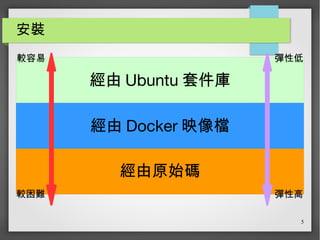
本文件介紹了 CKAN 技術的基礎,涵蓋其技術架構、安裝方法和管理維護建議。主要安裝方式包括透過 Ubuntu 套件、Docker 映像檔和原始碼安裝,其中原始碼安裝為推薦方法。還對擴充套件及升級過程提供了詳細信息以及日常備份的注意事項。









































































![[2]futurewad樹莓派研習會 141127](https://cdn.slidesharecdn.com/ss_thumbnails/2futurewad141127-141219161835-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)











