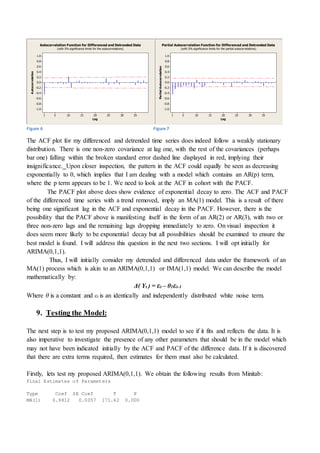
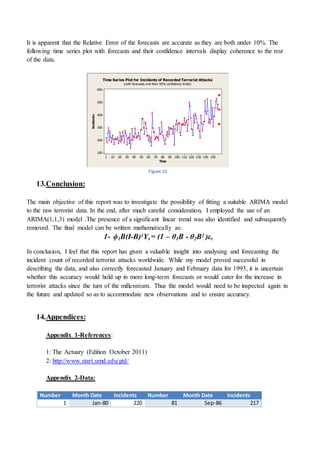
This document summarizes a time series analysis project investigating recorded terrorist attacks worldwide from January 1980 to January 1993. The analysis aimed to identify an appropriate ARIMA (Autoregressive Integrated Moving Average) model that could be used as a forecasting tool. The data was obtained from the Global Terrorism Database and contained 157 monthly observations over the 13 year period. Preliminary analysis found the time series was non-stationary, displaying an increasing trend over time. Differencing was identified as needed to remove the trend and achieve stationarity before identifying the optimal ARIMA model parameters. The results could help risk managers predict future terrorist attack frequencies to inform insurance liability calculations.