Downloaded 27 times






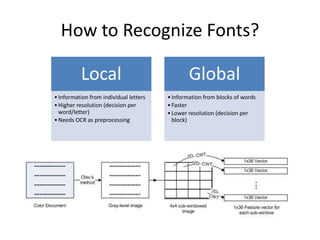






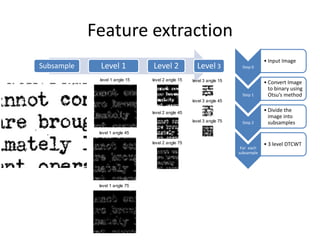
![Feature Extraction
• Input Image
Level Step 0
1 μ1 : 0,082091 0,084891 0,060045 0,080689 0,085836 0,060873
• Convert Image
to binary using
σ1 : 0,14791 0,15201 0,11201 0,14617 0,15402 0,11424 Step 1 Otsu’s method
• Divide the
Level Step 2
image into
subsamples
μ2: 0,22597 0,24064 0,11976 0,23731 0,24072 0,12753
2 σ2: 0,36203 0,35692 0,17401 0,37765 0,34842 0,19024
• 3 level DTCWT
For each
subsample
Level
μ3: 0,49943 0,54883 0,35954 0,55623 0,56736 0,30949 • Mean and std
3 σ3: 0,6949 0,65361 0,46078 0,72141 0,68851 0,39779
Step 4
• Concatenate
Step 5
Φ = [μ1, μ2, μ3, σ1, σ2, σ3] (1x36 feature vector)](https://image.slidesharecdn.com/alicanbgrc-130315095919-phpapp01/85/Classification-of-Fonts-and-Calligraphy-Styles-based-on-Complex-Wavelet-Transform-17-320.jpg)


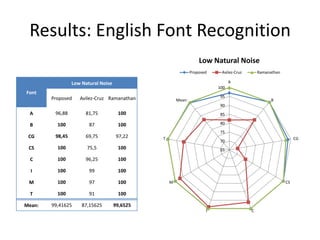

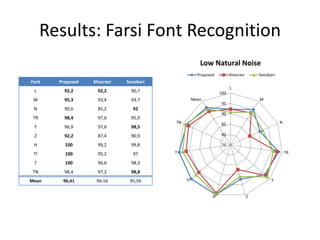
![Results: Farsi Font Recognition
• Dataset
– Small natural noise
– 1 paragraph per font/emphasis pair
– 8 fonts:
• Homa, Lotus, Mitra, Nazanin, Tahoma,
Times New
Roman, Titr, Traffic, Yaghut, and Zar
a: Lotus italic
b:Homa bold italic
[a] c:Times New
[b][c] Roman bold](https://image.slidesharecdn.com/alicanbgrc-130315095919-phpapp01/85/Classification-of-Fonts-and-Calligraphy-Styles-based-on-Complex-Wavelet-Transform-24-320.jpg)

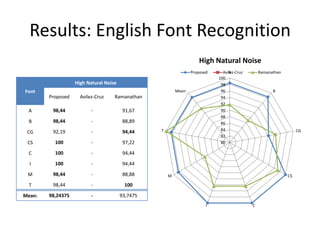
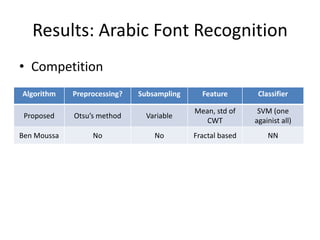
![Results: Arabic Font Recognition
• Dataset
– ALPH-REGIM database
– 749 different sized/long
samples
– 10 fonts:
• Ahsa, Andalus, Arabic_
transparant, Badr, Bury
idah, Dammam, Hada,
Kharj, Koufi, Naskh
[a] a: Ahsa
[b] b: Badr
[c] c: Naskh
[d] d: Dammam](https://image.slidesharecdn.com/alicanbgrc-130315095919-phpapp01/85/Classification-of-Fonts-and-Calligraphy-Styles-based-on-Complex-Wavelet-Transform-27-320.jpg)

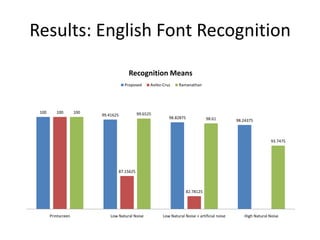
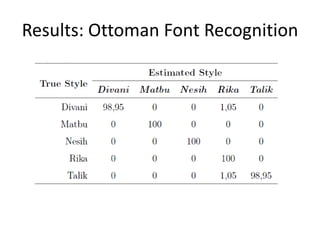
![Results: Ottoman Style Recognition
• Dataset
– Ottoman Archives
– 6 pages per style
– Different
backgrounds
– 5 styles:
• Divani, Nesih, Matb
u, Talik, Rika
a: Divani
b: Matbu
c: Nesih
d: Rika [a][b][c]
e: Talik [d][e]](https://image.slidesharecdn.com/alicanbgrc-130315095919-phpapp01/85/Classification-of-Fonts-and-Calligraphy-Styles-based-on-Complex-Wavelet-Transform-31-320.jpg)

