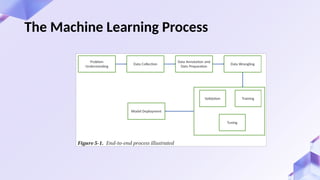
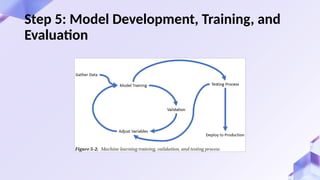
The document introduces machine learning with scikit-learn, focusing on how algorithms learn from data to improve over time. It outlines the differences between supervised and unsupervised learning, detailing their applications and the six key stages in the machine learning process—from problem understanding to model deployment. Furthermore, it highlights the importance of data quality and provides practical insights via experiments with the scikit-learn library.



















![Understanding the API
• Features: Numerical variables representing data points.
• Estimators: Learn patterns from data (e.g., classification, regression).
• Predictors: Make predictions on new data.
• Transformers: Preprocess and transform data (e.g., scaling, feature
extraction).
• Chaining Estimators: Combine multiple estimators for complex tasks.
• Pipeline Objects: Simplify the process of chaining multiple estimators
into a single one.
• pipe = Pipeline([('scaler', StandardScaler()), ('svc', SVC())])](https://image.slidesharecdn.com/chapter5introductiontomachinelearningwithscikit-learn-250109023739-d635bf4b/85/Chapter-5-Introduction-to-Machine-Learning-with-Scikit-learn-pptx-21-320.jpg)
























![1_Introduction to Machine Learning [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/1introductiontomachinelearningautosaved-250910004933-3913b711-thumbnail.jpg?width=640&height=640&fit=bounds)


























