Download to read offline















![Opinion formation
• The value propagation can be used as a model of opinion formation.
• Model:
• Opinions are values in [-1,1]
• Every user 𝑢 has an internal opinion 𝑠𝑢, and expressed opinion 𝑧𝑢.
• The expressed opinion minimizes the personal cost of user 𝑢:
𝑐 𝑧𝑢 = 𝑠𝑢 − 𝑧𝑢
2
+
𝑣:𝑣 is a friend of 𝑢
𝑤𝑢 𝑧𝑢 − 𝑧𝑣
2
• Minimize deviation from your beliefs and conflicts with the society
• If every user tries independently (selfishly) to minimize their personal
cost then the best thing to do is to set 𝑧𝑢to the average of all opinions:
𝑧𝑢 =
𝑠𝑢 + 𝑣:𝑣 is a friend of 𝑢 𝑤𝑢𝑧𝑢
1 + 𝑣:𝑣 is a friend of 𝑢 𝑤𝑢
• This is the same as the value propagation we described before!](https://image.slidesharecdn.com/datamininglecture13-230924165916-02c80e34/75/Data-Mining-Lecture_13-pptx-17-2048.jpg)




























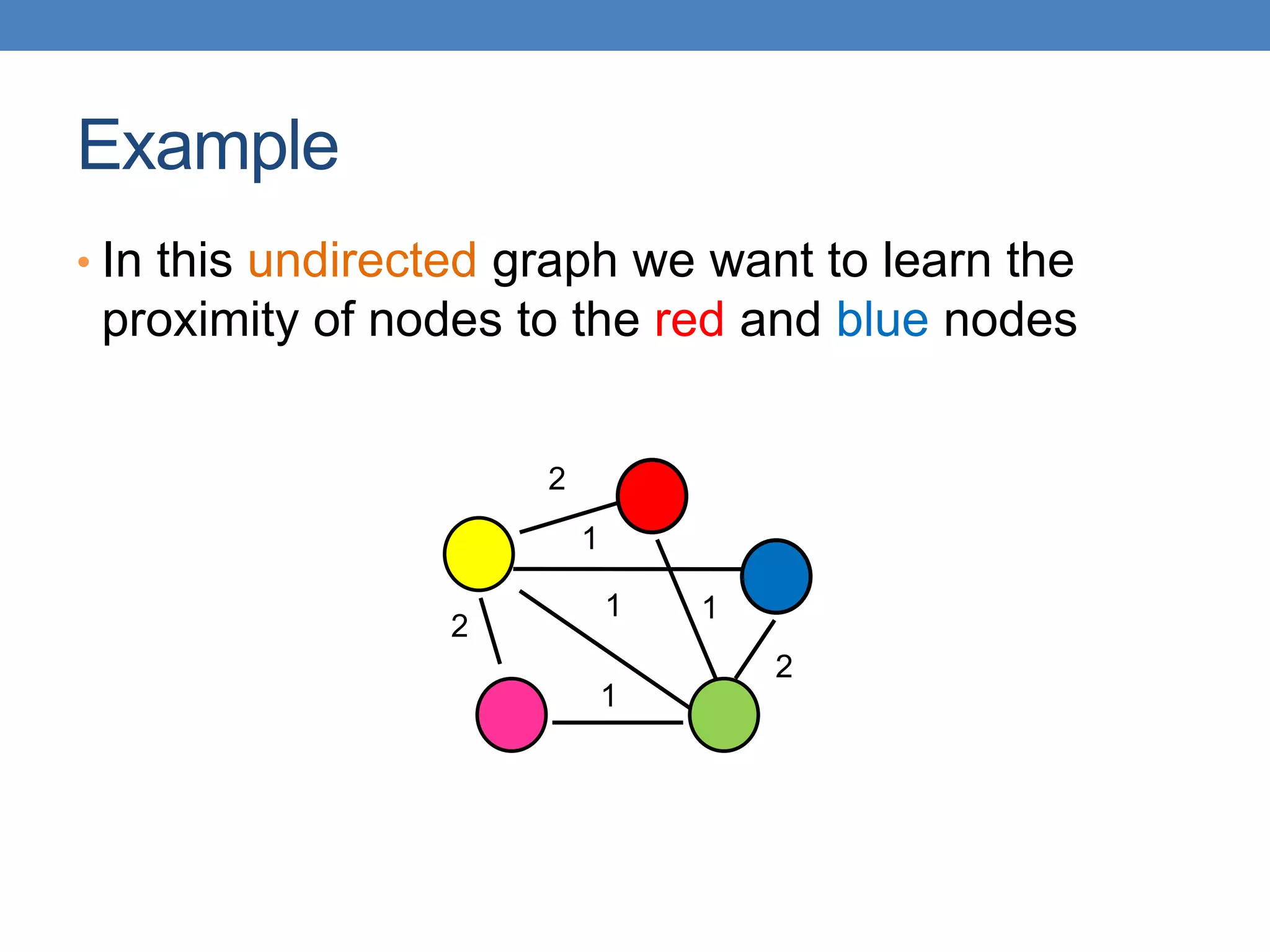
This document discusses absorbing random walks on graphs. It explains that absorbing random walks can be used to compute the proximity of non-absorbing nodes to chosen absorbing nodes in a graph. The absorption probabilities provide a measure of how close each non-absorbing node is to the different absorbing nodes. These probabilities can be computed by iteratively updating the absorption probabilities of each non-absorbing node based on the probabilities of its neighbors. Absorbing random walks have applications in areas like information propagation, opinion formation, and semi-supervised learning.



































































