[논문발표] 20160404 Supporting Serendipitous Social Interaction Using Human Mobility Prediction
1.
Supporting Serendipitous Social
Interaction
UsingHuman Mobility Prediction
Zhiwen Yu, IEEE TRANSACTIONS ON HUMAN-MACHINE SYSTEMS, 2015
윤상훈
Intelligent Database Systems
Laboratory
16.04.04
제목과 동일 1
2.
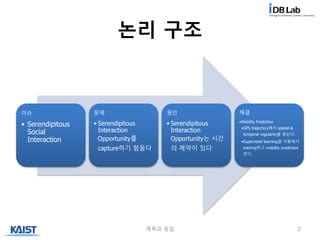
논리 구조
이슈
• Serendipitous
Social
Interaction
문제
•Serendipitous
Interaction
Opportunity를
capture하기 힘들다
원인
• Serendipitous
Interaction
Opportunity는 시간
의 제약이 있다
해결
•Mobility Prediction
•GPS trajectory에서 spatial &
temporal regularity를 찾는다.
•Supervised learning을 이용해서
training하고 mobility prediction
한다.
제목과 동일 2
3.
Serendipitous Social
Interaction
• 의도치않게 우연히 생기는 사회적 interaction
• Mobile peer-to-peer environment에서 두 개의
device가 가까이 있을 때 일어나는 interaction
• Serendipitous social interaction의 특징
– Unplanned
– Not affecting users’ schedules
– Bringing convenience
– Creating positive emotion (happiness)
• Mobile sensor와 Portable device의 인기가
높아지면서 ”serendipitous” social interaction이 뜨고
있다.
제목과 동일 3
4.
Motivation
• 실제 세계에서사람들의 사회적 관계를
향상시키기 위해
• Use-case (application)
– 두 친구가 가끔씩 같은 시간에 도서관을
가는데 서로 그것을 모른다.
– 룸메이트가 마트를 지나갈 때 뭐 좀 사오라고
할 수 있다.
제목과 동일 4
5.
Related Work
• Similarity(interest)-basedfriend
recommendation in social networks
– Learning, date, travel
• Face-to-face human interaction
– Bluetooth를 이용한 주변의 친구 찾기
– 지역 기반 데이팅
– 특별한 배지를 착용한 사람들끼리 교류
– Information sharing & social interaction을 통한
serendipitous interaction opportunity capturing
제목과 동일 5
6.
Problem Definition
• Serendipitoussocial interaction
opportunity의 시간적 제약이 크다
– Device detection을 통한 capturing은 이미
너무 늦어서 opportunity가 실제
interaction으로 이어지기 힘들다.
제목과 동일 6
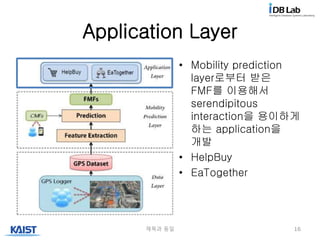
Approach
• Opportunity capturing의시간적 제약을
완화하기 위해 prediction이 필요하다
• Mobility prediction!
– GPS trajectory가 가지고 있는 strong spatial
and temporal regularity를 이용한다
– Supervised learning algorithm으로
regularity를 extract한다.
제목과 동일 8
9.
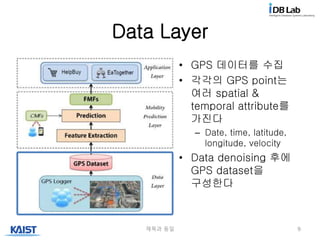
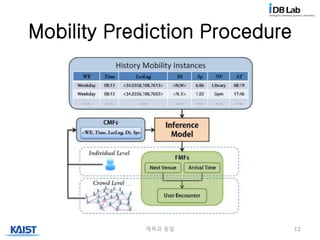
Data Layer
제목과 동일9
• GPS 데이터를 수집
• 각각의 GPS point는
여러 spatial &
temporal attribute를
가진다
– Date, time, latitude,
longitude, velocity
• Data denoising 후에
GPS dataset을
구성한다
10.
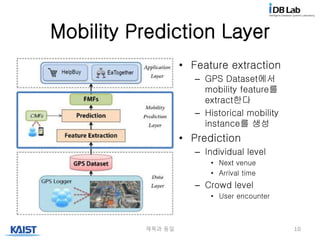
Mobility Prediction Layer
제목과동일 10
• Feature extraction
– GPS Dataset에서
mobility feature를
extract한다
– Historical mobility
instance를 생성
• Prediction
– Individual level
• Next venue
• Arrival time
– Crowd level
• User encounter
11.
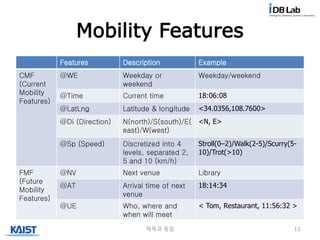
Mobility Features
Features DescriptionExample
CMF
(Current
Mobility
Features)
@WE Weekday or
weekend
Weekday/weekend
@Time Current time 18:06:08
@LatLng Latitude & longitude <34.0356,108.7600>
@Di (Direction) N(north)/S(south)/E(
east)/W(west)
<N, E>
@Sp (Speed) Discretized into 4
levels, separated 2,
5 and 10 (km/h)
Stroll(0–2)/Walk(2-5)/Scurry(5-
10)/Trot(>10)
FMF
(Future
Mobility
Features)
@NV Next venue Library
@AT Arrival time of next
venue
18:14:34
@UE Who, where and
when will meet
< Tom, Restaurant, 11:56:32 >
제목과 동일 11
Predicting Next Venue
•Supervised classification algorithm
– Input: CMF
– Output: next venue
• Candidate inference model
– Decision tree
– Random forest
– kNN
– BayesNet
제목과 동일 13
14.
Predicting Arrival Time
