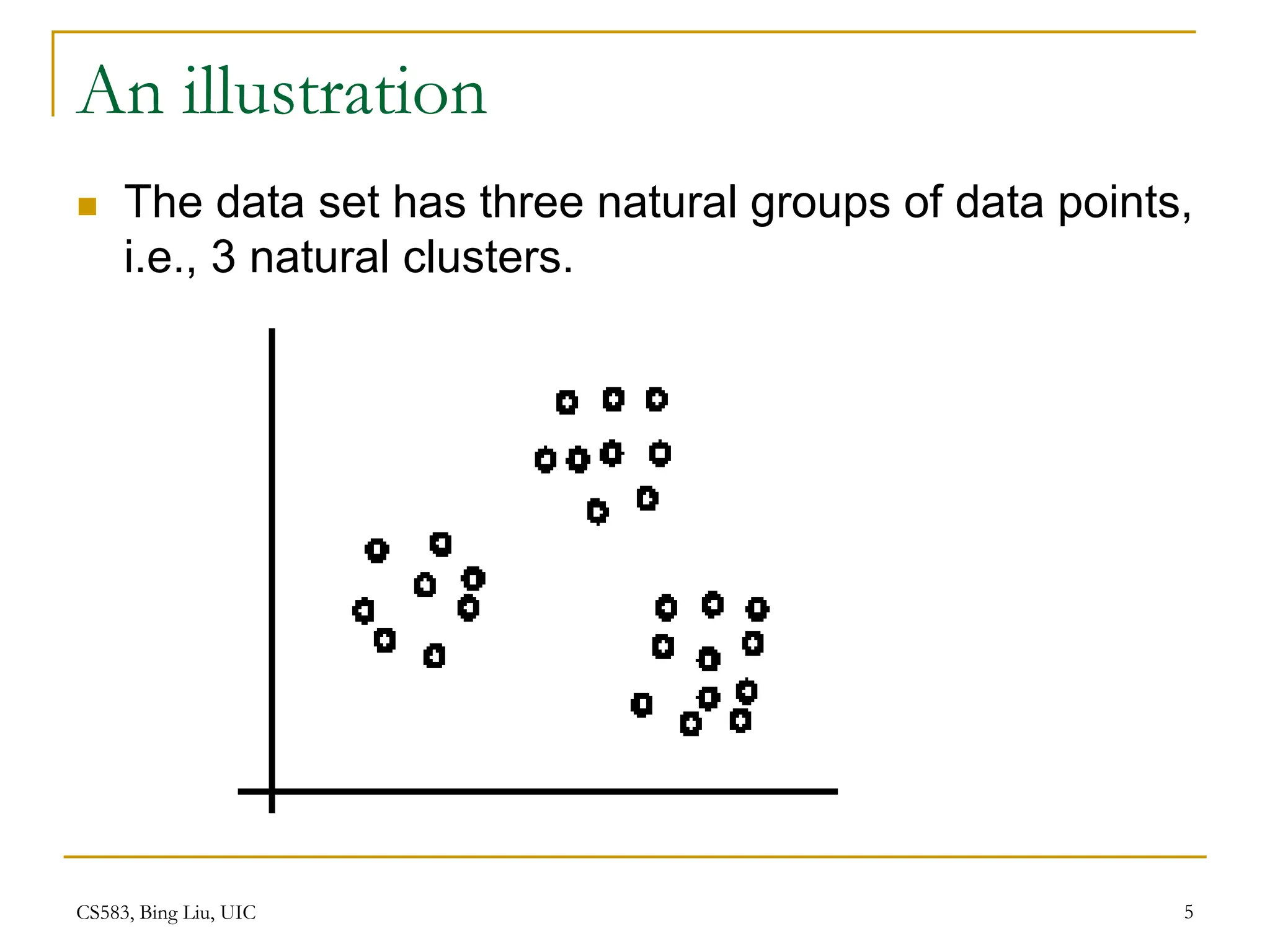
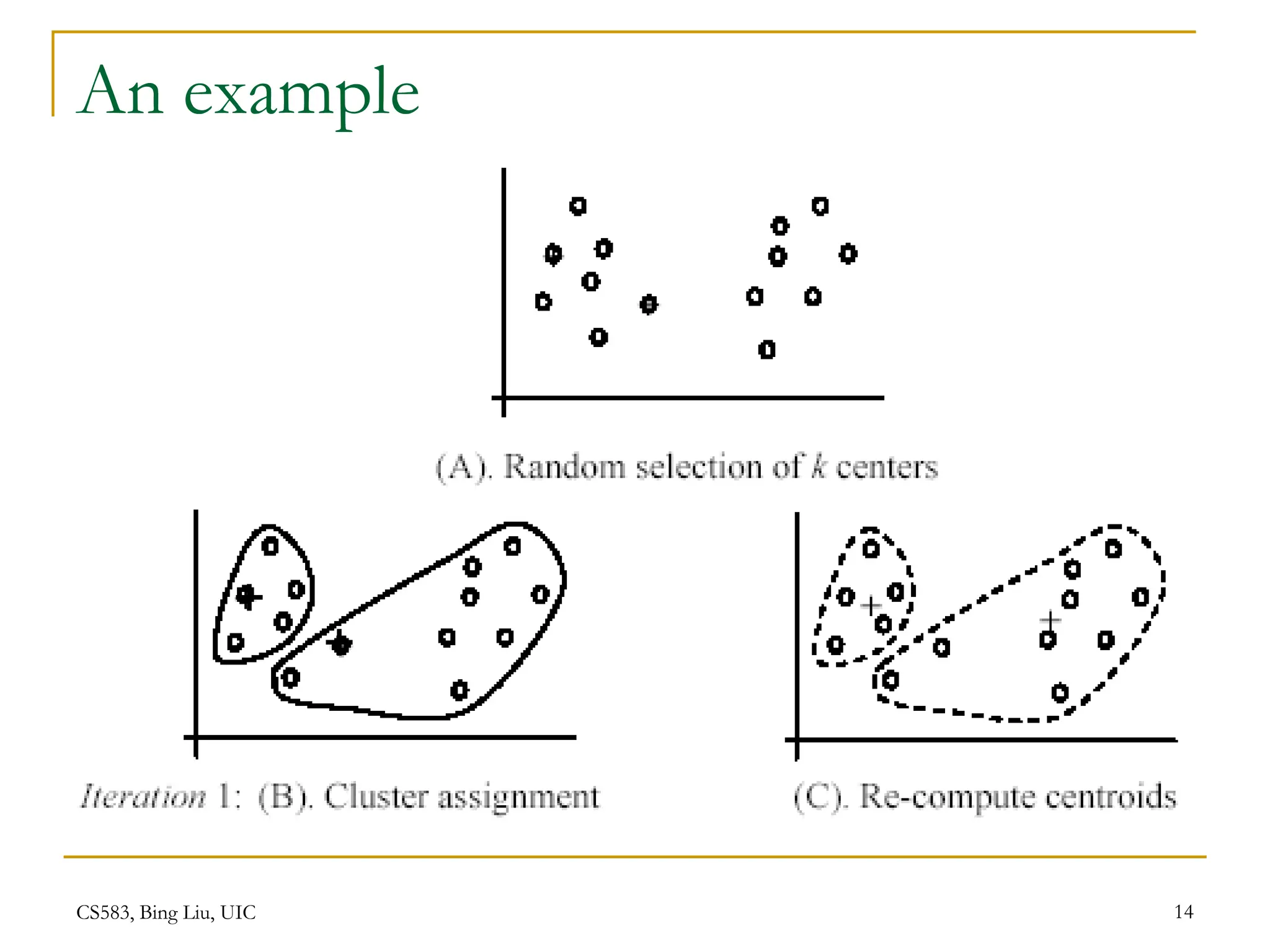
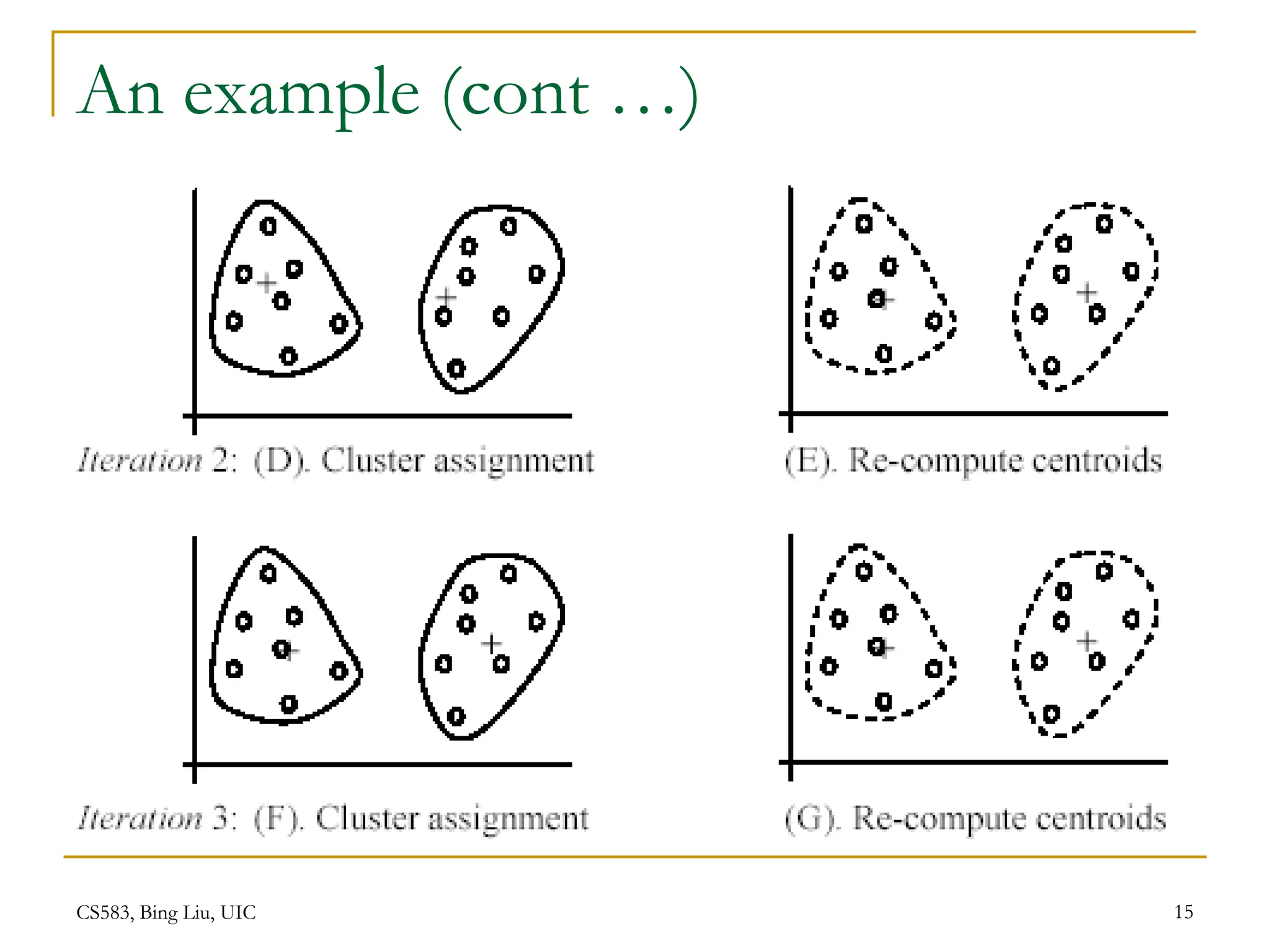
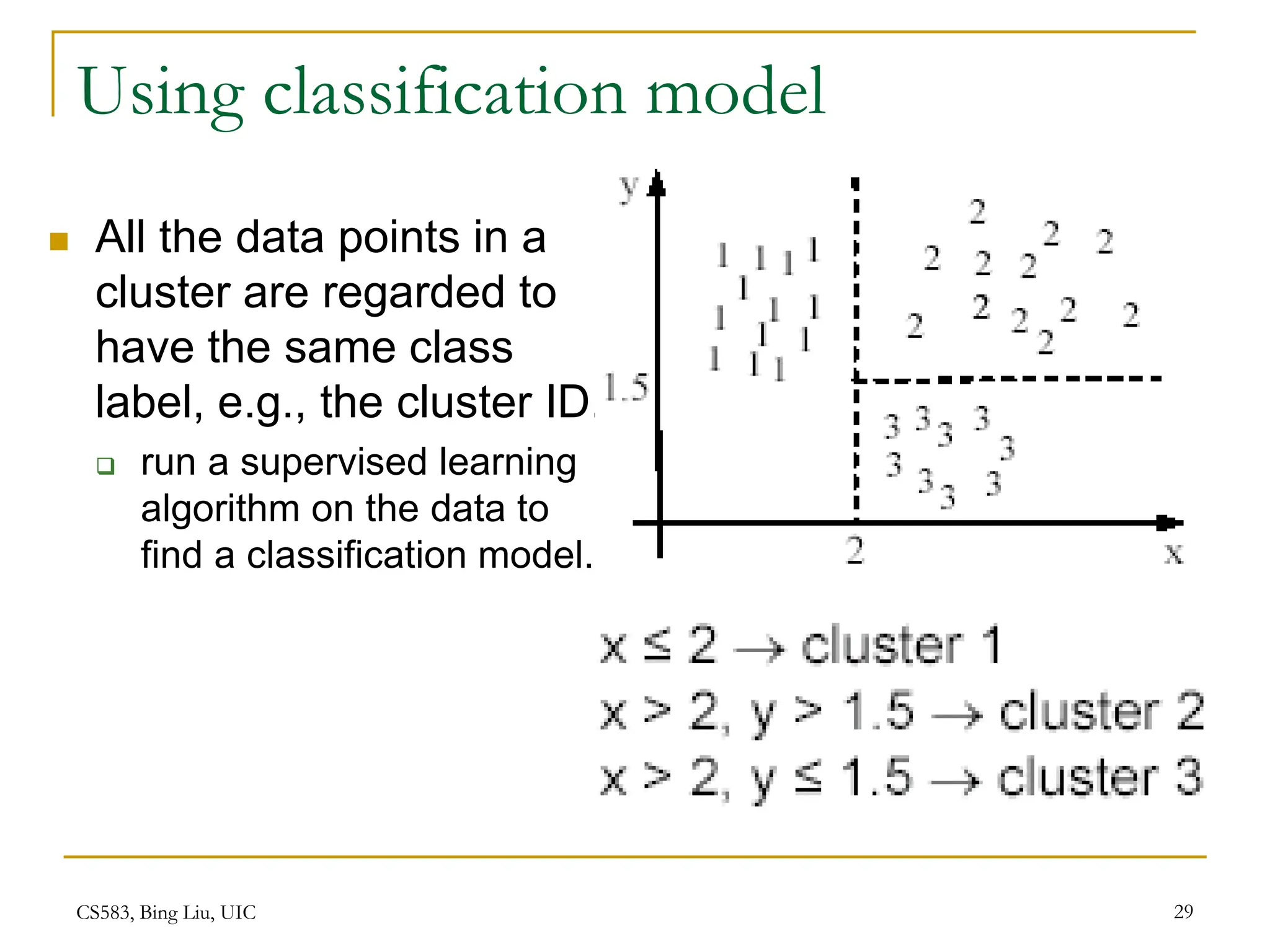
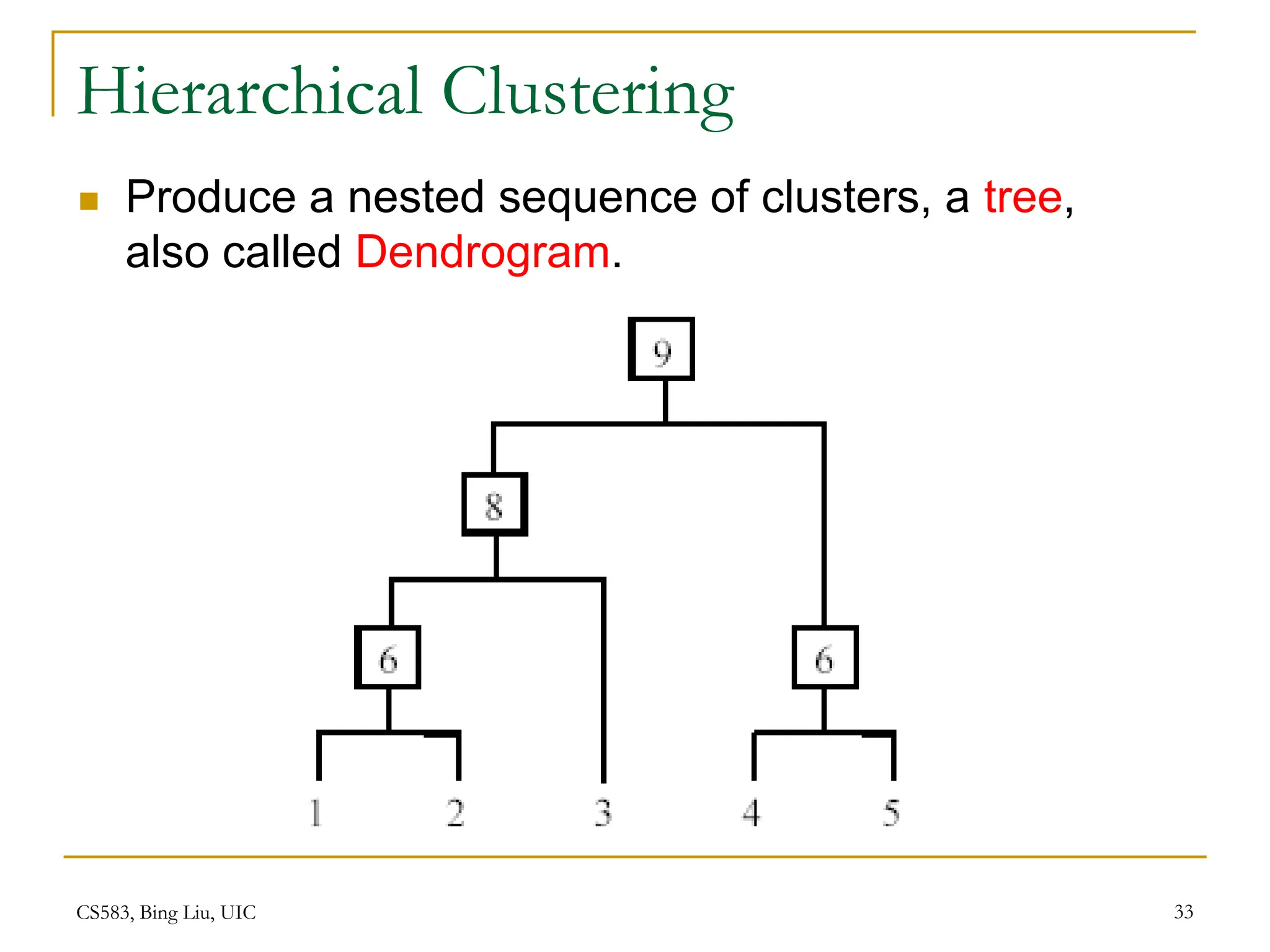
This document provides an overview of unsupervised learning and clustering algorithms. It introduces key concepts in unsupervised learning and how it differs from supervised learning. Clustering is defined as grouping similar data points together into clusters with the goal of maximizing inter-cluster distance and minimizing intra-cluster distance. The k-means algorithm and hierarchical clustering are described as two common clustering techniques. K-means partitions data into k clusters by iteratively assigning points to centroids while hierarchical clustering builds a nested sequence of clusters in a tree structure.

































































































![[ML]-Unsupervised-learning_Unit2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-unsupervised-learningunit2-230916145038-acbd0397-thumbnail.jpg?width=640&height=640&fit=bounds)






![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)



















![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)












