The document presents a talk by Gaurav Bahrani and Shanker Balan on designing for operability and manageability in the context of building intelligent search engines and DevOps practices. Key topics include architecture challenges, infrastructure management, build and release processes, security and compliance, as well as design and architecture best practices for scalable systems. The focus is on employing standardized systems, metrics for availability, and effective team structures to enhance operational efficiency in software development.




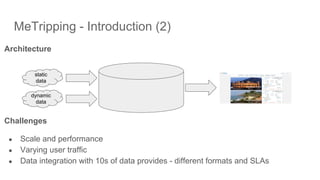










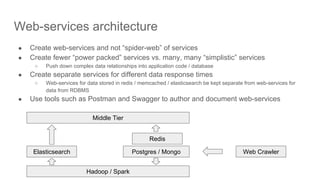

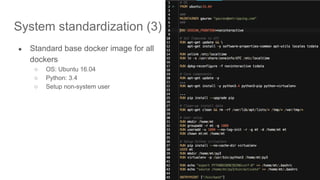








!["Smooth Operator" [Bay Area NewSQL meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/bayareanewsqlmeetuptidboperator-190222181157-thumbnail.jpg?width=640&height=640&fit=bounds)































































