Download as PDF, PPTX


























![Unicode & Python
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-33-320.jpg)
![str type
>>>euro_bytestring = '€'
!
>>>type(euro_bytestring)
<type 'str'>
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-34-320.jpg)
![unicode type
# € code point
>>>euro_unicode = u'u20ac'
!
>>>type(euro_unicode)
<type 'unicode'>
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-35-320.jpg)
![Unicode
Code points
u'u20ac'
!
Bytes
UTF-8
'xe2x82xac'
!
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-36-320.jpg)
![Unicode
Code points
u'u20ac'
'xe2x82xac'.decode('utf8')
!
Bytes
UTF-8
'xe2x82xac'
!
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-37-320.jpg)
![Unicode
Code points
u'u20ac'
'xe2x82xac'.decode('utf8')
!
Bytes
UTF-8
'xe2x82xac'
!
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-38-320.jpg)
![Unicode
Code points
u'u20ac'
'xe2x82xac'.decode('utf8')
u'u20ac'.encode('utf8')
!
Bytes
UTF-8
'xe2x82xac'
!
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-39-320.jpg)
![Unicode
Code points
u'u20ac'
'xe2x82xac'.becode('utf8')
u'u20ac'.uncode('utf8')
!
Bytes
UTF-8
'xe2x82xac'
!
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-40-320.jpg)



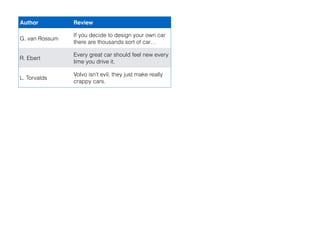
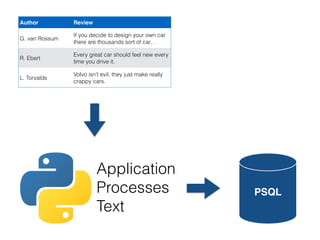





![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-55-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-56-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-57-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-58-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-59-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-60-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-61-320.jpg)


![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-64-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-65-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-66-320.jpg)
![[Python 2.7]
# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-67-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-68-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-69-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-70-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-71-320.jpg)




![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-76-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
!
author, date, review_text = row_text.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-77-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
unicode_row = row_text.decode()
author, date, review_text = unicode_row.split(",")
converted_review = review_text.replace("Montreal",
"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-78-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
unicode_row = row_text.decode()
author, date, review_text = unicode_row.split(u",")
converted_review = review_text.replace(u"Montreal",
u"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-79-320.jpg)



![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
unicode_row = row_text.decode()
author, date, review_text = unicode_row.split(u",")
converted_review = review_text.replace(u"Montreal",
u"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-83-320.jpg)

![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
unicode_row = row_text.decode("cp1252")
author, date, review_text = unicode_row.split(u",")
converted_review = review_text.replace(u"Montreal",
u"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-85-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
unicode_row = row_text.decode("cp1252")
author, date, review_text = unicode_row.split(u",")
converted_review = review_text.replace(u"Montreal",
u"Montréal")
DB.insert(ReviewTable, author, date,
converted_review)
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-86-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
unicode_row = row_text.decode("cp1252")
author, date, review_text = unicode_row.split(u",")
converted_review = review_text.replace(u"Montreal",
u"Montréal")
DB.insert(ReviewTable,
author.encode("utf8"),
date.encode("utf8"),
converted_review.encode("utf8"))
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-87-320.jpg)




![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
unicode_row = row_text.decode("cp1252")
author, date, review_text = unicode_row.split(u",")
converted_review = review_text.replace(u"Montreal",
u"Montréal")
DB.insert(ReviewTable,
author.encode("utf8"),
date.encode("utf8"),
converted_review.encode("utf8"))
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-92-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
unicode_row = row_text.decode("cp1252")
author, date, review_text = unicode_row.split(u",")
converted_review = review_text.replace(u"Montreal",
u"Montréal")
DB.insert(ReviewTable,
author.encode("utf8"),
date.encode("utf8"),
converted_review.encode("utf8"))
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-93-320.jpg)
![# -*- coding: utf-8 -*-
!
reviews_file = open("reviews_file.csv")
!
for row_text in reviews_file:
unicode_row = row_text.decode("cp1252")
author, date, review_text = unicode_row.split(u",")
converted_review = review_text.replace(u”Montreal",
u"Montréal")
DB.insert(ReviewTable,
author.encode("utf8"),
date.encode("utf8"),
converted_review.encode("utf8"))
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-94-320.jpg)

![Test encoding ranges
& boundaries
test_strings = ['Hello Montreal!',
'¡ןɐǝɹʇuoɯ oןןǝɥ',
'ђєɭɭ๏ ๓๏ภՇгєค !']
!
func_under_test(test_strings)](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-96-320.jpg)























