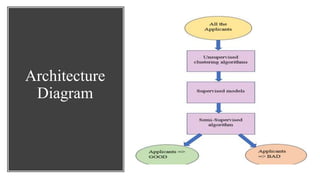
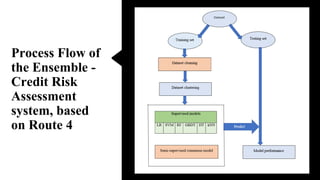
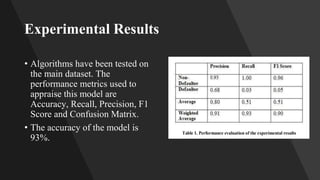
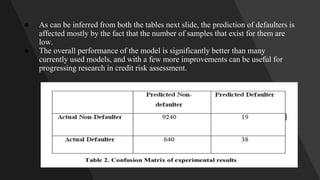
This document describes an ensemble-based credit risk assessment system that uses multiple machine learning models to improve accuracy. It proposes a three-level architecture using unsupervised clustering, supervised classification with algorithms like logistic regression and random forests, and semi-supervised consensus voting. Testing on real data showed 93% accuracy, better predicting defaulters compared to current systems. The system aims to reduce credit risks and losses for financial institutions.

































![CREDIT_RISK_ASSESMENT_SYSTEM_USING_MACHINE_LEARNING[1] [Read-Only].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/creditriskassesmentsystemusingmachinelearning1read-only-240108072618-c66ac2d8-thumbnail.jpg?width=640&height=640&fit=bounds)













![ai it hw mst prac[1] - Read-Offnly.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiithwmstprac1-read-only-250118093323-c97d352c-thumbnail.jpg?width=640&height=640&fit=bounds)























