Download as PDF, PPTX




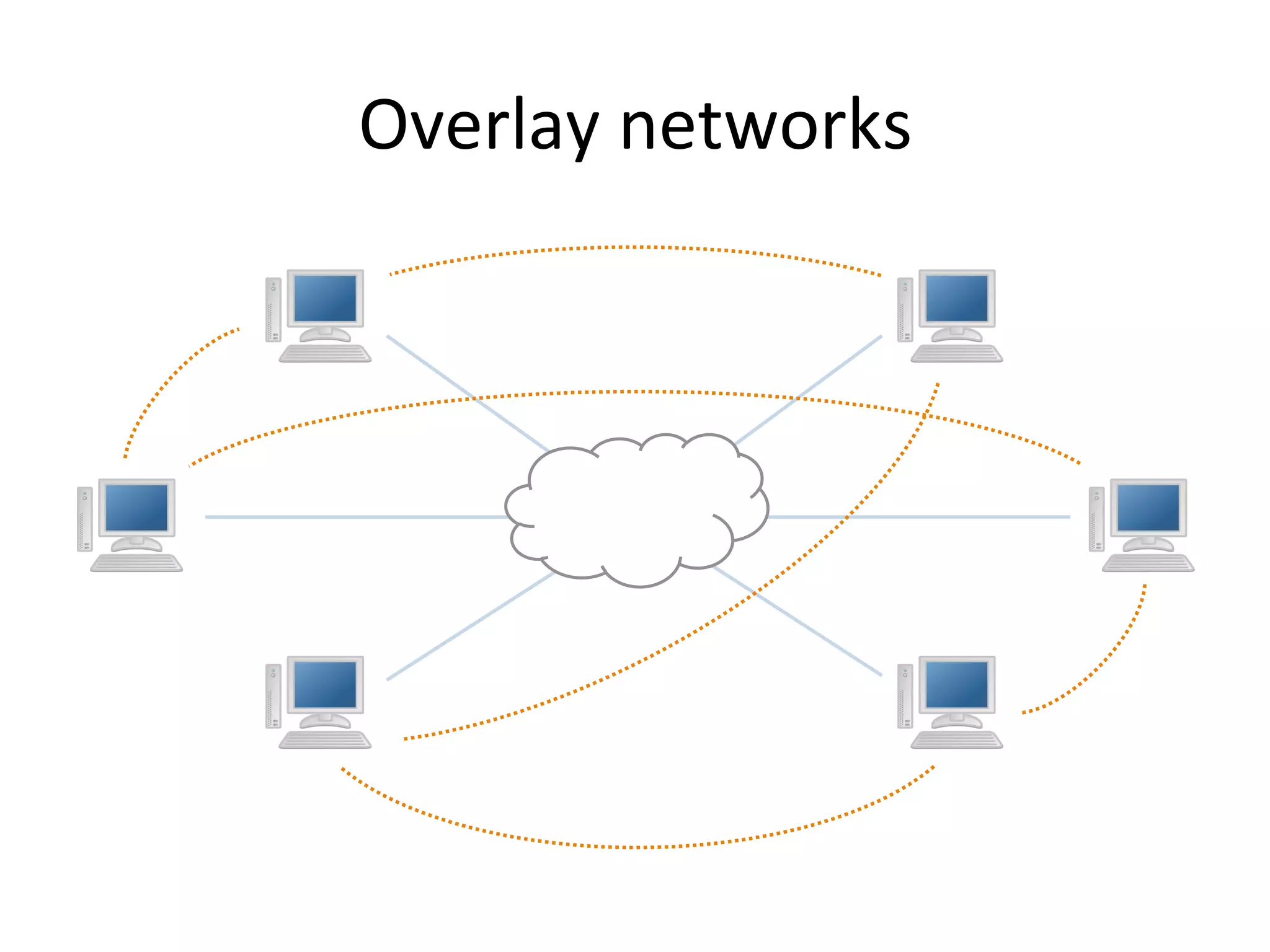
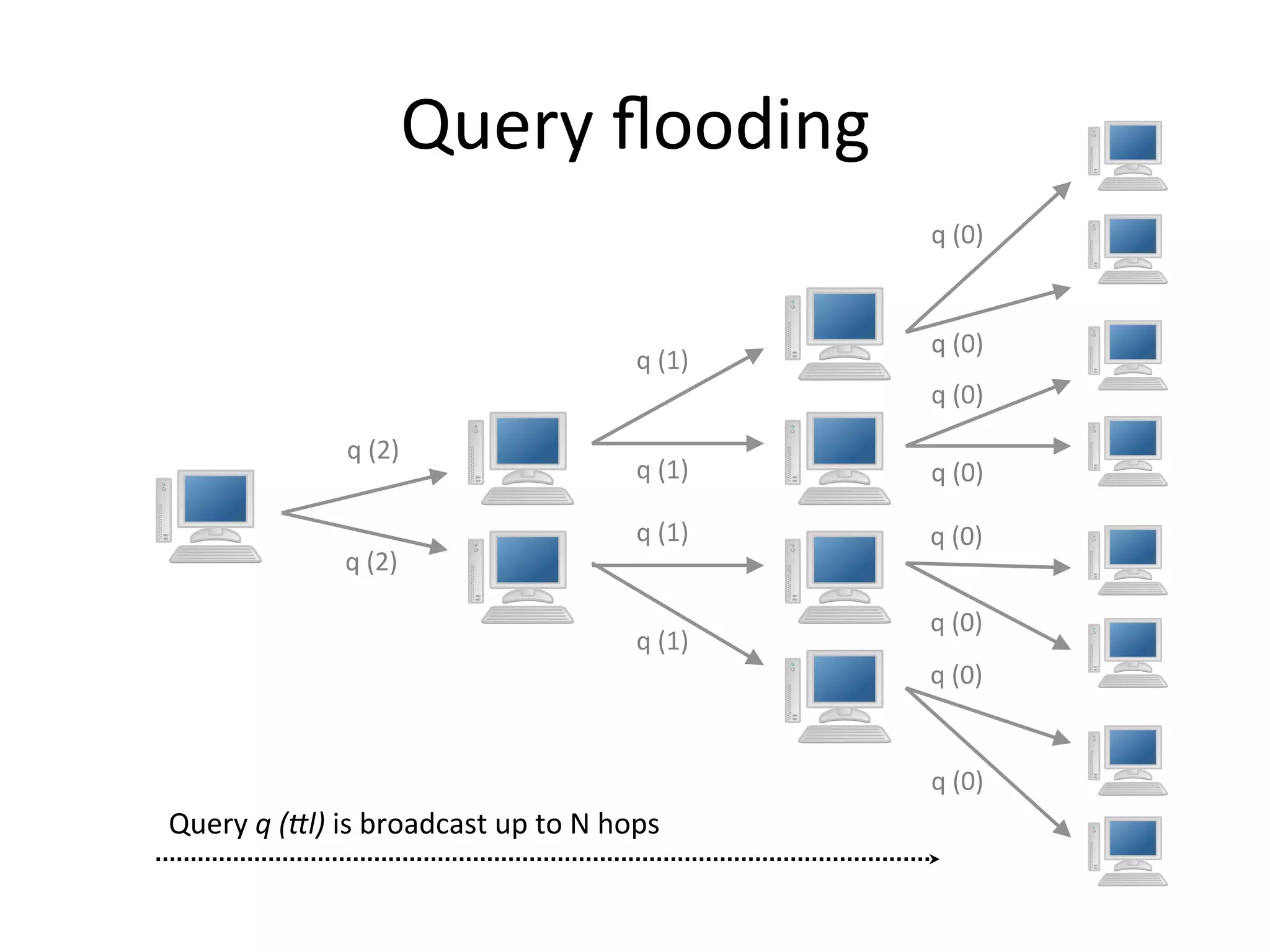
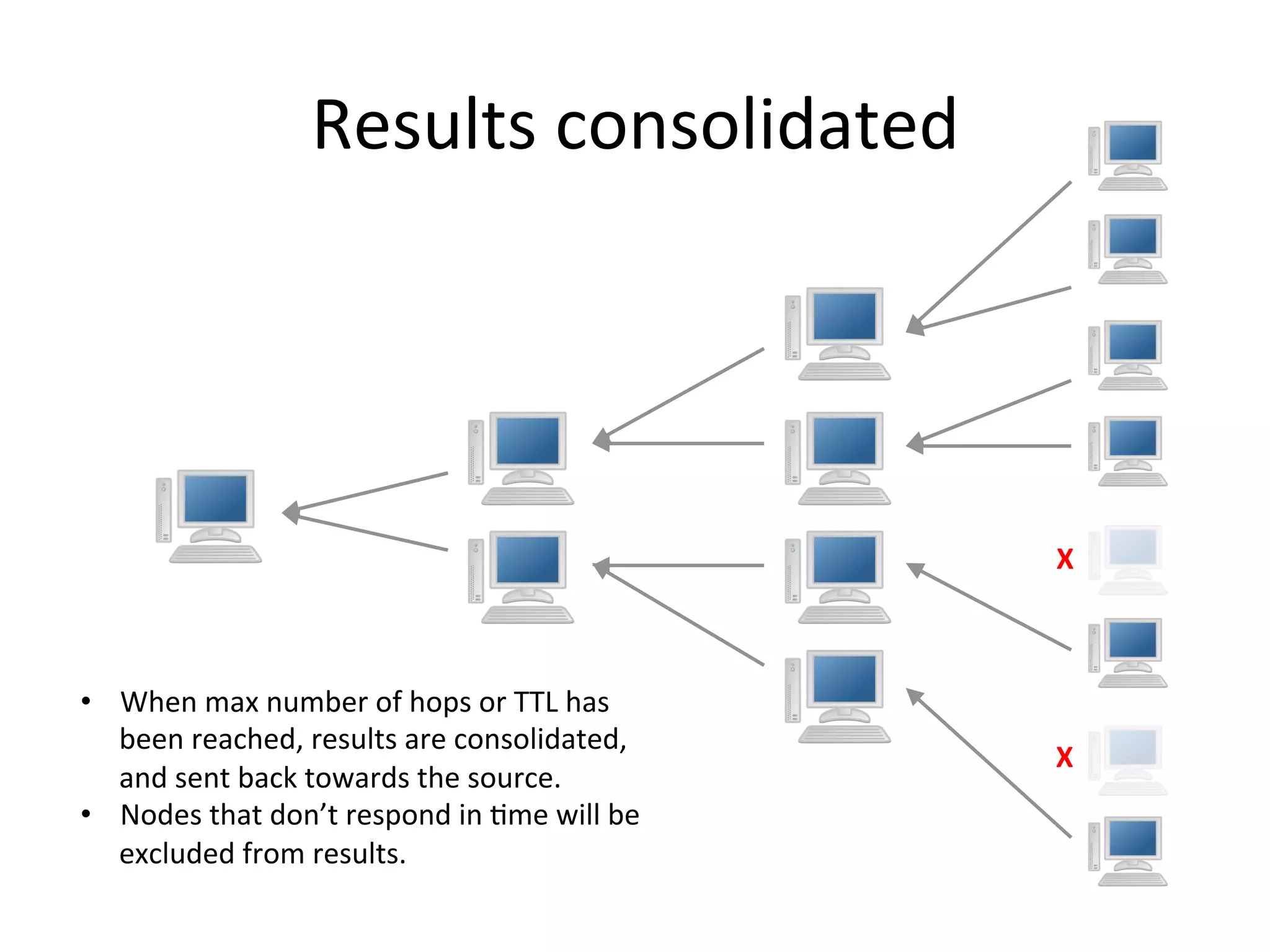


