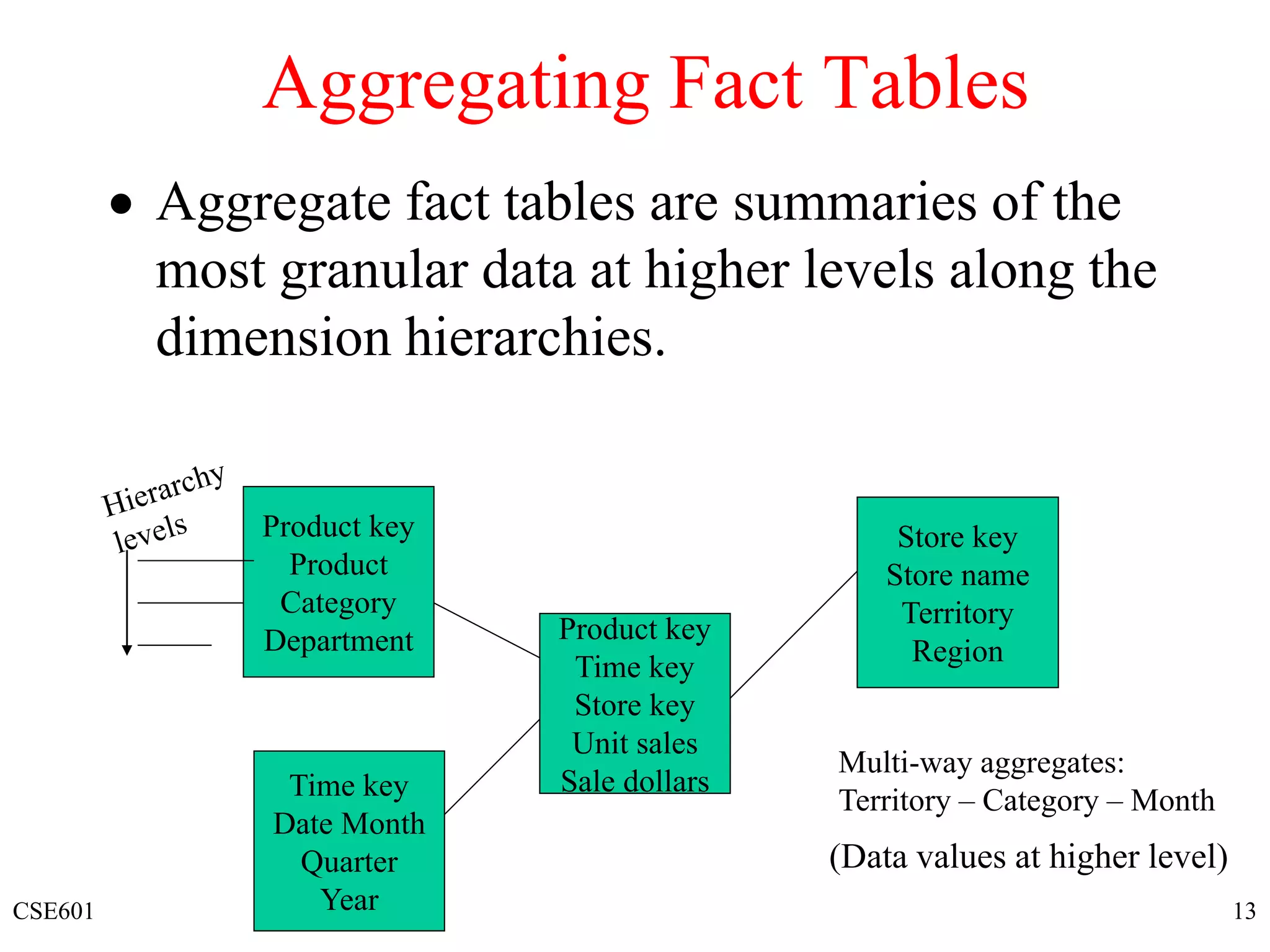
This document discusses multidimensional data models and cube operations. It introduces key concepts like facts and measures, dimensions and hierarchies. It describes star and snowflake schemas for structuring multidimensional data in a relational database. The document also covers cube operations like roll-up, drill-down, slice and dice that allow interactive analysis of aggregated data across multiple dimensions.