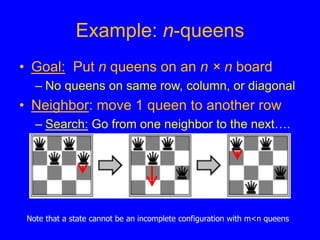
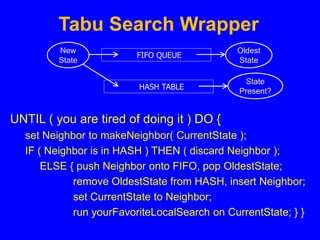
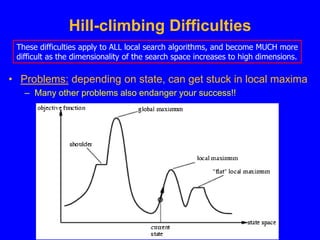
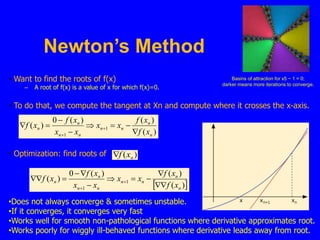
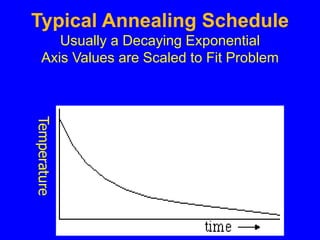
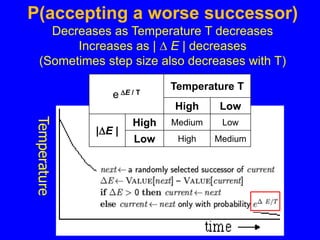
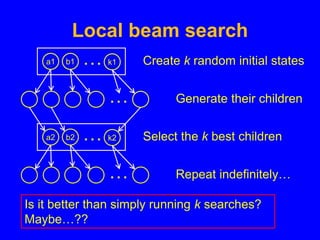
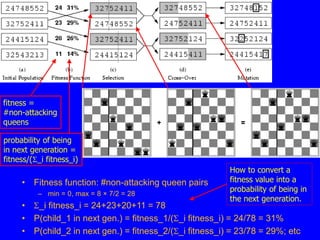
This document discusses local search algorithms. It begins by introducing the topic of local search algorithms and some examples of problems they can be applied to, such as the n-queens problem. It then describes several specific local search algorithms in more detail, including hill-climbing search, gradient descent, simulated annealing search, local beam search, and genetic algorithms. It also discusses techniques like random restart wrappers and tabu search wrappers that can help local search algorithms avoid getting stuck in local optima.