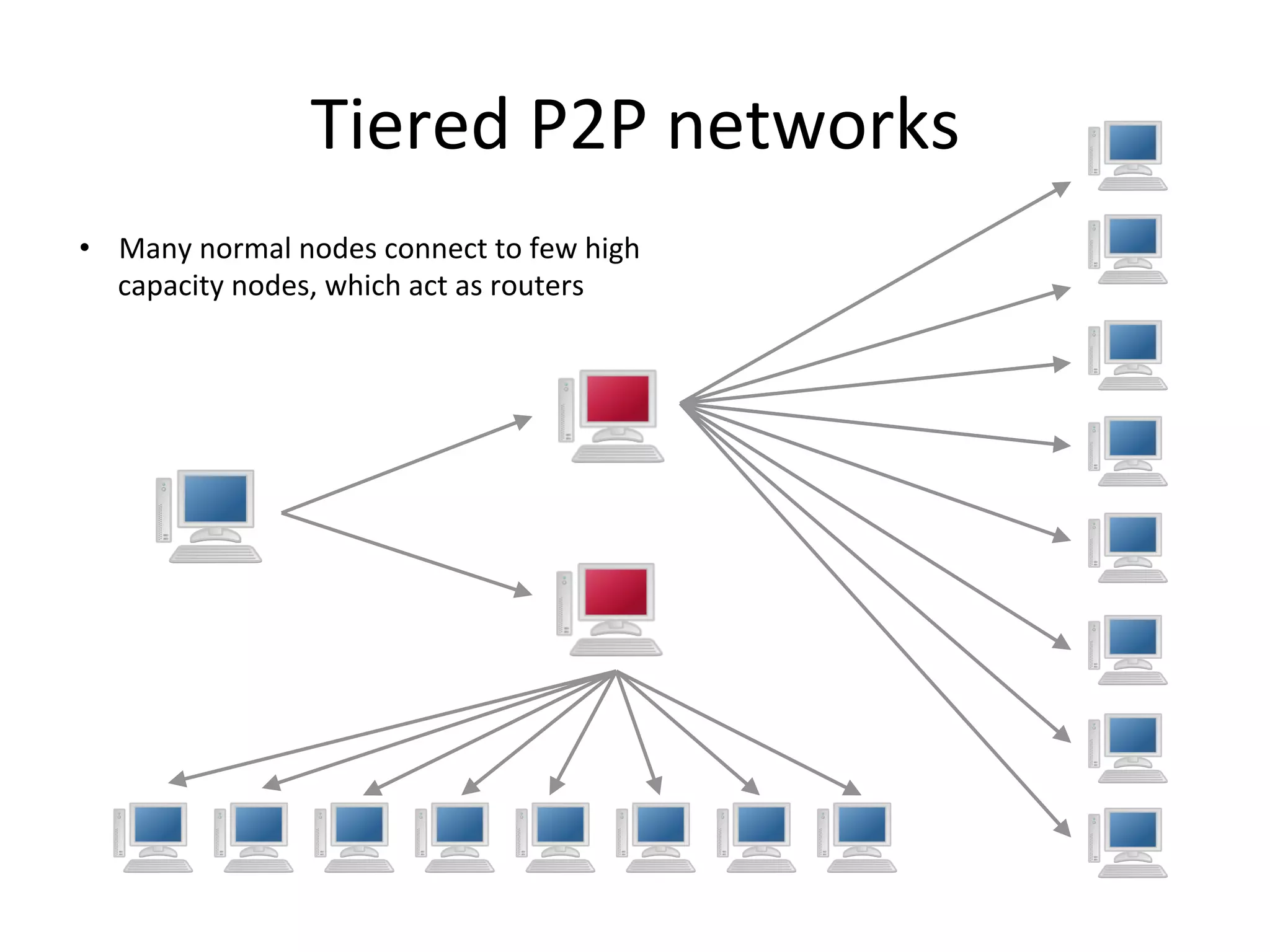

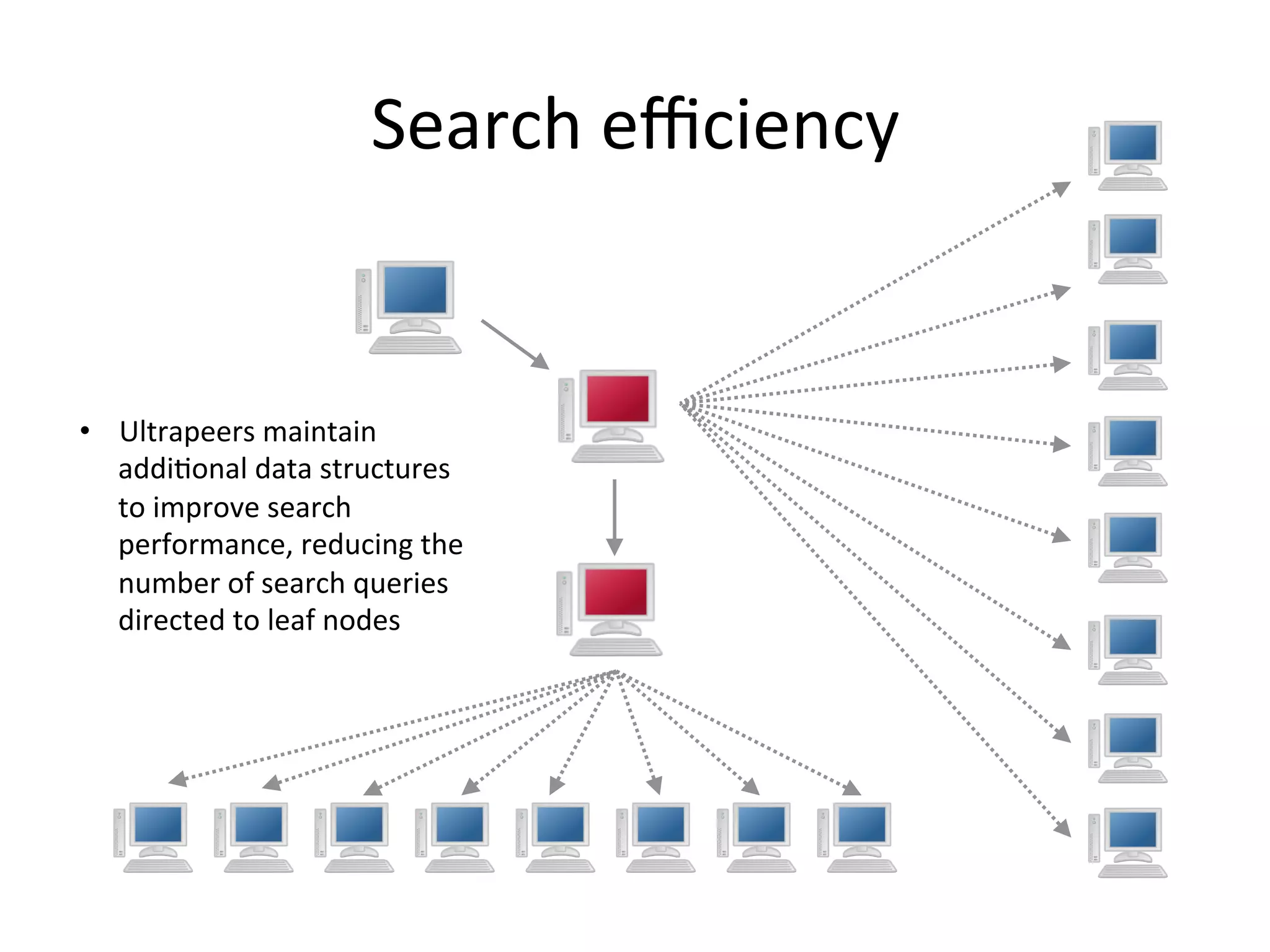


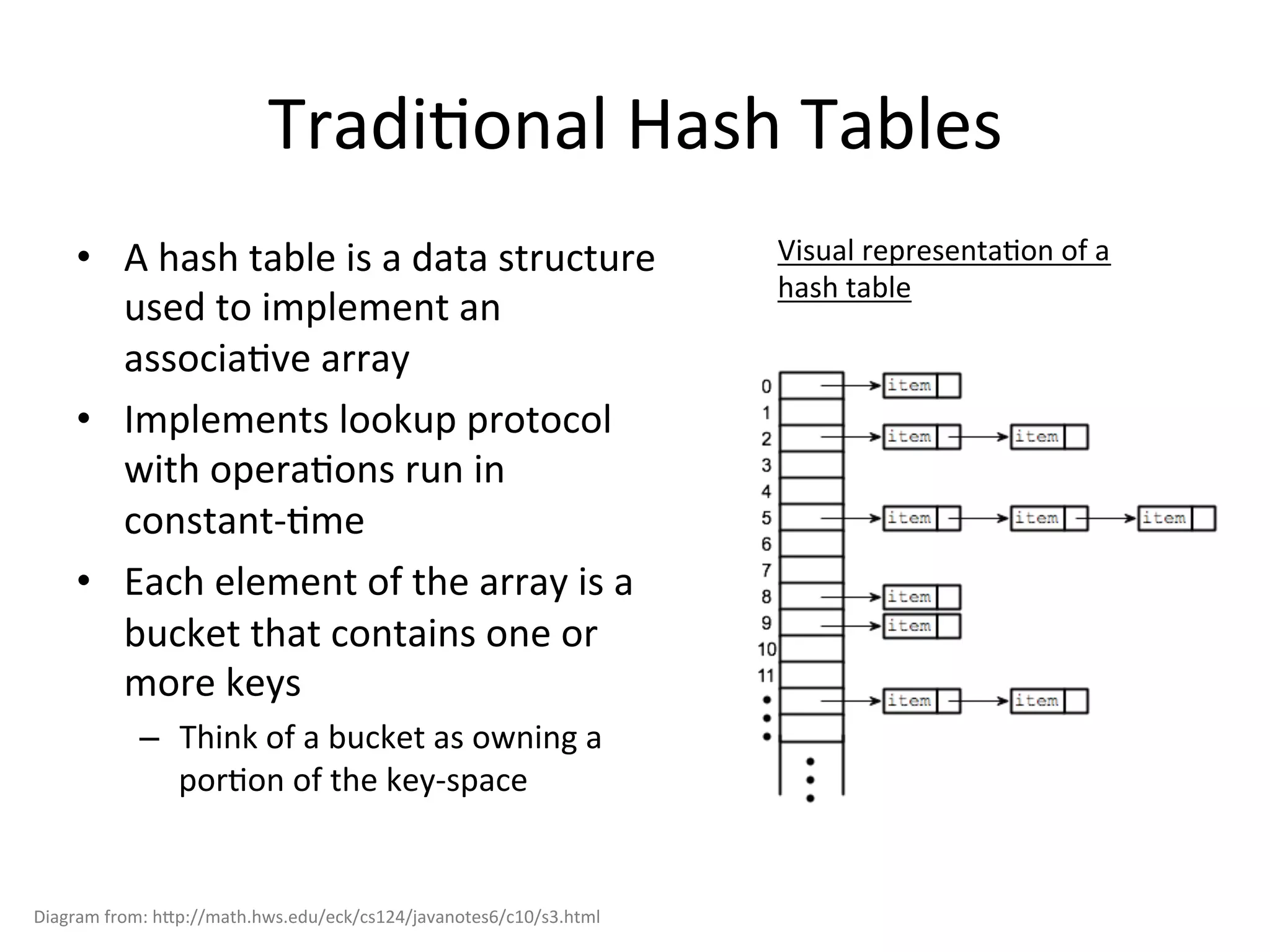



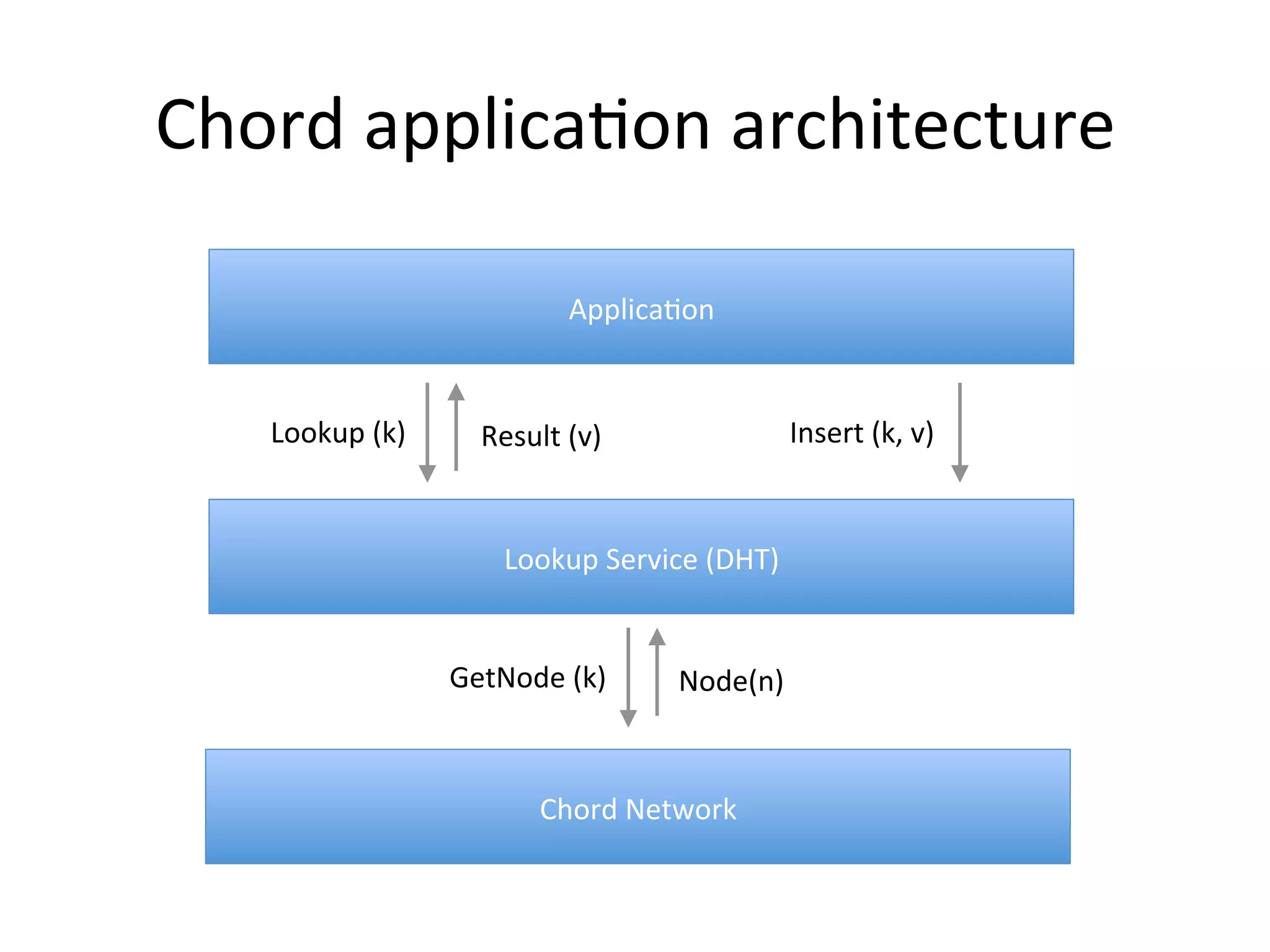

