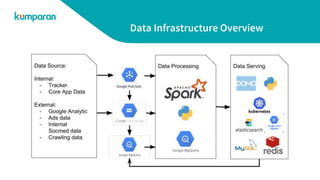
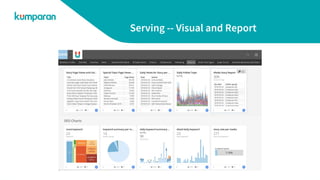
The document provides an overview of Kumparan's data infrastructure. It describes their ETL process of moving data from sources to a data lake (Google Cloud Storage) and data warehouse (BigQuery). It also discusses how they process data using BigQuery, Python, and Dataproc. Processed data is then served from databases like Elasticsearch, Bigtable, MySQL, and Redis. Visualizations and reports are generated in DOMO. Examples of use cases like visualization, recommendation, spam detection, and trend prediction are also outlined.












































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)




![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)



