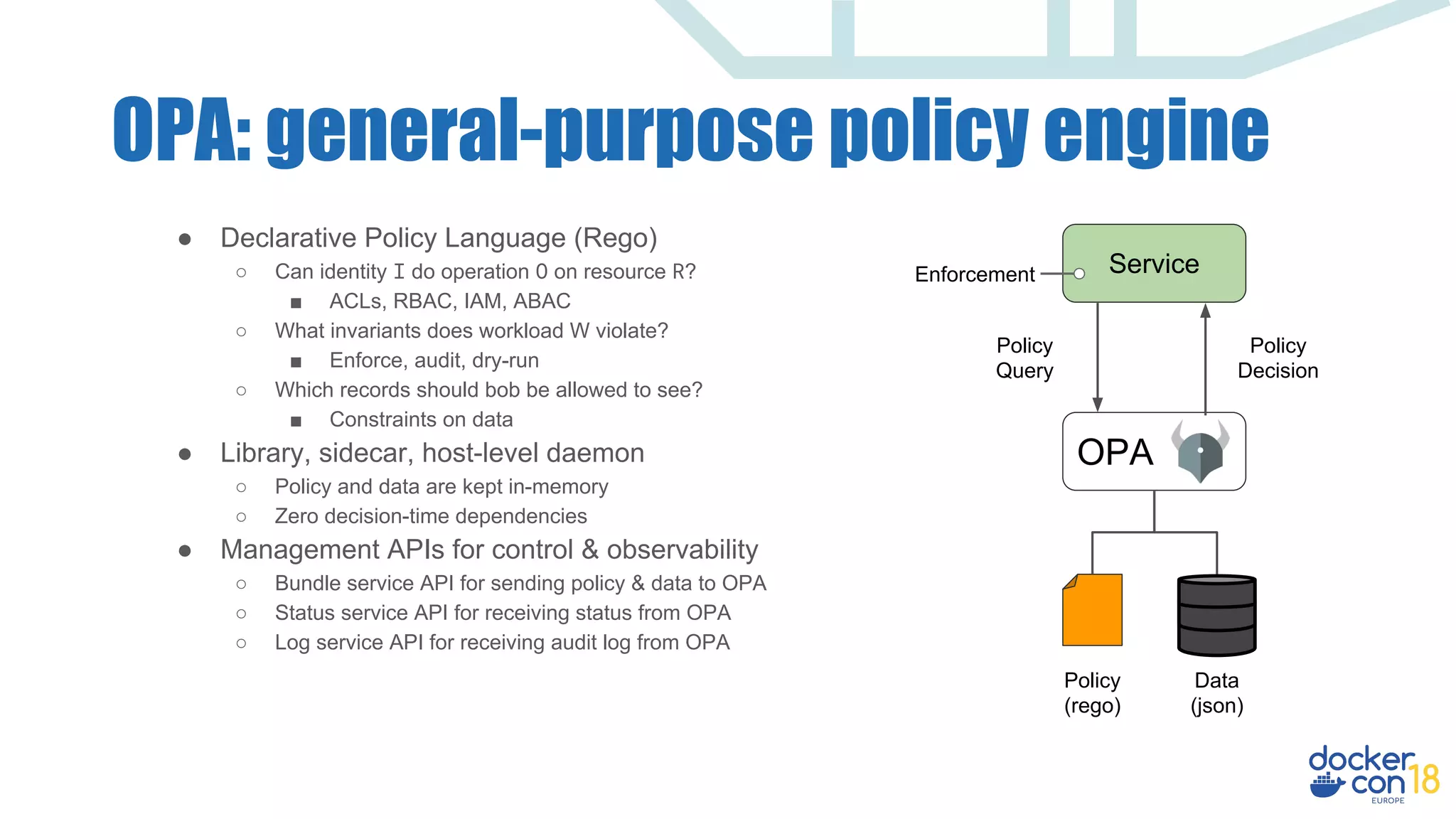
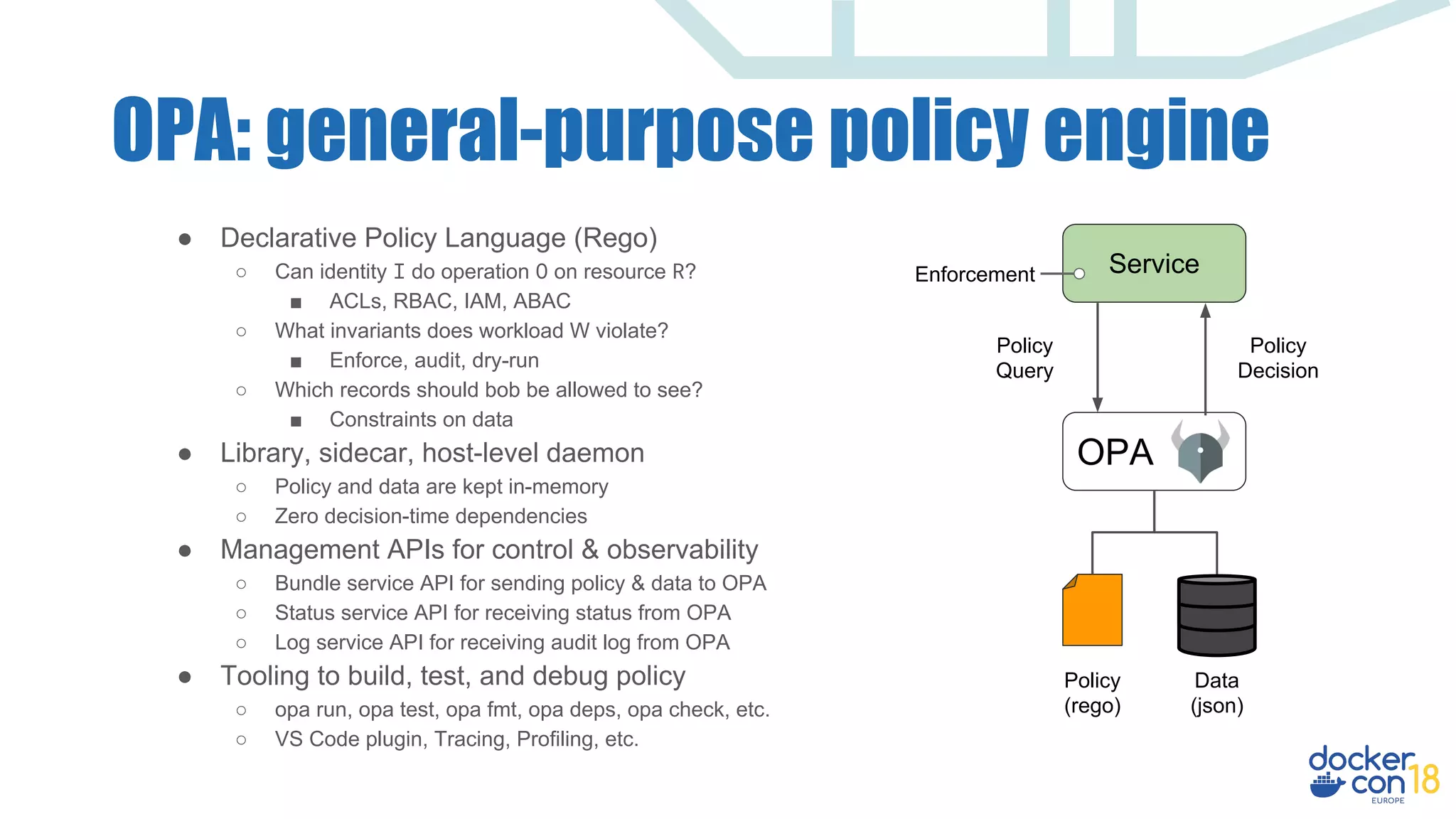
The document discusses dynamic authorization and policy control in Docker container environments, highlighting the challenges of heterogeneity and the need for effective policy enforcement. It introduces the Open Policy Agent (OPA), a general-purpose policy engine that aims to unify policy management across various systems and applications using a declarative policy language called Rego. The document provides real-life examples, use cases, and outlines how OPA can support enforcement, auditing, and testing of policies in a flexible and scalable manner.