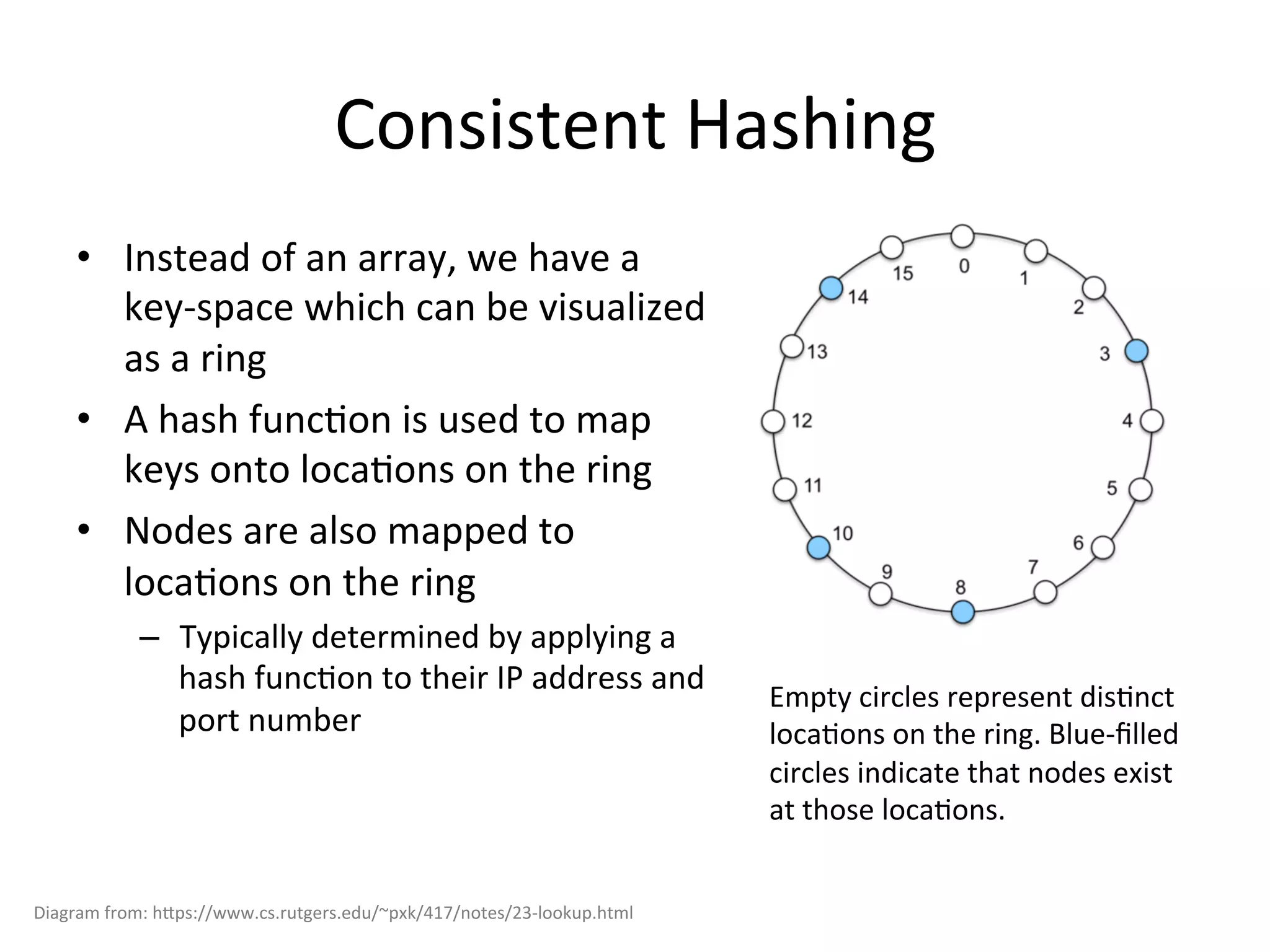

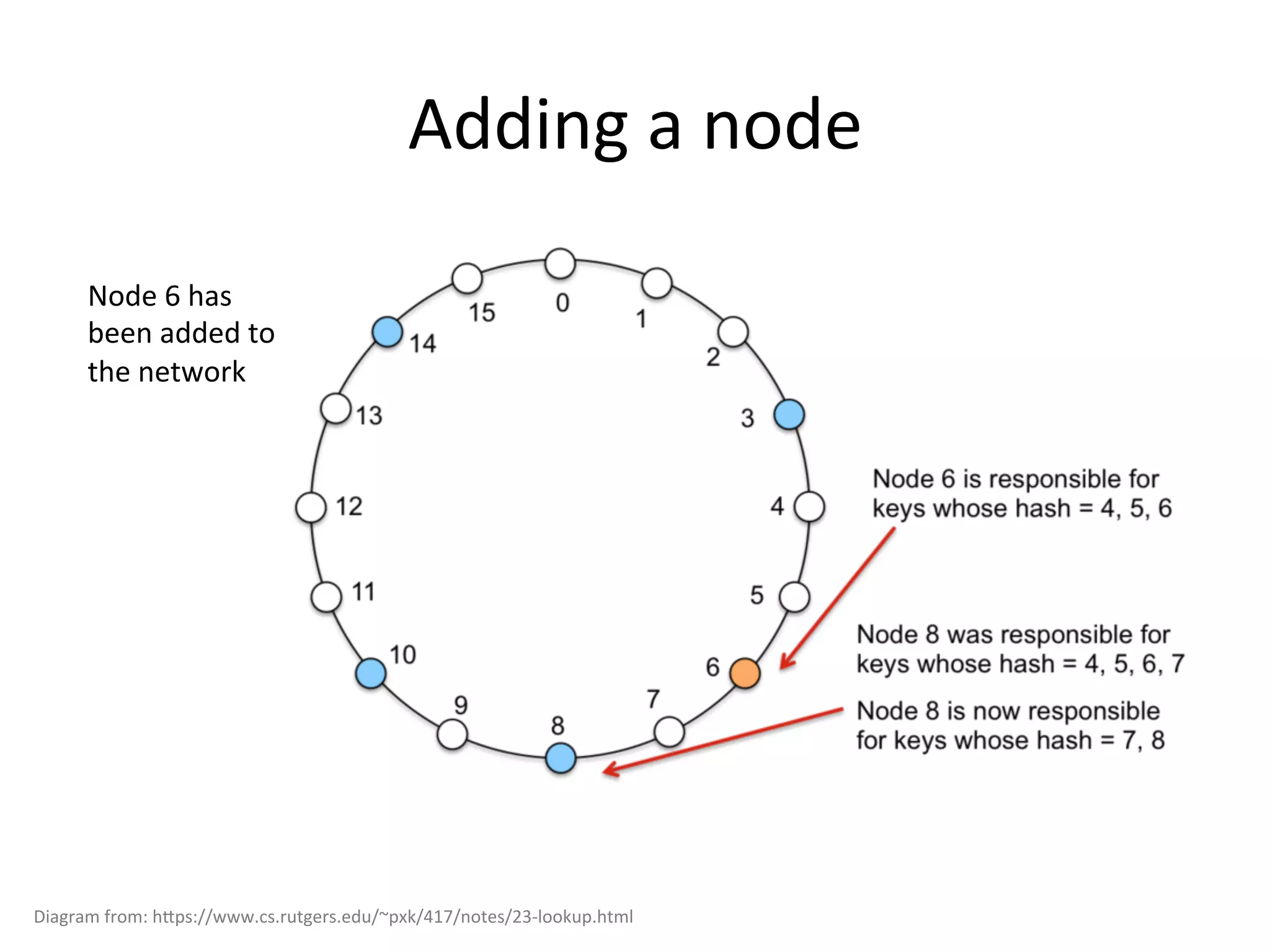

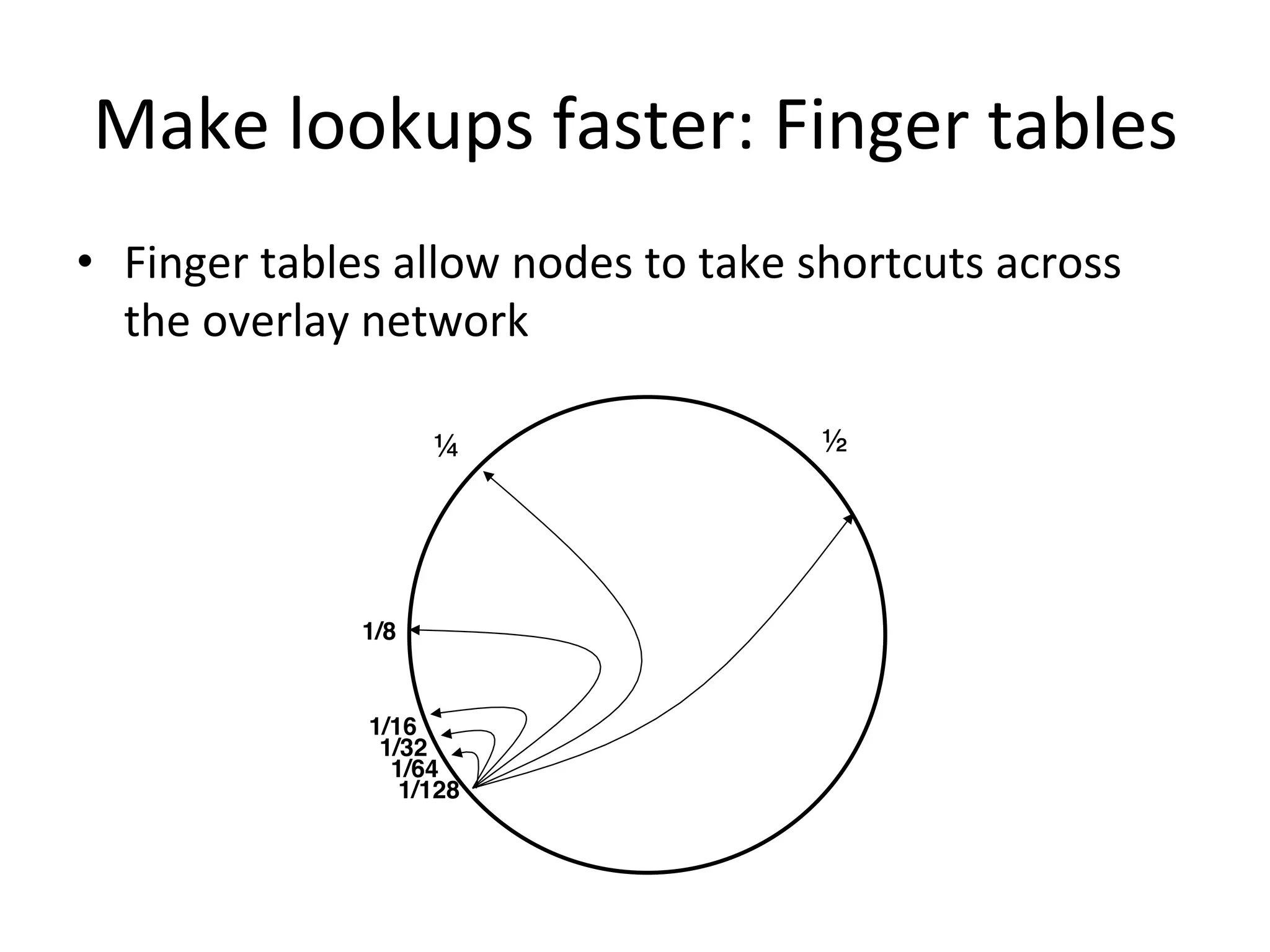