![References
[1] Abuhaiba, I., 2004. Arabic font recognition using decision trees built [14] Khosravi, H., Kabir, E., 2010. Farsi font recognition based on sobelroberts
from common words. Journal of Computing and Information Technology features. Pattern Recognition Letters 31 (1), 75 – 82.
13 (3), 211–224. [15] Kingsbury, N., 1997. Image processing with complex wavelets. Phil.
[2] Amin, A., 1998. Off-line arabic character recognition: the state of the Trans. Royal Society London A 357, 2543–2560.
art. Pattern recognition 31 (5), 517–530. [16] Kingsbury, N., 1998. The dual-tree complex wavelet transform: a new ef-
[3] Aviles-Cruz, C., Rangel-Kuoppa, R., Reyes-Ayala, M., Andrade- 29
Gonzalez, A., Escarela-Perez, R., 2005. High-order statistical texture ficient tool for image restoration and enhancement. In: Proc. EUSIPCO.
analysis-font recognition applied. Pattern Recognition Letters 26 (2), Vol. 98. pp. 319–322.
135 – 145. [17] Kingsbury, N., 2000. A dual-tree complex wavelet transform with improved
[4] Ben Moussa, S., Zahour, A., Benabdelhafid, A., Alimi, A., 2008. Fractalbased orthogonality and symmetry properties. In: Image Processing,
system for arabic/latin, printed/handwritten script identification. 2000. Proceedings. 2000 International Conference on. Vol. 2. IEEE, pp.
In: Pattern Recognition, 2008. ICPR 2008. 19th International Conference 375–378.
on. IEEE, pp. 1–4. [18] Ma, H., Doermann, D., 2003/// 2003. Gabor filter based multi-class
[5] Borji, A., Hamidi, M., 2007. Support vector machine for persian font classifier for scanned document images. In: 7th International Conference
recognition. International Journal of Intelligent Systems and Technologies, on Document Analysis and Recognition (ICDAR). pp. 968 – 972.
184–187. [19] Otsu, N., 1979. A threshold selection method from gray-level histograms.
[6] Boser, B., Guyon, I., Vapnik, V., 1992. A training algorithm for optimal IEEE Transactions on Systems, Man and Cybernetics 9 (1), 62–66.
margin classifiers. In: Proceedings of the fifth annual workshop on [20] Petkov, N., Wieling, M., 2008. Gabor filter for image processing and
Computational learning theory. ACM, pp. 144–152. computer vision. Tech. rep., University of Groningen.
[7] Cai, S., Li, K., Selesnick, I., ???? Matlab implementation of wavelet [21] Ramanathan, R., Soman, K., Thaneshwaran, L., Viknesh, V., Arunkumar,
transforms. Tech. rep., Polytechnic University. T., Yuvaraj, P., oct. 2009. A novel technique for english font
[8] Chang, C., Lin, C., 2011. Libsvm: a library for support vector machines. recognition using support vector machines. In: Advances in Recent
28 Technologies in Communication and Computing, 2009. ARTCom ’09.
ACM Transactions on Intelligent Systems and Technology (TIST) 2 (3), International Conference on. pp. 766 –769.
27. [22] Rashedi, E., Nezamabadi-pour, H., Saryzadi, S., 2007. Farsi font recognition
[9] Chaudhuri, B., Garain, U., 1998. Automatic detection of italic, bold and using correlation coefficients (in farsi). In: 4th Conf. on Machine
all-capital words in document images. In: Pattern Recognition, 1998. Vision and Image Processing, Ferdosi Mashhad.
Proceedings. Fourteenth International Conference on. Vol. 1. IEEE, pp. [23] Selesnick, I., Baraniuk, R., Kingsbury, N., 2005. The dual-tree complex
610–612. wavelet transform. Signal Processing Magazine, IEEE 22 (6), 123–151.
[10] Cortes, C., Vapnik, V., Sep. 1995. Support-vector networks. Mach. 30
Learn. 20 (3), 273–297. [24] Villegas-Cortez, J., Aviles-Cruz, C., 2005. Font recognition by invariant
[11] Duan, K., Keerthi, S., 2005. Which is the best multiclass svm method? moments of global textures. In: Proceedings of international workshop
an empirical study. Multiple Classifier Systems, 732–760. VLBV05 (very low bit-rate video-coding 2005). pp. 15–16.
[12] Hsu, C., Chang, C., Lin, C., et al., 2003. A practical guide to support [25] Zhu, Y., Tan, T., Wang, Y., Oct. 2001. Font recognition based on global
vector classification. texture analysis. IEEE Trans. Pattern Anal. Mach. Intell. 23 (10), 1192–
[13] Jung, M., Shin, Y., Srihari, S., 1999. Multifont classification using typographical 1200.
attributes. In: Document Analysis and Recognition, 1999. [26] Zramdini, A., Ingold, R., 1998. Optical font recognition using typographical
ICDAR’99. Proceedings of the Fifth International Conference on. IEEE, features. IEEE Transactions on Pattern Analysis and Machine
pp. 353–356. Intelligence 20, 877–882.](https://image.slidesharecdn.com/alicanbgrc-130315095919-phpapp01/85/Classification-of-Fonts-and-Calligraphy-Styles-based-on-Complex-Wavelet-Transform-34-320.jpg)


This document discusses optical character recognition (OCR) and font recognition techniques. It presents the results of several experiments comparing different OCR and font recognition algorithms on various datasets containing English, Farsi, Arabic, and Ottoman fonts and styles. The proposed dual tree complex wavelet transform (DT-CWT) approach achieved higher accuracy than state-of-the-art methods on most datasets, was faster, and was more robust to noise. Mean and standard deviation of wavelet coefficients were used as features with an SVM classifier.













![Gerenciamento de projetos [modo de compatibilidade]](https://cdn.slidesharecdn.com/ss_thumbnails/gerenciamentodeprojetosmododecompatibilidade-160908102500-thumbnail.jpg?width=640&height=640&fit=bounds)




















































