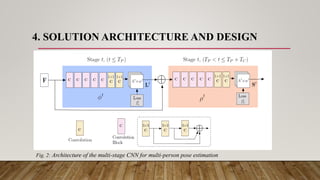
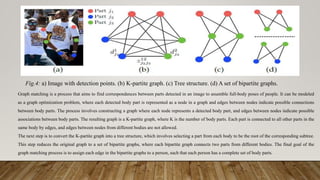
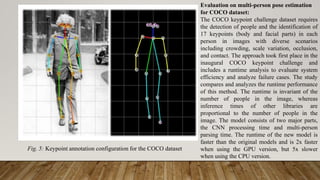
This dissertation report discusses a human pose skeleton-based estimation model designed for real-time multi-person 2D pose detection in images and videos. It presents an innovative approach using part affinity fields (PAFs) to efficiently detect and associate body parts while addressing limitations of traditional methods. Key experiments highlight the model's performance, computational efficiency, and challenges faced in crowded scenes or scenarios involving occlusions.




































![[Mmlab seminar 2016] deep learning for human pose estimation](https://cdn.slidesharecdn.com/ss_thumbnails/mucdgsomrcs8cgkh9gsp-signature-54f17826ed7e29e13653ed835b10fabd79d8e26ac84412798c7e96ef7d109006-poli-160811023645-thumbnail.jpg?width=640&height=640&fit=bounds)






































