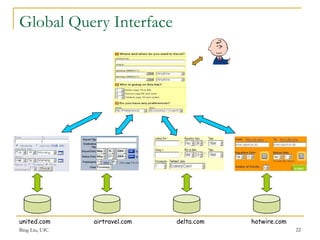
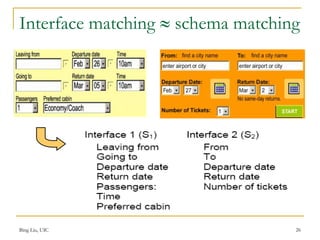
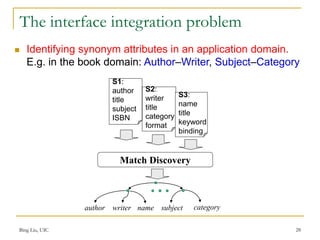
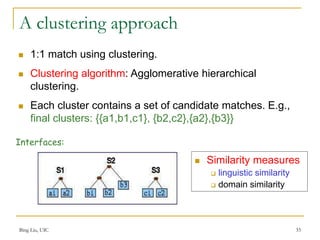
This document discusses techniques for integrating web query interfaces and schemas. It begins with an introduction to information integration and database integration, including schema matching. It then covers pre-processing techniques used for integration like tokenization and stemming. Schema-level matching techniques are discussed like name, description, and constraint-based approaches. Domain and instance-level matching uses value characteristics. Composite domains are handled by detecting delimiters. Similarities from different match indicators can be combined. Web query interface integration is introduced, with the problem being identifying synonym attributes. Schema matching is framed as correlation mining, covering group discovery, match discovery, and matching selection. A clustering approach to 1:1 matching is also presented.
































![[Evaldas Taroza - Master thesis] Schema Matching and Automatic Web Data Extra...](https://cdn.slidesharecdn.com/ss_thumbnails/5c1568bc-753d-44dc-88ac-dcf114742b88-150313043325-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)












































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







