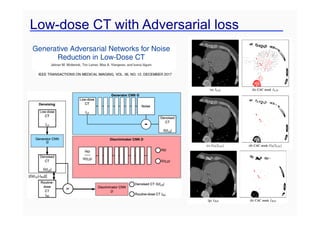
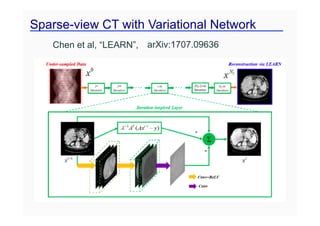
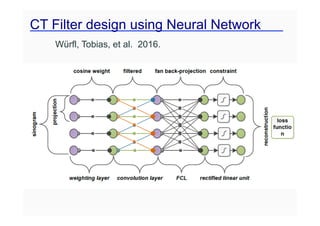
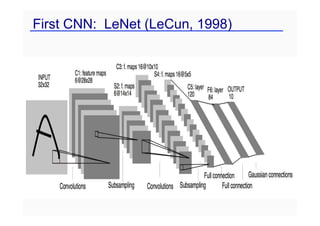
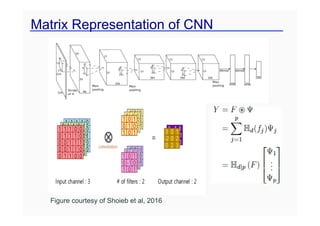
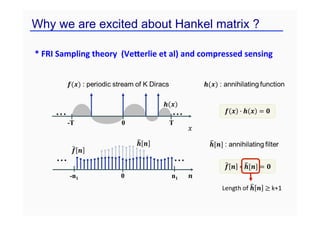
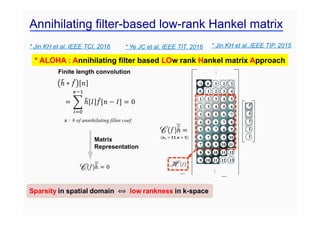
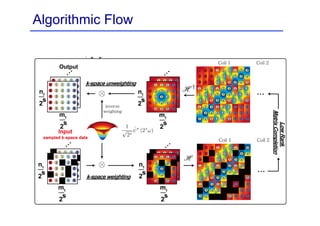
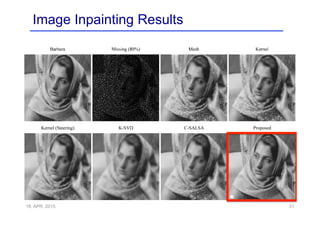
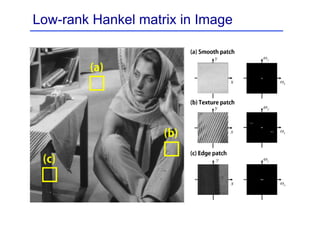
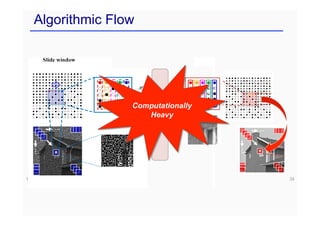
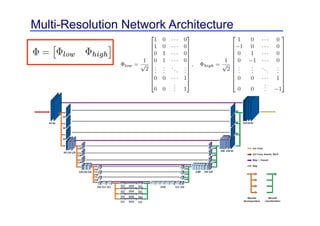
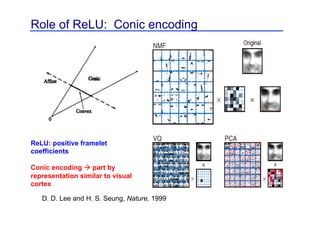
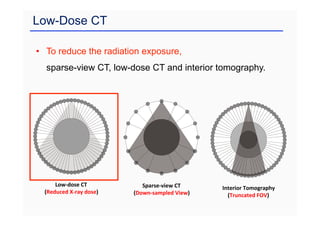
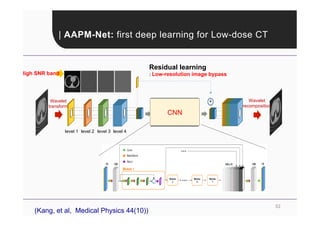
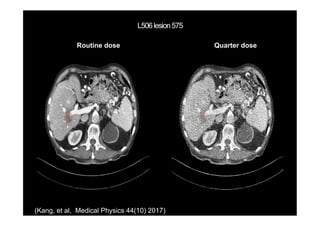
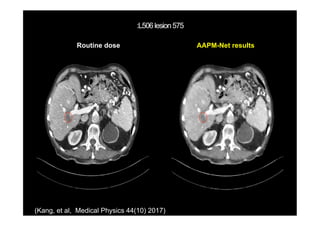
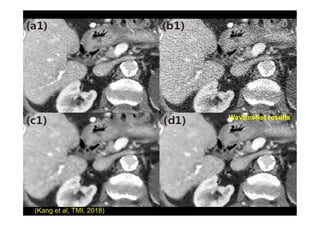
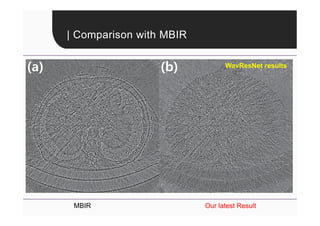
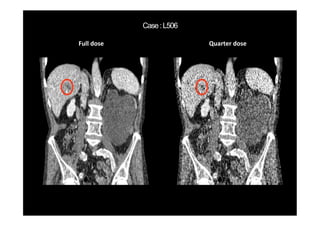
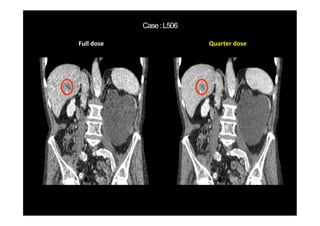
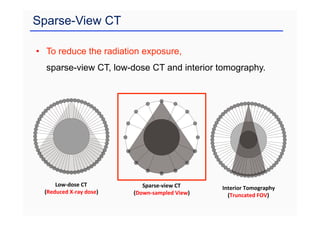
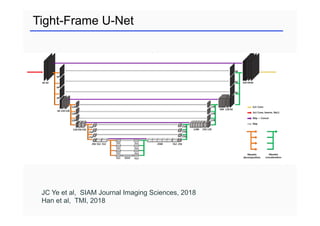
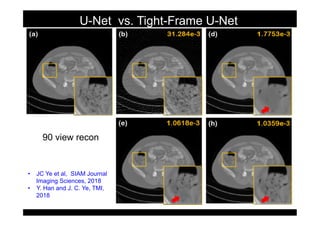
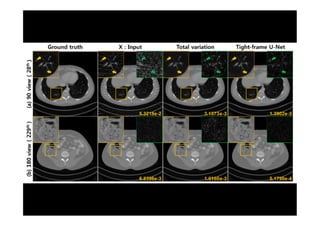
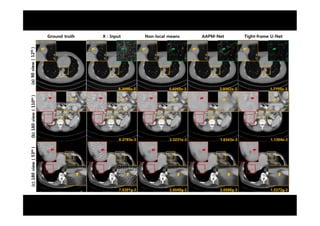
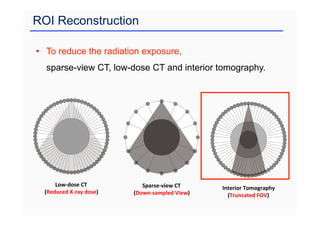
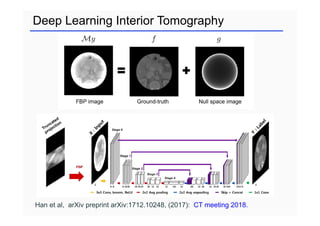
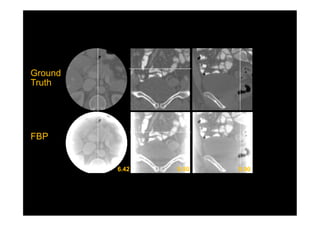