•Supervised classification algorithm
– Input: CMF
– Output: arrival time
• Candidate inference model
– Model tree
– Linear regression
제목과 동일 14
Evaluation
• Data collection
•Next venue prediction
• Arrival time prediction
• User encounter prediction
• User study
제목과 동일 19
20.
Data Collection
• 17개의popular venue를 선정
– 4개의 categories로 분류
• Restaurant
• Dormitory
• Workplace
• Sports
• 156명의 학생들이 GPS logging device를
가지고 다니면서 trajectory를 기록
• 총 1200시간의 trajectory, 280만 개의 GPS
points
• Preprocessing 후에 64,482 mobility
instances
제목과 동일 20
21.
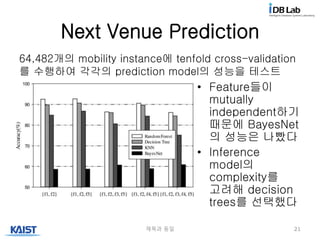
Next Venue Prediction
•Feature들이
mutually
independent하기
때문에 BayesNet
의 성능은 나빴다
• Inference
model의
complexity를
고려해 decision
trees를 선택했다
제목과 동일 21
64,482개의 mobility instance에 tenfold cross-validation
를 수행하여 각각의 prediction model의 성능을 테스트
22.
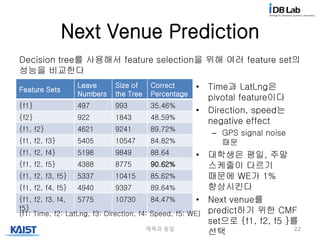
Next Venue Prediction
•Time과 LatLng은
pivotal feature이다
• Direction, speed는
negative effect
– GPS signal noise
때문
• 대학생은 평일, 주말
스케줄이 다르기
때문에 WE가 1%
향상시킨다
• Next venue를
predict하기 위한 CMF
set으로 {f1, f2, f5 }를
선택제목과 동일 22
Feature Sets
Leave
Numbers
Size of
the Tree
Correct
Percentage
{f1} 497 993 35.46%
{f2} 922 1843 48.59%
{f1, f2} 4621 9241 89.72%
{f1, f2, f3} 5405 10547 84.82%
{f1, f2, f4} 5198 9849 88.64
{f1, f2, f5} 4388 8775 90.62%
{f1, f2, f3, f5} 5337 10415 85.62%
{f1, f2, f4, f5} 4940 9397 89.64%
{f1, f2, f3, f4,
f5}
5775 10730 84.47%
Decision tree를 사용해서 feature selection을 위해 여러 feature set의
성능을 비교한다
(f1: Time, f2: LatLng, f3: Direction, f4: Speed, f5: WE)
23.
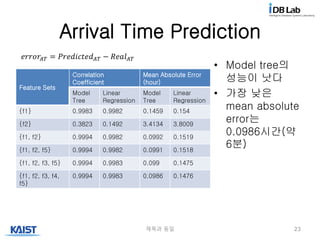
Arrival Time Prediction
•Model tree의
성능이 낫다
• 가장 낮은
mean absolute
error는
0.0986시간(약
6분)
제목과 동일 23
Feature Sets
Correlation
Coefficient
Mean Absolute Error
(hour)
Model
Tree
Linear
Regression
Model
Tree
Linear
Regression
{f1} 0.9983 0.9982 0.1459 0.154
{f2} 0.3823 0.1492 3.4134 3.8009
{f1, f2} 0.9994 0.9982 0.0992 0.1519
{f1, f2, f5} 0.9994 0.9982 0.0991 0.1518
{f1, f2, f3, f5} 0.9994 0.9983 0.099 0.1475
{f1, f2, f3, f4,
f5}
0.9994 0.9983 0.0986 0.1476
𝑒𝑟𝑟𝑜𝑟𝐴𝑇 = 𝑃𝑟𝑒𝑑𝑖𝑐𝑡𝑒𝑑 𝐴𝑇 − 𝑅𝑒𝑎𝑙 𝐴𝑇
24.
User Encounter Prediction
•544개의 encounter instance를 선택
• 두 사용자는 약 2분 정도를 기다리고서
만났다 (𝑇𝑜 = 2𝑚𝑖𝑛)
• 92.3%(502 / 544)의 정확도를 보였다
제목과 동일 24
25.
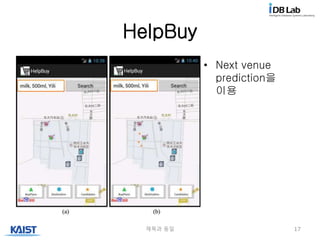
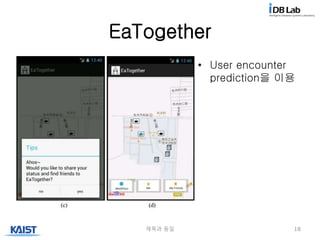
User Study
• Q1:사람들이 Henry와 같은 상황에 놓인다면 HelpBuy는 유용한가
• Q2: 만약 가끔씩 학생 식당에서 친구와 마주친다면 같이 밥을 먹을
것이다
• Q3: HelpBuy에서 다른 사람 대신 물건을 사는 일을 할 것이다.
• Q4: EaTogether는 생각지 못하게 친구를 만나게 하는 것을
도와준다. 그리고 나는 다시 이용할 것이다
• Q5: 앱은 잘 작동했고 성능(prediction accuracy) 및 operating
experience에 만족한다.
• Q6: 앱은 친구들, 심지어 모르는 사람과의 관계를 돈독하게 한다
제목과 동일 25
26.
Discussion
• Offline socialinteraction
– Friend recommendation을 접목할 수 있지
않을까
• System portability
– In our experiments, the strong spatiotemporal
regularity in students’ life trajectories may lead
to acceptable prediction performance.
– Localization tech
• Privacy
제목과 동일 26
#28 This is the end of my presentation.
Do you have any questions or comments?
Thank you for your concentration.
=======================================
우리가 uOR 저자한테 evaluation결과와 함께 물어봤는데, 그 결과에 대해 인정하였으며, 왜 그런지는 설명을 듣지 못하였다.
우리의 memory 사용전략
- Fact 저장시에 hashed value로 Fact manager에 저장?
- Fact Duplication 제거
- Minimize memory cost for enhancing performance


















