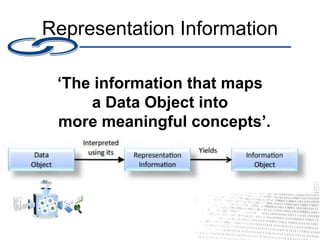
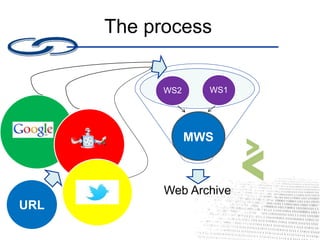
This document discusses the SPRUCE CRISP project, which aims to crowdsource representation information to support digital preservation. It notes issues with the current approach such as duplication of efforts. It then outlines the CRISP objective to gather representation information and describes the process, which involves a web archive master collecting URLs and metadata from various web services. The document encourages involvement by suggesting ways people can contribute, such as providing links to specifications or helping curate/archive the project spreadsheet.