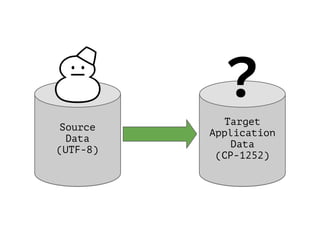
![>>>u'☃ Brrrr!'.encode('cp1252', 'strict')
!
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/esther/ENV/lib/python2.7/
encodings/cp1252.py", line 12, in encode
return
codecs.charmap_encode(input,errors,encoding_
table)
UnicodeEncodeError: 'charmap' codec can't
encode character u'u2603' in position 0:
character maps to <undefined>
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-127-320.jpg)
![>>>u'☃ Brrrr!'.encode('cp1252', 'ignore')
!
' Brrrr!'
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-128-320.jpg)
![>>>u'☃ Brrrr!'.encode('cp1252', 'replace')
!
'? Brrrr!'
[Python 2.7]](https://image.slidesharecdn.com/unicodeandcharacterencoding-140410003026-phpapp01/85/Character-Encoding-Unicode-How-to-with-dignity-129-320.jpg)







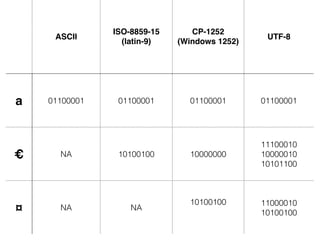
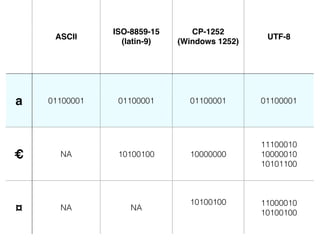
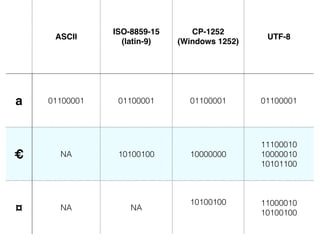
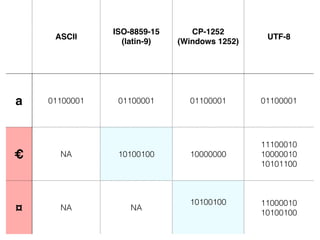
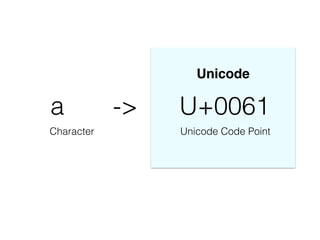
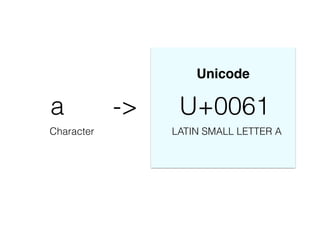
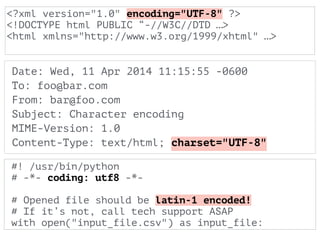
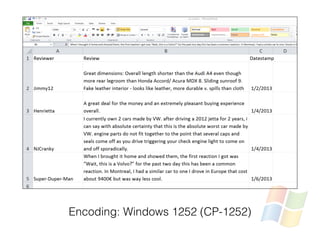
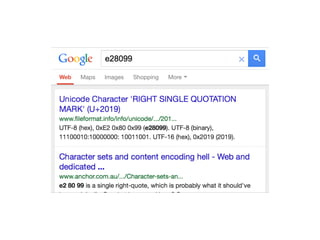
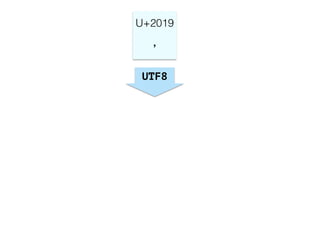
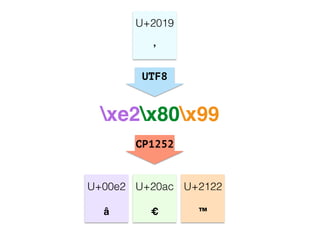
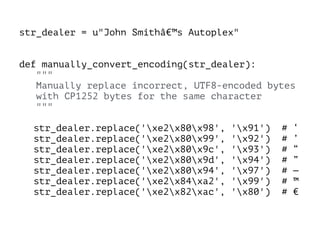
The document discusses character encoding, specifically focusing on the transformation of text data through various encoding formats like UTF-8 and Latin-1. It provides examples of issues that arise with different encodings, illustrating the importance of knowing and handling character sets in programming and data processing. Additionally, the document features sample Python code for working with encodings and demonstrates the challenges of maintaining text integrity across different systems.