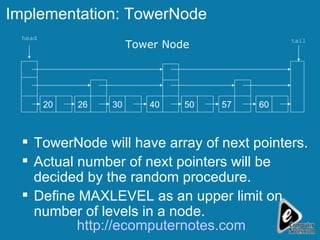
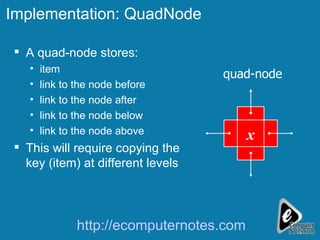
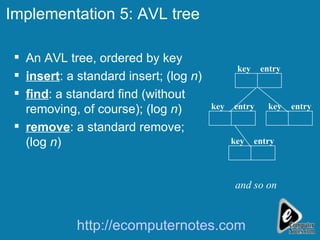
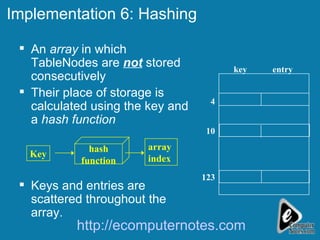
The document discusses various data structures including skip lists, AVL trees, and hashing techniques. It explains implementations such as tower nodes and quad nodes, and highlights the performance benefits of skip lists, noting their expected logarithmic time complexity for search, insertion, and deletion operations. Additionally, it covers hashing methods, emphasizing the importance of an efficient hash function and the use of prime numbers for table sizes to optimize data storage.









![Example Store data in a table array: table[5] = "apple" table[3] = "watermelon" table[8] = "grapes" table[7] = "cantaloupe" table[0] = "kiwi" table[9] = "strawberry" table[6] = "mango" table[2] = "banana" http://ecomputernotes.com kiwi banana watermelon apple mango cantaloupe grapes strawberry 0 1 2 3 4 5 6 7 8 9](https://image.slidesharecdn.com/computernotes-datastructures-35-111227204756-phpapp01/85/Computer-notes-Hashing-13-320.jpg)
![Example Associative array: table["apple"] table["watermelon"] table["grapes"] table["cantaloupe"] table["kiwi"] table["strawberry"] table["mango"] table["banana"] http://ecomputernotes.com kiwi banana watermelon apple mango cantaloupe grapes strawberry 0 1 2 3 4 5 6 7 8 9](https://image.slidesharecdn.com/computernotes-datastructures-35-111227204756-phpapp01/85/Computer-notes-Hashing-14-320.jpg)
![Example Hash Functions If the keys are strings the hash function is some function of the characters in the strings. One possibility is to simply add the ASCII values of the characters: TableSize ABC h Example TableSize i str str h length i )% 67 66 65 ( ) ( : % ] [ ) ( 1 0 http://ecomputernotes.com](https://image.slidesharecdn.com/computernotes-datastructures-35-111227204756-phpapp01/85/Computer-notes-Hashing-15-320.jpg)
![Finding the hash function int hashCode( char* s ) { int i, sum; sum = 0; for(i=0; i < strlen(s); i++ ) sum = sum + s[i]; // ascii value return sum % TABLESIZE; } http://ecomputernotes.com](https://image.slidesharecdn.com/computernotes-datastructures-35-111227204756-phpapp01/85/Computer-notes-Hashing-16-320.jpg)
![Example Hash Functions Another possibility is to convert the string into some number in some arbitrary base b ( b also might be a prime number): T b b b ABC h Example T b i str str h length i i )% 67 66 65 ( ) ( : % ] [ ) ( 2 1 0 1 0 http://ecomputernotes.com](https://image.slidesharecdn.com/computernotes-datastructures-35-111227204756-phpapp01/85/Computer-notes-Hashing-17-320.jpg)































































































