This document discusses compilers, libraries, and optimization. It notes that compilers must handle complex processor behaviors and target systems different than build systems. Libraries have contradictory requirements like unknown usage but high performance. Examples show how a simple loop can be optimized from linear 1979 code to parallelized 2014 code using SIMD instructions. It also discusses concepts like store forwarding and how libraries must consider multiplatform differences. The document ends by noting the company is hiring.





![The classic example
Thread 1
while( running )
{
int item_count(0);
for( auto i : *p_map )
{
item_count++;
}
p_map->erase( item_count - 1 );
}
Occasional SegVio!
Thread 2
for( int i = 0; i < 1024 * 1024 ; i++ )
{
my_map[ i ] = i * 16;
}
running = false;](https://image.slidesharecdn.com/eafd7aa3-07fa-420e-9711-9857ac09fcd9-150209174744-conversion-gate02/85/CompilersAndLibraries-5-320.jpg)

![Example Code
#include <stdio.h>
int main( )
{
char const text[] = “Hello Universe”;
FILE *fp = fopen(“invalid/path/to/file”, “w+”);
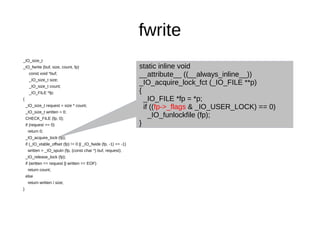
fwrite( text, sizeof( char ), sizeof( text ), fp );
fclose( fp );
}
Segmentation Fault!](https://image.slidesharecdn.com/eafd7aa3-07fa-420e-9711-9857ac09fcd9-150209174744-conversion-gate02/85/CompilersAndLibraries-7-320.jpg)




![Loopy code
extern int elem[64];
int i, sum;
for( i = 63; i; i-- )
{
sum = sum + elem[ i ];
}](https://image.slidesharecdn.com/eafd7aa3-07fa-420e-9711-9857ac09fcd9-150209174744-conversion-gate02/85/CompilersAndLibraries-13-320.jpg)










![Store Forward example
mov [EBP],'helloworld'
mov AL, [EBP] ;not blocked
mov BL, [EBP+1] ;blocked
mov CL, [EBP+2] ;blocked
mov DL, [EBP+3] ;blocked
mov AL, [EBP] ;not blocked, issued
before blocked loads](https://image.slidesharecdn.com/eafd7aa3-07fa-420e-9711-9857ac09fcd9-150209174744-conversion-gate02/85/CompilersAndLibraries-25-320.jpg)




























































