Download as PDF, PPTX







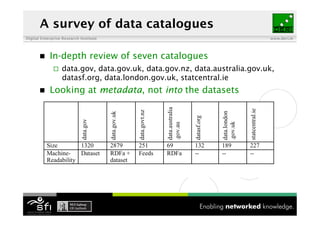
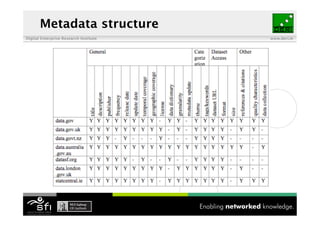
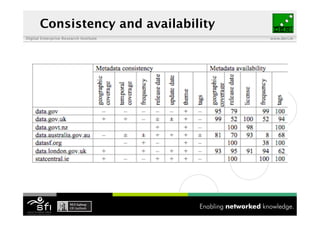
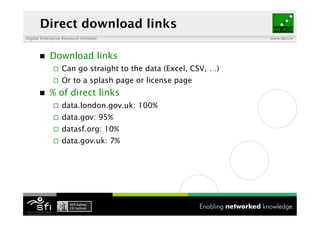



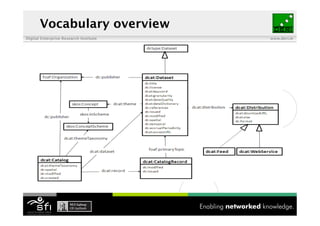






The document discusses the importance of interoperability among data catalogues and presents the DCAT vocabulary as a standard for enhancing this interoperability. It outlines the current state of various data catalogues, identifies challenges related to metadata consistency and access, and details early experiments with integrated catalogue data. The document concludes with plans for further development and engagement with the community to enhance the DCAT standard.











































