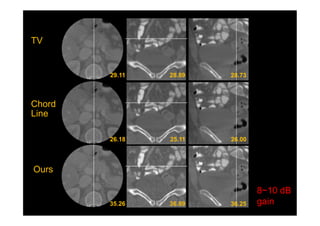
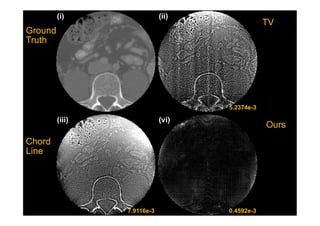
This document provides an overview of a refresher course on deep learning for CT reconstruction. The course covers an introduction to CNNs, the biological and mathematical origins of deep learning, and various applications of deep learning to CT reconstruction problems like low-dose CT, sparse-view CT, and interior tomography. Successful demonstrations of deep learning approaches for these image reconstruction problems are highlighted from recent works. The role of convolutional and pooling layers in CNNs is discussed. Reasons for why deep learning works well for reconstruction problems are explored, including the mathematical understanding of CNNs in terms of deep convolutional framelets and the lifting of signals to higher dimensional spaces using Hankel matrices. The document concludes by discussing some open problems and providing information on datasets















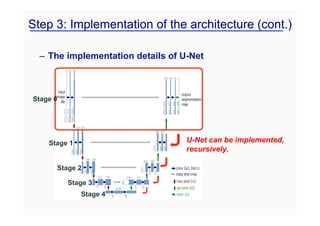
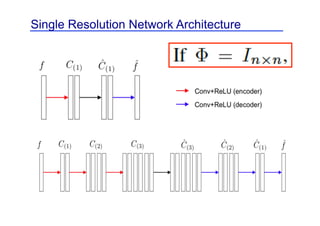
![Hd(f) Hd(f)
= ˜T
˜ T C
C = T
Hd(f)
C = T
(f ~ )
Encoder:
˜ T
= I
˜ = PR(V )
Hd(f) = U⌃V T
Unlifting: f = (˜C) ~ ⌧(˜)
: Non-local basis
: Local basis
