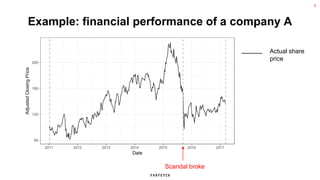
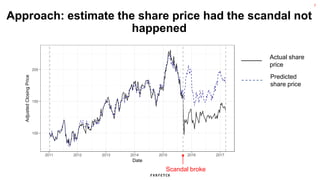
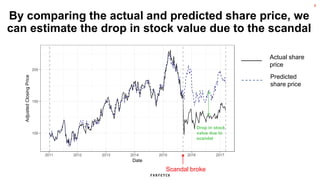
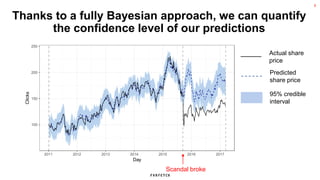
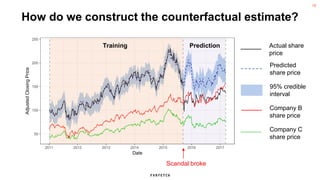
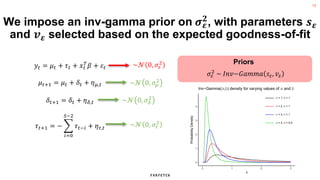
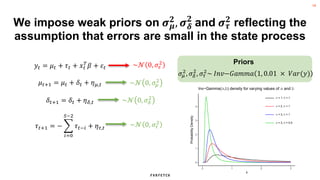
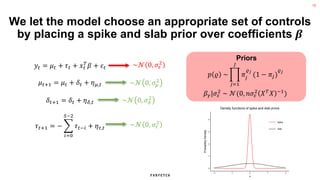
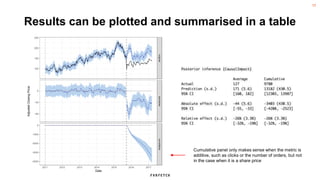
The document discusses the methodology for estimating causal effects in marketing, particularly when traditional A/B testing is unfeasible. It outlines a Bayesian structural time series model to analyze the impact of events, illustrated by an example involving stock price predictions following a scandal. The process includes specifications for model parameters and emphasizes the importance of proper covariate selection and validation techniques.














































![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)