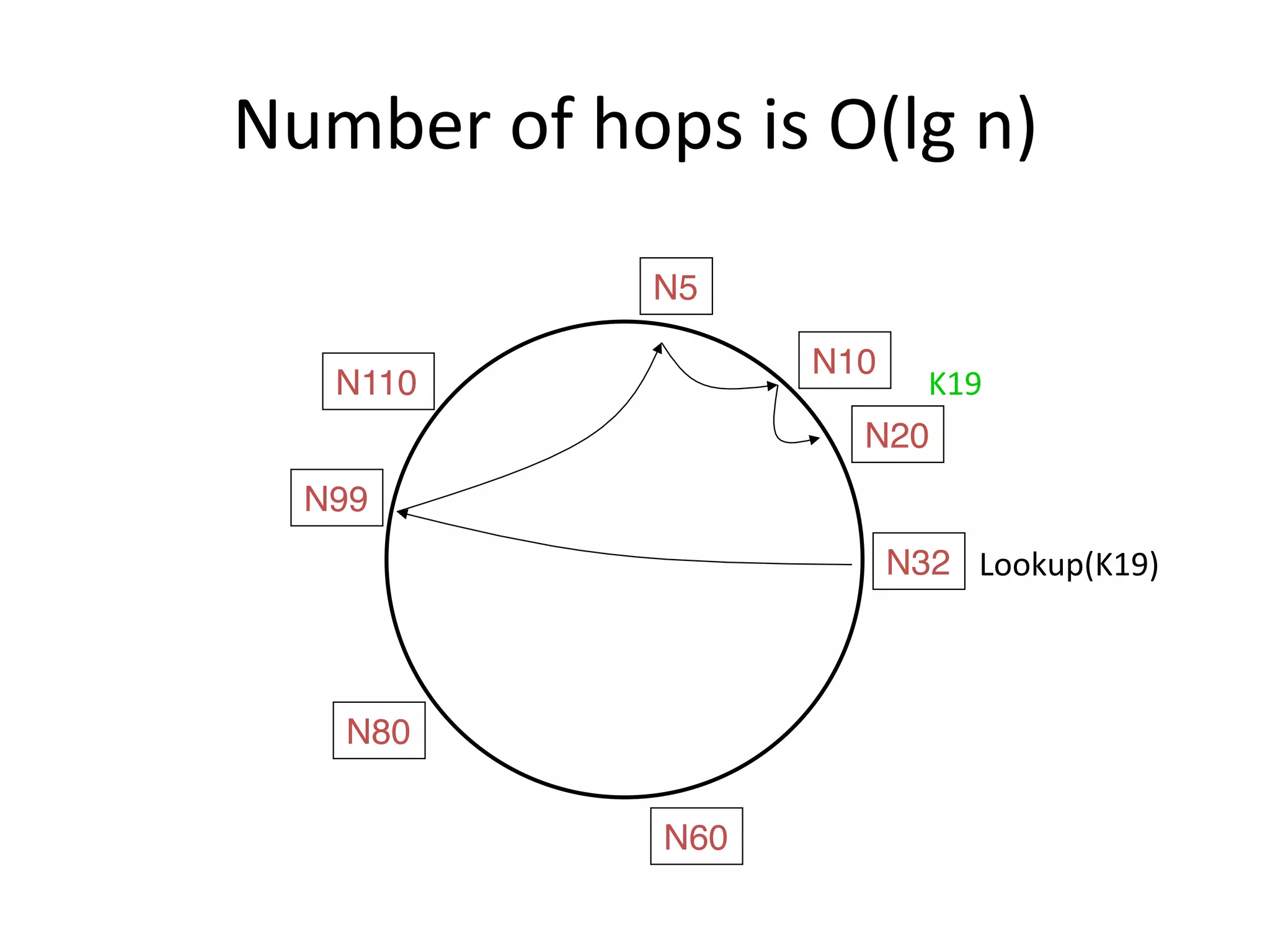
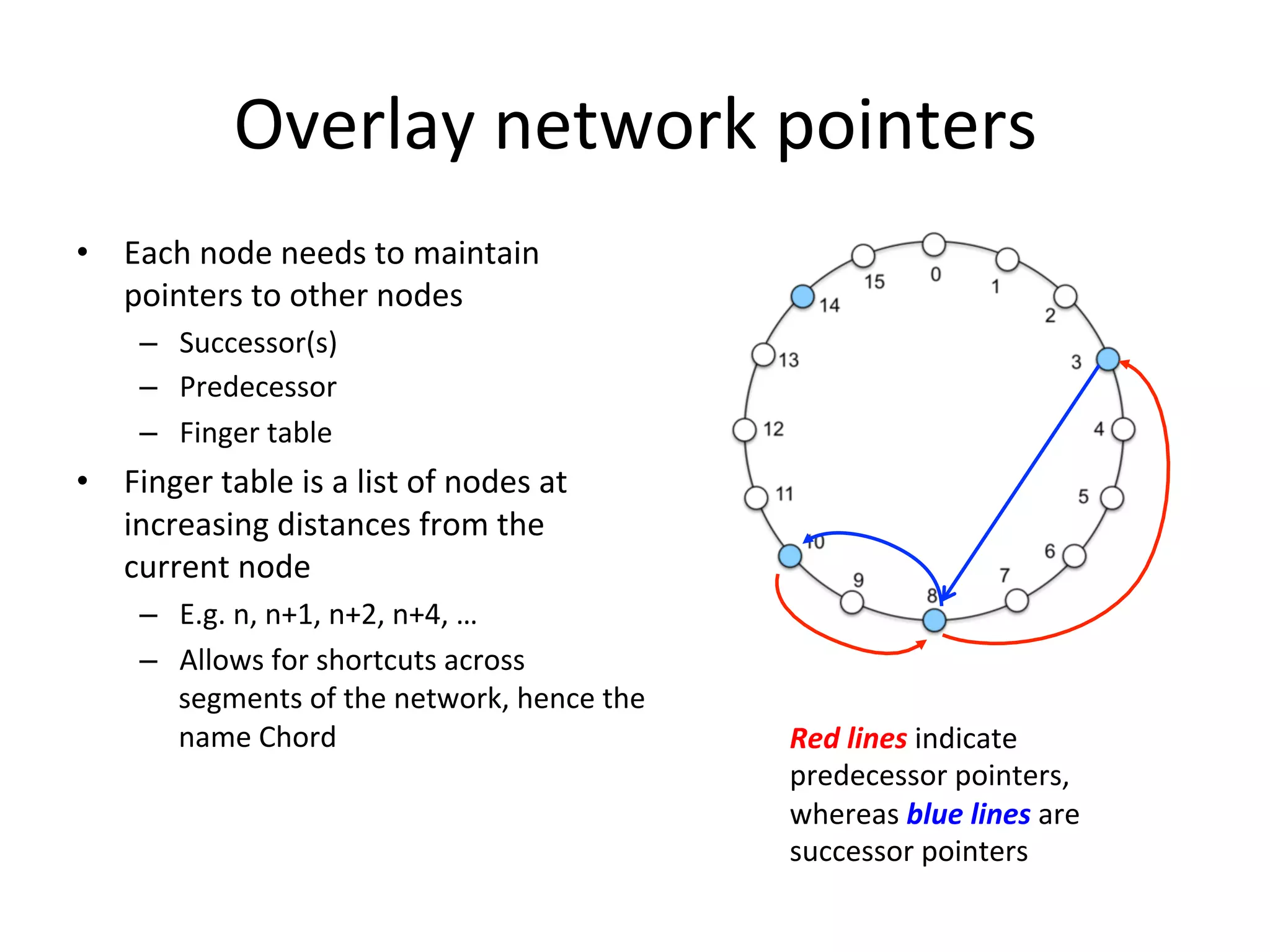



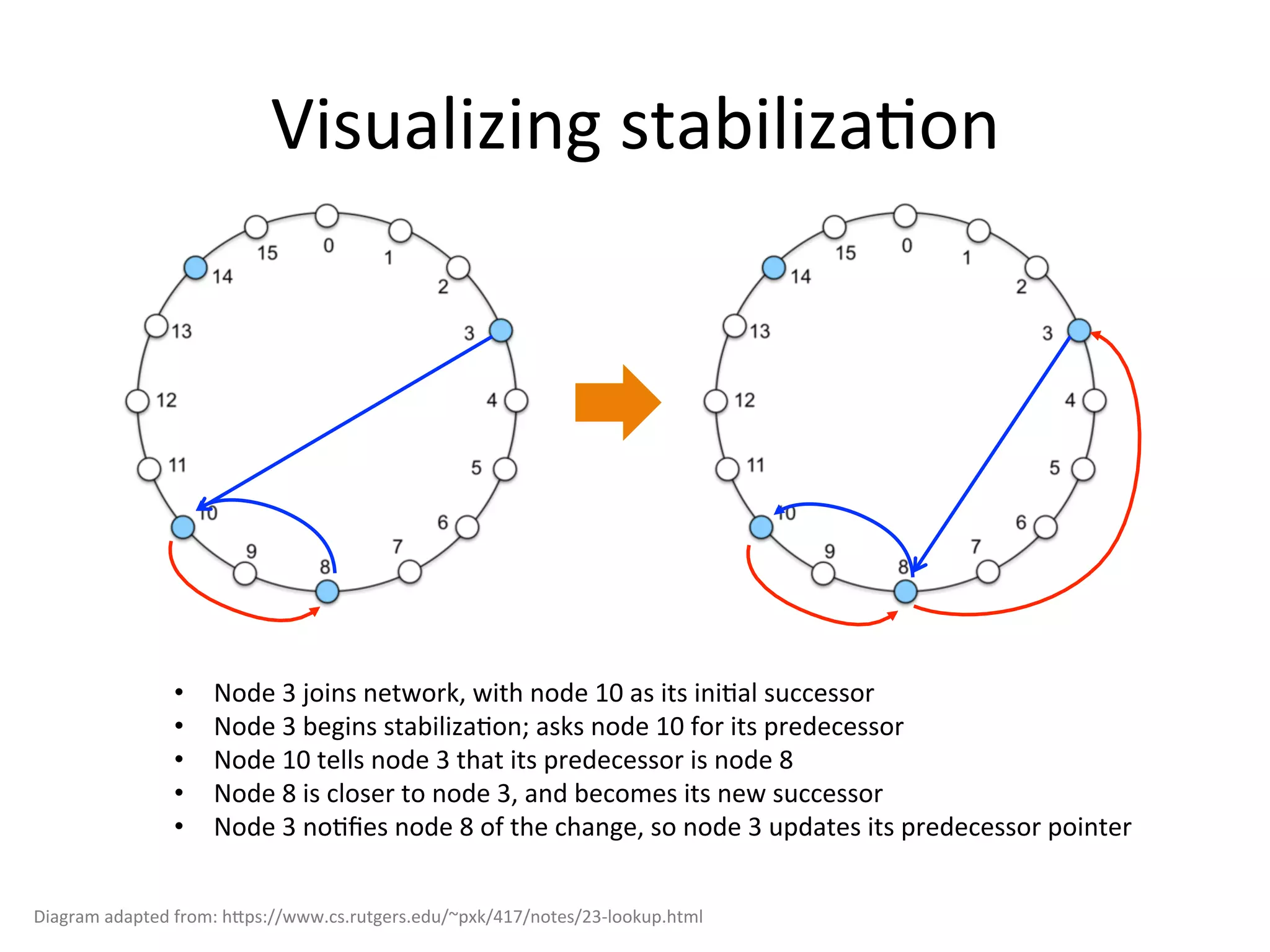











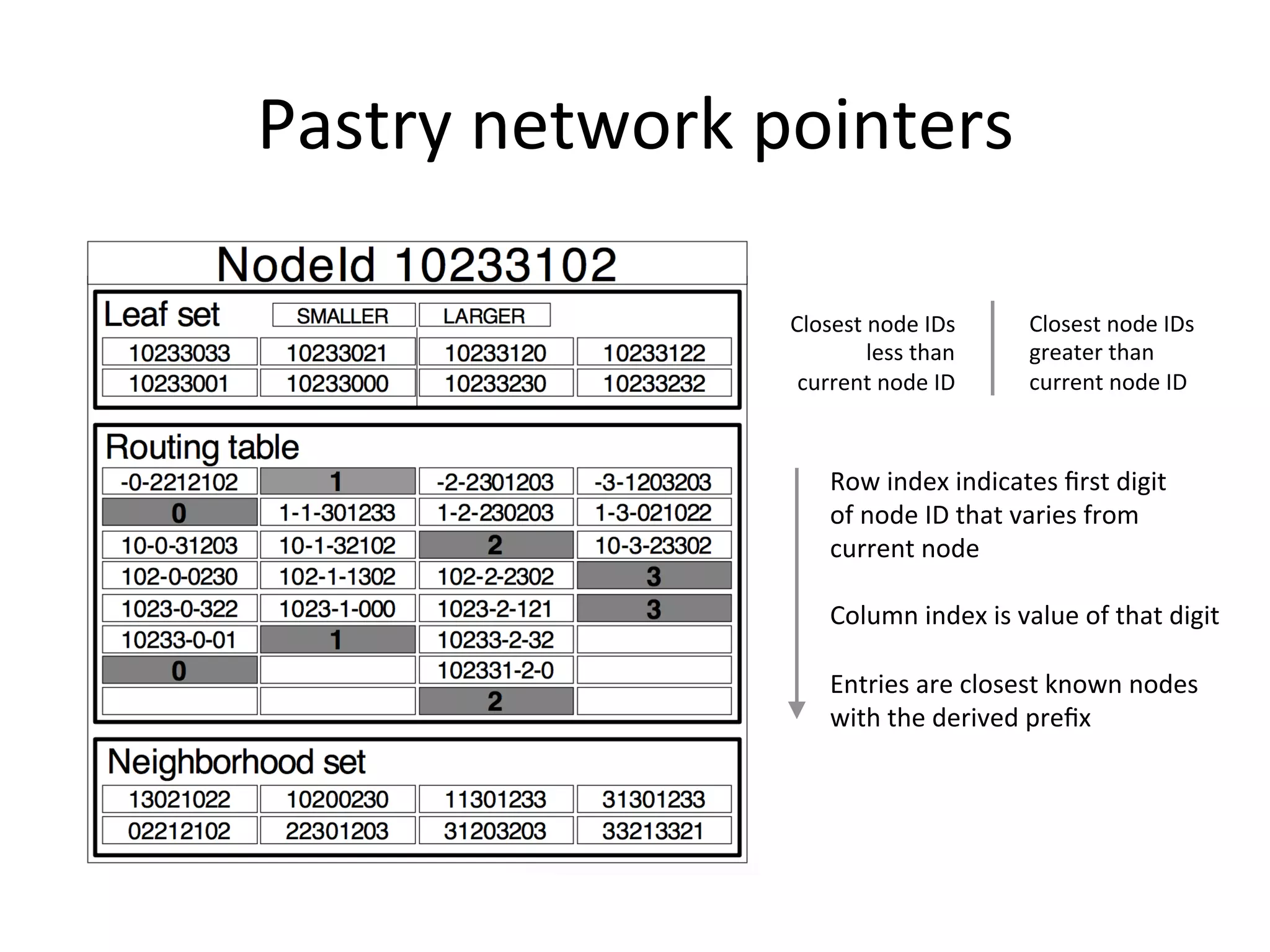






Chord is a scalable peer-to-peer lookup protocol designed for internet applications, aimed at efficiently identifying nodes responsible for keys within distributed hash tables. It utilizes consistent hashing and logarithmic hop counts to enhance performance and resilience as nodes join or leave the network. The protocol addresses challenges related to scaling, reliability, and the dynamic nature of peer-to-peer networks, with various algorithms for managing node relationships and maintaining correctness.




















































































