Download as PDF, PPTX







![Ø It is rarely enough to provide just the results. Rather, one must provide
supplementary information [called the provenance of the (result) data] that
explains how each result was derived, and based upon precisely what inputs.
Ø Systems with a rich palette of visualizations become important in conveying to the
users the results of the queries in a way that is best understood in the particular
domain.
Ø Furthermore, with a few clicks the user should be able to drill down into each
piece of data that she sees and understand its provenance, which is a key feature to
understanding the data.
7
Interpretation](https://image.slidesharecdn.com/manfredfischer-160904055953/85/Challenges-of-Big-Data-Research-8-320.jpg)










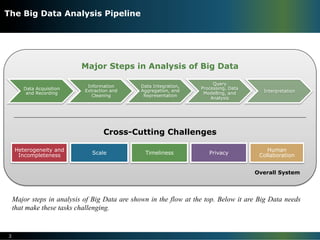
The document discusses the challenges of big data research. It outlines three dimensions of data challenges: volume, velocity, and variety. It then describes the major steps in big data analysis and the cross-cutting challenges of heterogeneity, incompleteness, scale, timeliness, privacy, and human collaboration. Overall, the document argues that realizing the full potential of big data will require addressing significant technical challenges across the entire data analysis pipeline from data acquisition to interpretation.






























![[IJCT-V3I2P32] Authors: Amarbir Singh, Palwinder Singh](https://cdn.slidesharecdn.com/ss_thumbnails/ijct-v3i2p32-160609071950-thumbnail.jpg?width=640&height=640&fit=bounds)
























