: Frame condition
: Low-rank condition
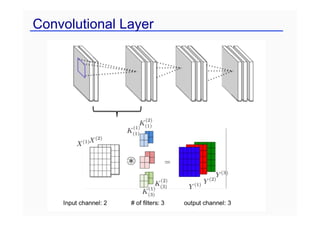
convolution
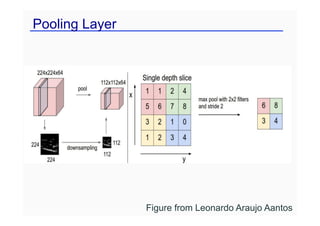
pooling
un-pooling
convolution
: User-defined pooling
: Learnable filters
Hpi
(gi) =
X
k,l
[Ci]kl
e
Bkl
i
Decoder:
Deep Convolutional Framelets (Y, Han, Cha; 2018)](https://image.slidesharecdn.com/ctmeetingfinaljcy1-230413065757-0d8c59e4/85/ct_meeting_final_jcy-1-pdf-37-320.jpg)










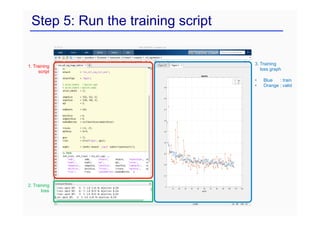
![Step 2: Prepare dataset
As a classification example, MNIST consists of as follows,
Images % struct-type
Data % handwritten digit image
labels % [1, …, 10]
set % [1, 2, 3],
1, 2, and 3 indicate
train, valid, and test set, respectively.
Data Labels
6](https://image.slidesharecdn.com/ctmeetingfinaljcy1-230413065757-0d8c59e4/85/ct_meeting_final_jcy-1-pdf-81-320.jpg)
![Step 2: Prepare dataset (cont.)
• As a segmentation example, U-Net dataset consists of as follows,
– Images % struct-type
Ø data % Cell image
Ø labels % [1, 2], Mask image.
1 and 2 indicate
back- and for-ground, respectively.
Ø set % [1, 2, 3]
Data Labels](https://image.slidesharecdn.com/ctmeetingfinaljcy1-230413065757-0d8c59e4/85/ct_meeting_final_jcy-1-pdf-82-320.jpg)