Download as PDF, PPTX























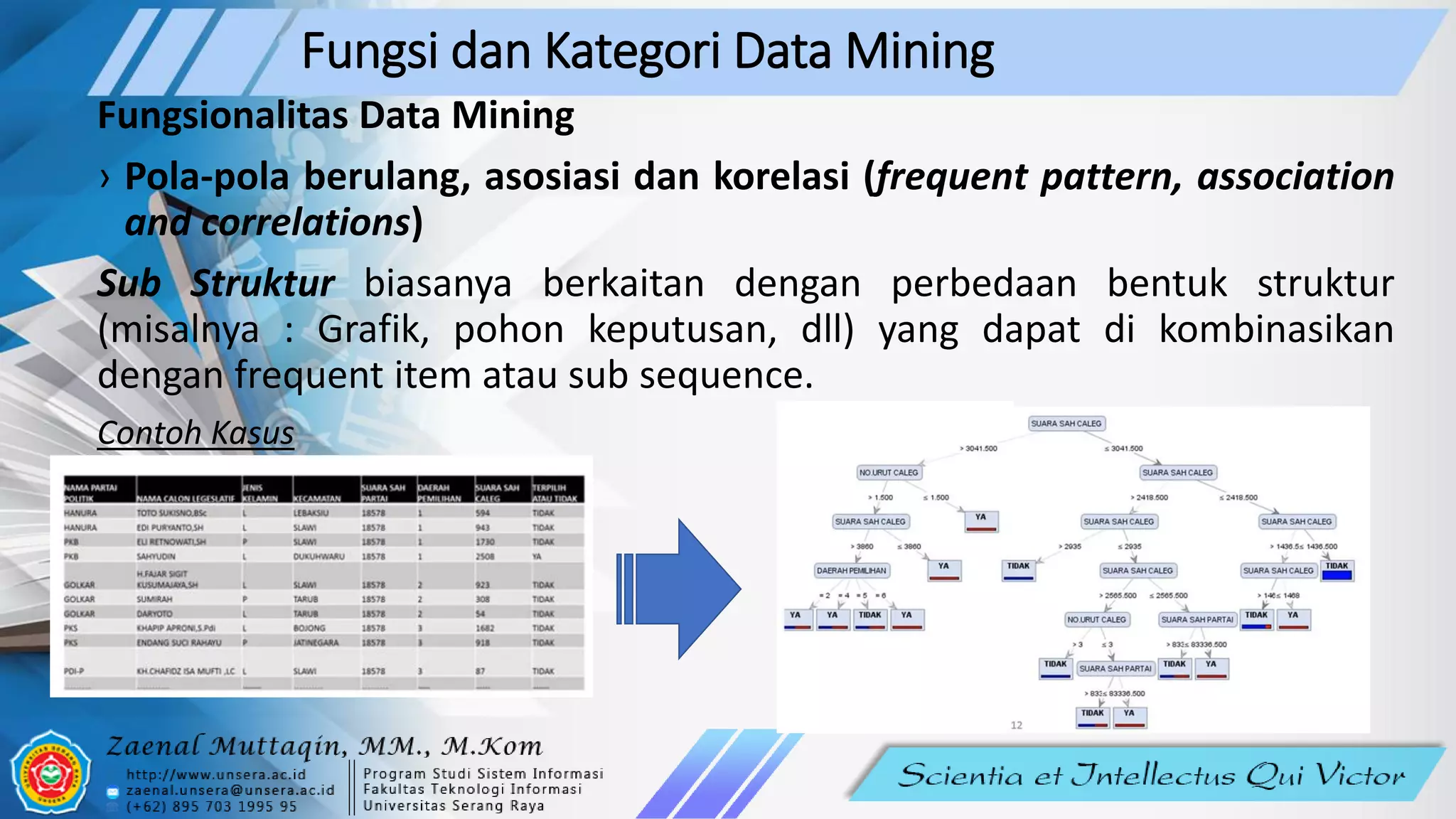

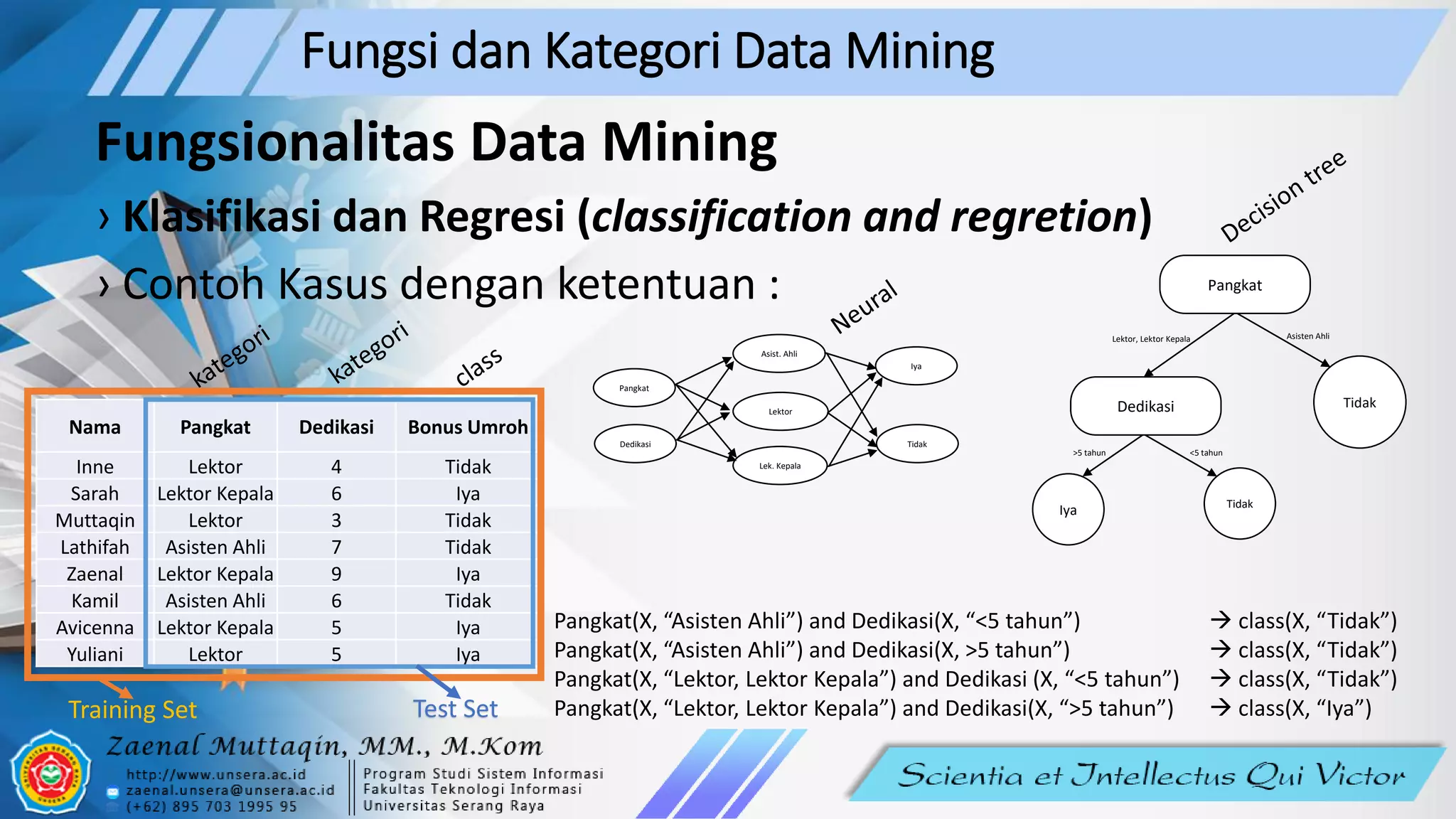





Dokumen ini membahas konsep dan fungsi data mining, menyoroti pentingnya analisis data besar untuk menemukan pola dan pengetahuan. Data mining dibagi menjadi kategori deskriptif dan prediktif, serta memiliki fungsionalitas seperti klasifikasi, regresi, dan analisis kluster. Pemrosesan data yang efektif dapat membantu perusahaan dalam pengambilan keputusan yang lebih baik.

































































