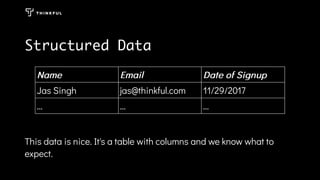
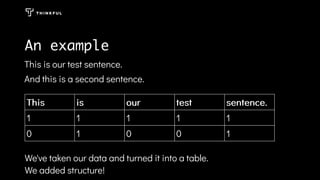
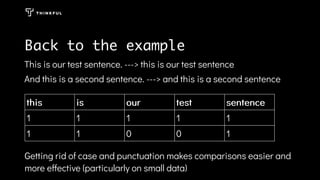
Using data science techniques like natural language processing, a random forest model can be built to analyze hotel reviews and descriptions of dream vacations to provide personalized vacation recommendations. The model analyzes text data by converting it into structured bag-of-words representations after preprocessing like removing stop words and case. This allows building a model to predict good vacation matches despite challenges like relative word frequencies and lack of context in the text.