Download to read offline




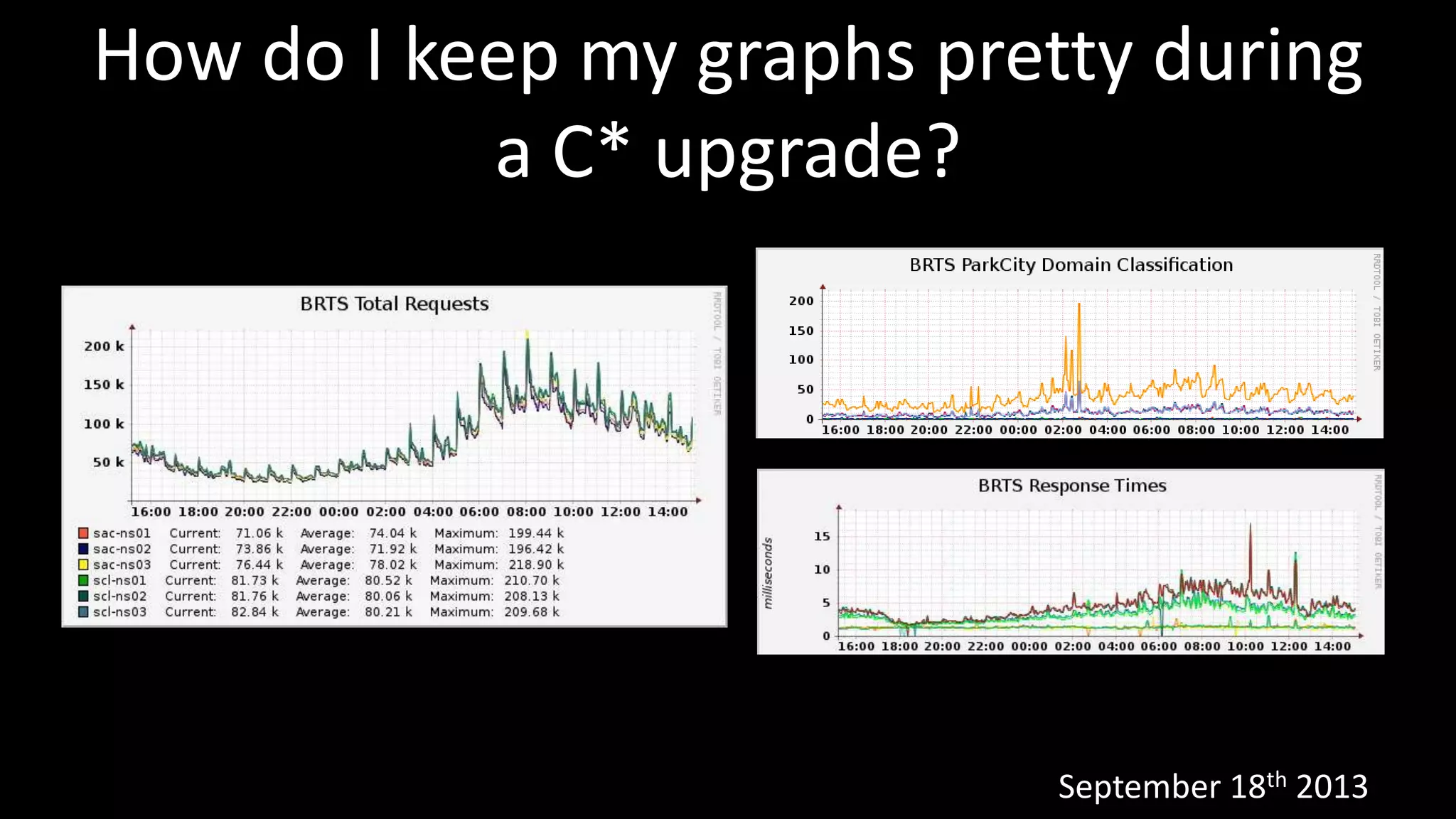









The document discusses continuous deployment with Cassandra (C*), highlighting its role at Barracuda Networks where it handles substantial data requests with low latency across a 48-node cluster. It emphasizes the importance of treating C* builds like code releases to maintain visibility, control over upgrades, and stability during deployments. The author advises on dealing with potential bugs and failures during upgrades by writing robust code that gracefully handles node failures and latency issues.


























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