![OPA: general-purpose policy engine
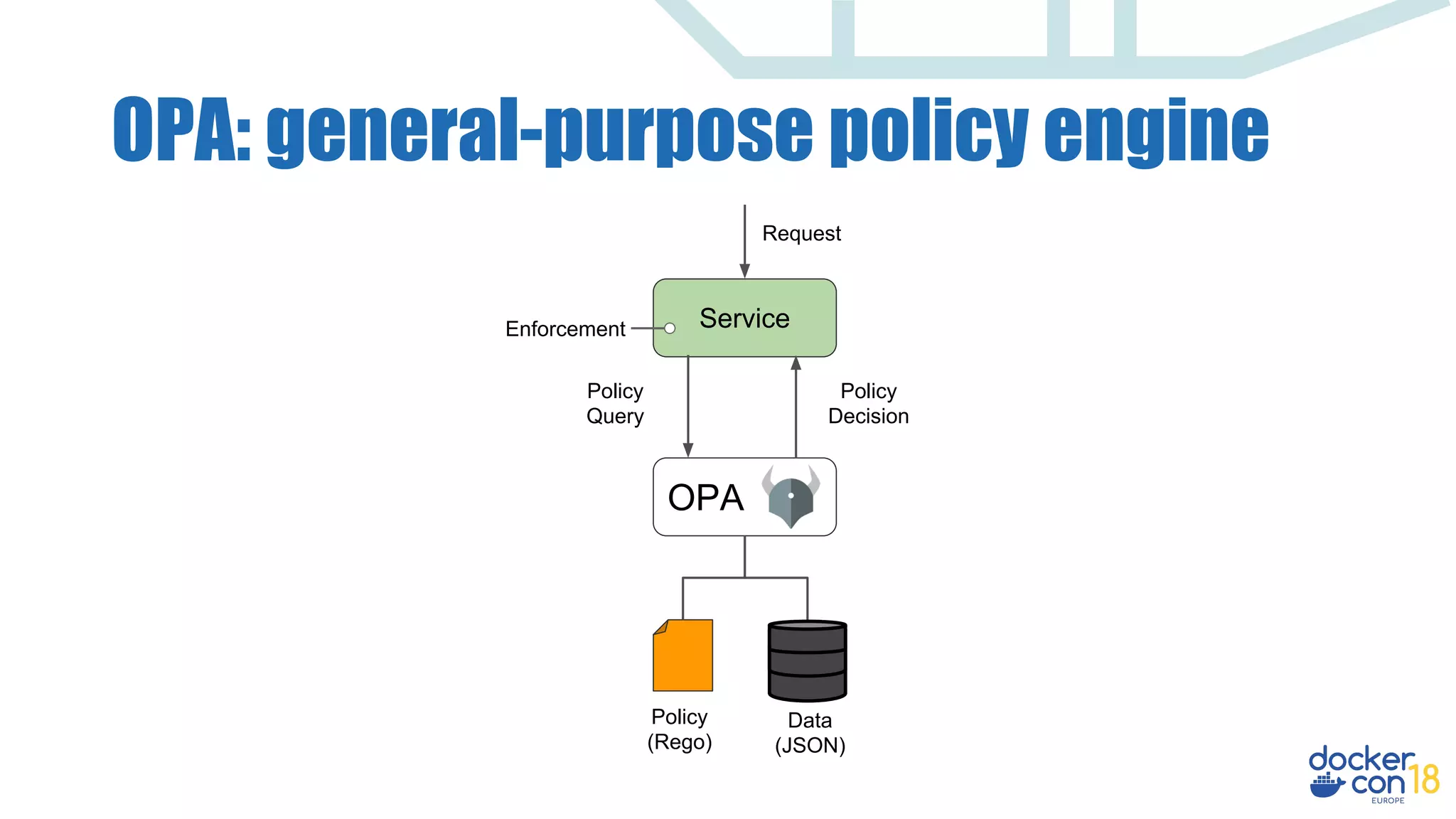
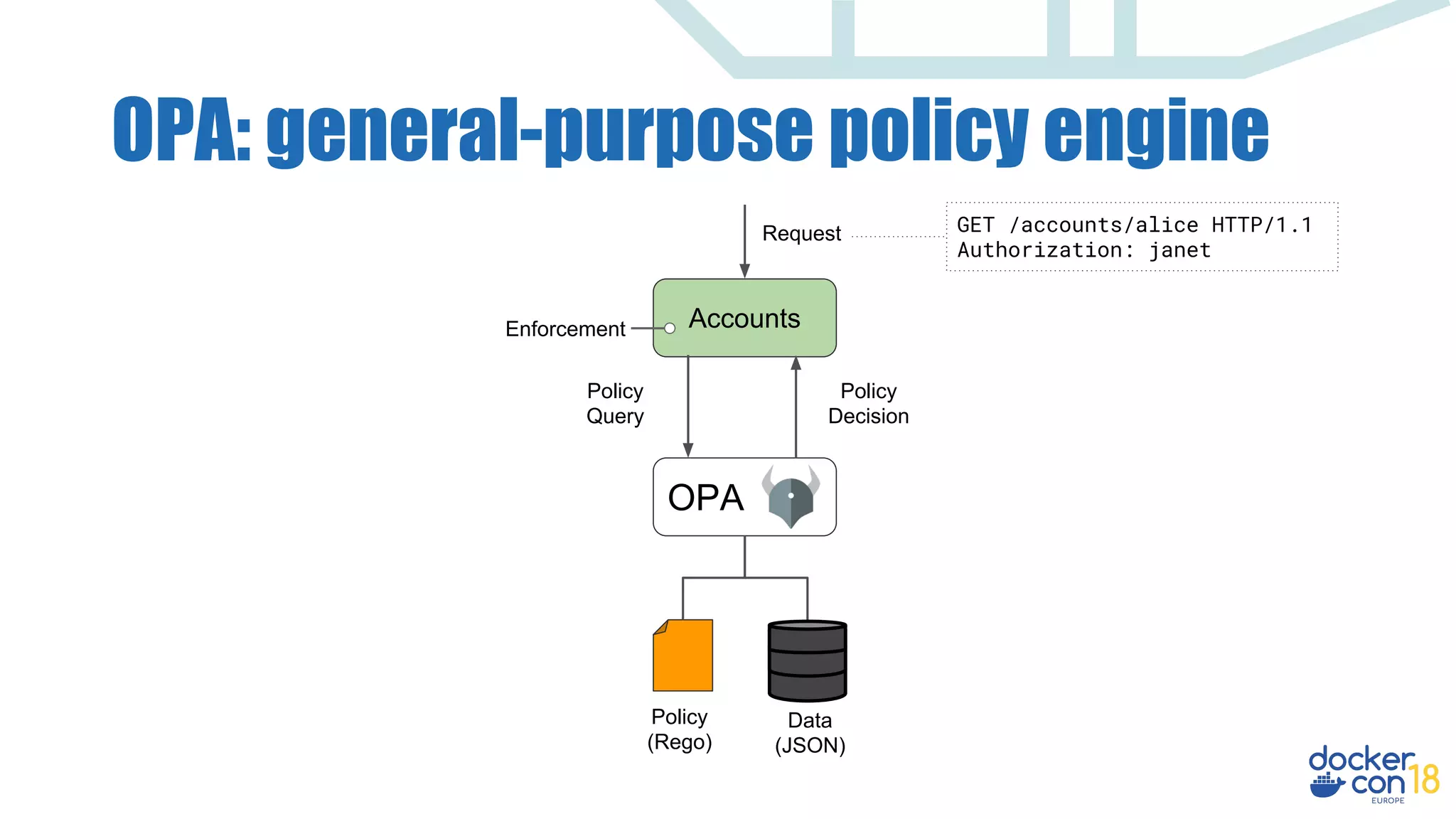
Accounts
OPA
Policy
(Rego)
Data
(JSON)
Policy
Query
Policy
Decision
Enforcement
Request GET /accounts/alice HTTP/1.1
Authorization: janet
{
"method": "GET",
"path": ["accounts", "alice"],
"user": "janet"
}
true or false](https://image.slidesharecdn.com/dynamicauthorizationandpolicycontrol-181204142027/75/Dynamic-Authorization-Policy-Control-for-Docker-Environments-20-2048.jpg)
![OPA: general-purpose policy engine
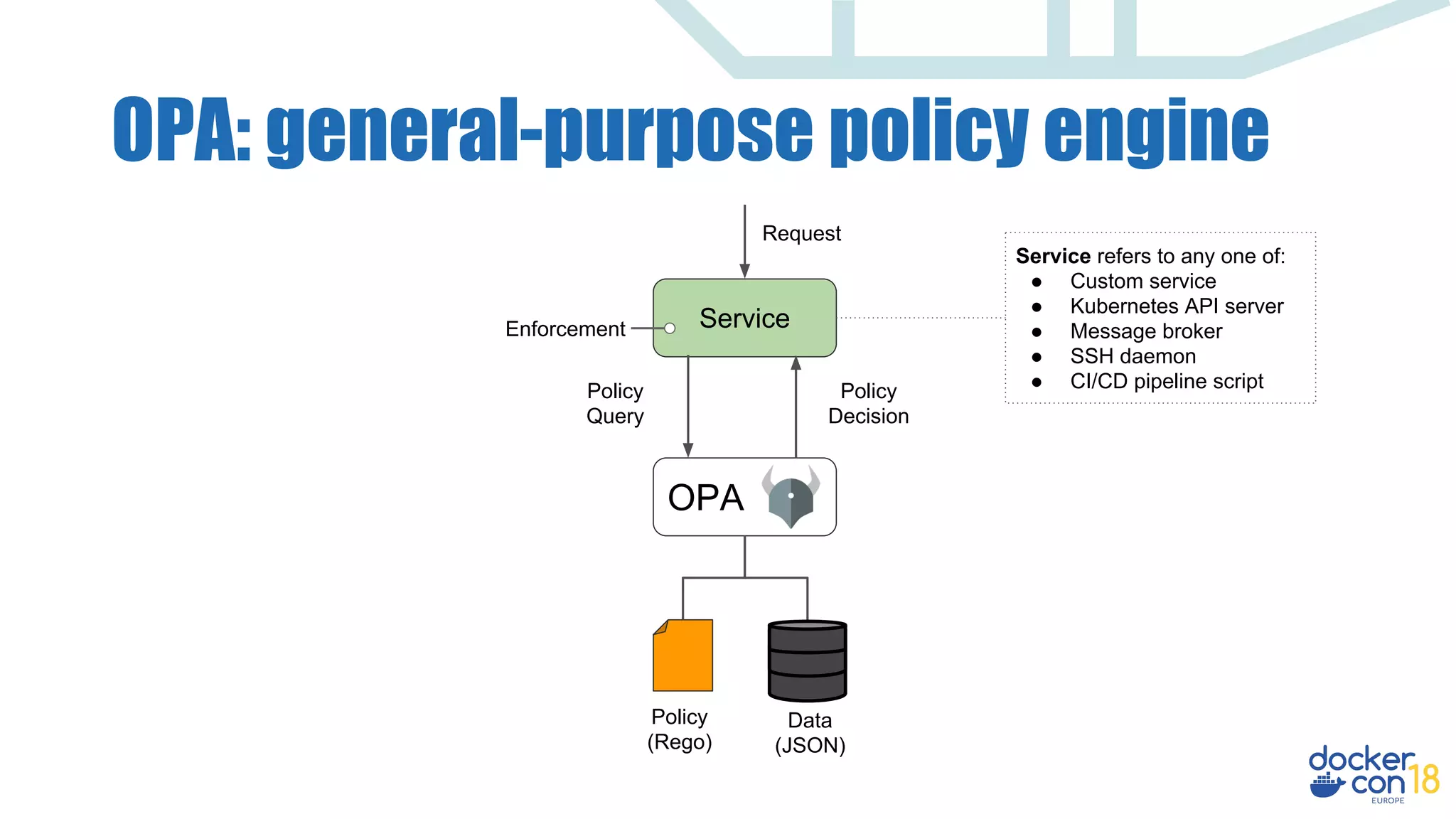
Service
OPA
Policy
(Rego)
Data
(JSON)
Policy
Query
Policy
Decision
Enforcement
Request
Service refers to any one of:
● Custom service
● Kubernetes API server
● Message broker
● SSH daemon
● CI/CD pipeline script
Input can be any JSON value:
"alice"
["v1", "users", "bob"]
{"kind": "Pod", "spec": …}
Output can be any JSON value:
true
"request rejected"
{"servers": ["web1", "web2"]}](https://image.slidesharecdn.com/dynamicauthorizationandpolicycontrol-181204142027/75/Dynamic-Authorization-Policy-Control-for-Docker-Environments-22-2048.jpg)








![Hands on example with OPA
Accounts
OPA Bundle
Server
Policy + Tickets
GET /accounts/alice HTTP/1.1
Authorization: Bearer ...
Input
{
method: GET
path: [accounts, alice]
subject: {
user: janet
groups: [support]
}
}
Result
true (allow) or false (deny)
Data
{
tickets: {
alice: [
{assignee: janet},
{assignee: bob}
],
ken: [
{assignee: janet}
]
}
}](https://image.slidesharecdn.com/dynamicauthorizationandpolicycontrol-181204142027/75/Dynamic-Authorization-Policy-Control-for-Docker-Environments-35-2048.jpg)
![Hands on example with OPA
Input
{
method: GET
path: [accounts, alice]
subject: {
user: janet
groups: [support]
}
}
Data
{
tickets: {
alice: [
{assignee: janet}
]
}
}
package acmecorp.authz
default allow = false
allow = true {
input.method = "GET"
input.path = ["accounts", id]
input.subject.groups[_] = "support"
input.subject.user = data.tickets[id][_].assignee
}](https://image.slidesharecdn.com/dynamicauthorizationandpolicycontrol-181204142027/75/Dynamic-Authorization-Policy-Control-for-Docker-Environments-36-2048.jpg)

![allow {
input.action = "UpdateDevice"
input.subject.groups[_] = "support"
inside_business_hours
}
inside_business_hours {
[hour, minute, second] = time.clock(time.now_ns())
time_of_day = (hour * seconds_per_hour) + (minute * seconds_per_minute) + second
time_of_day >= 10 * seconds_per_hour
time_of_day <= 15 * seconds_per_hour
}
seconds_per_hour = 60 * 60
seconds_per_minute = 60
Example Policy++](https://image.slidesharecdn.com/dynamicauthorizationandpolicycontrol-181204142027/75/Dynamic-Authorization-Policy-Control-for-Docker-Environments-38-2048.jpg)

![Kubernetes Admission Policy
package kubernetes.admission
import data.kubernetes.storageclasses
reclaim_exceptions = {"payments", "clickstream"}
# Generate an admission control violation error if...
deny["invalid reclaim policy requested by app"] {
# Input object is a PVC and ...
input.kind = "PersistentVolumeClaim"
# StorageClass specifies the "Retain" reclaim policy and...
name = input.spec.storageClassName
storageclasses[name].reclaimPolicy = "Retain"
# The app that owns the PVC is not whitelisted.
not reclaim_exceptions[input.labels["app"]]
}](https://image.slidesharecdn.com/dynamicauthorizationandpolicycontrol-181204142027/75/Dynamic-Authorization-Policy-Control-for-Docker-Environments-40-2048.jpg)
















































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)


![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)