![[세미나] 20160520 Gradle](https://cdn.slidesharecdn.com/ss_thumbnails/20160520gradle-160523005620-thumbnail.jpg?width=640&height=640&fit=bounds)
![[논문발표] 20160725 A Random Walk Around the City: New Venue Recommendation in Lo...](https://cdn.slidesharecdn.com/ss_thumbnails/20160725arandomwalkaroundthecity-160726112403-thumbnail.jpg?width=640&height=640&fit=bounds)



![[논문발표] 20160801 A Sentiment-Enhanced Personalized Location Recommendation System](https://cdn.slidesharecdn.com/ss_thumbnails/20160801asentiment-enhancedpersonalizedlocationrecommendationsystem-160819055329-thumbnail.jpg?width=640&height=640&fit=bounds)

![[패스트캠퍼스] 네이버뉴스_및_다음_뉴스_분류_예측](https://cdn.slidesharecdn.com/ss_thumbnails/random-161219110653-thumbnail.jpg?width=640&height=640&fit=bounds)












![제 19회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [REC] : 캠핏 데이터를 활용한 캠핑장 추천 시스템 구현](https://cdn.slidesharecdn.com/ss_thumbnails/rec-240209025555-294ceb64-thumbnail.jpg?width=640&height=640&fit=bounds)




![[패스트캠퍼스]개인맞춤 패션 쇼핑몰 상품 추천 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/random-161213125036-thumbnail.jpg?width=640&height=640&fit=bounds)

