Download as PDF, PPTX



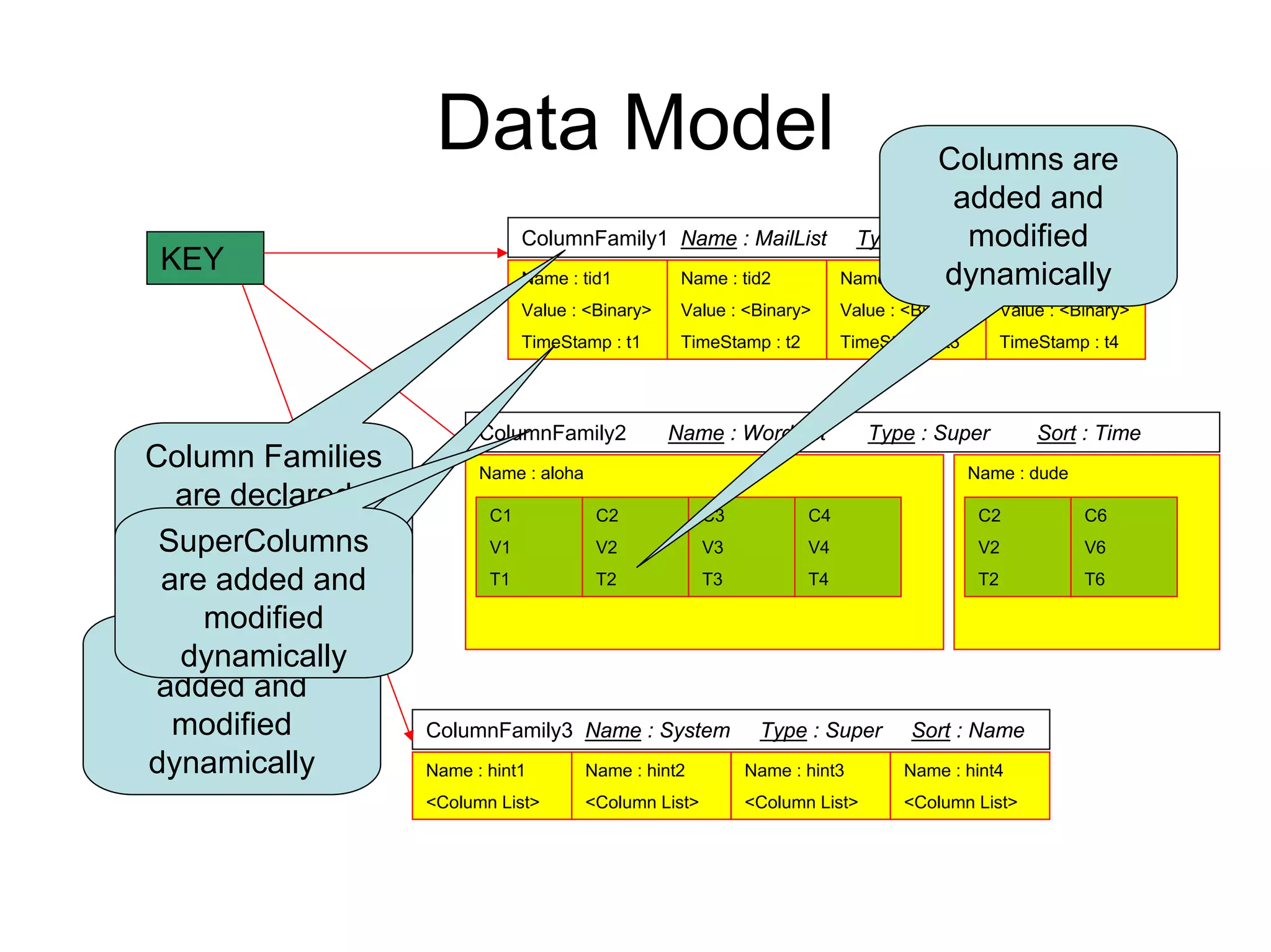

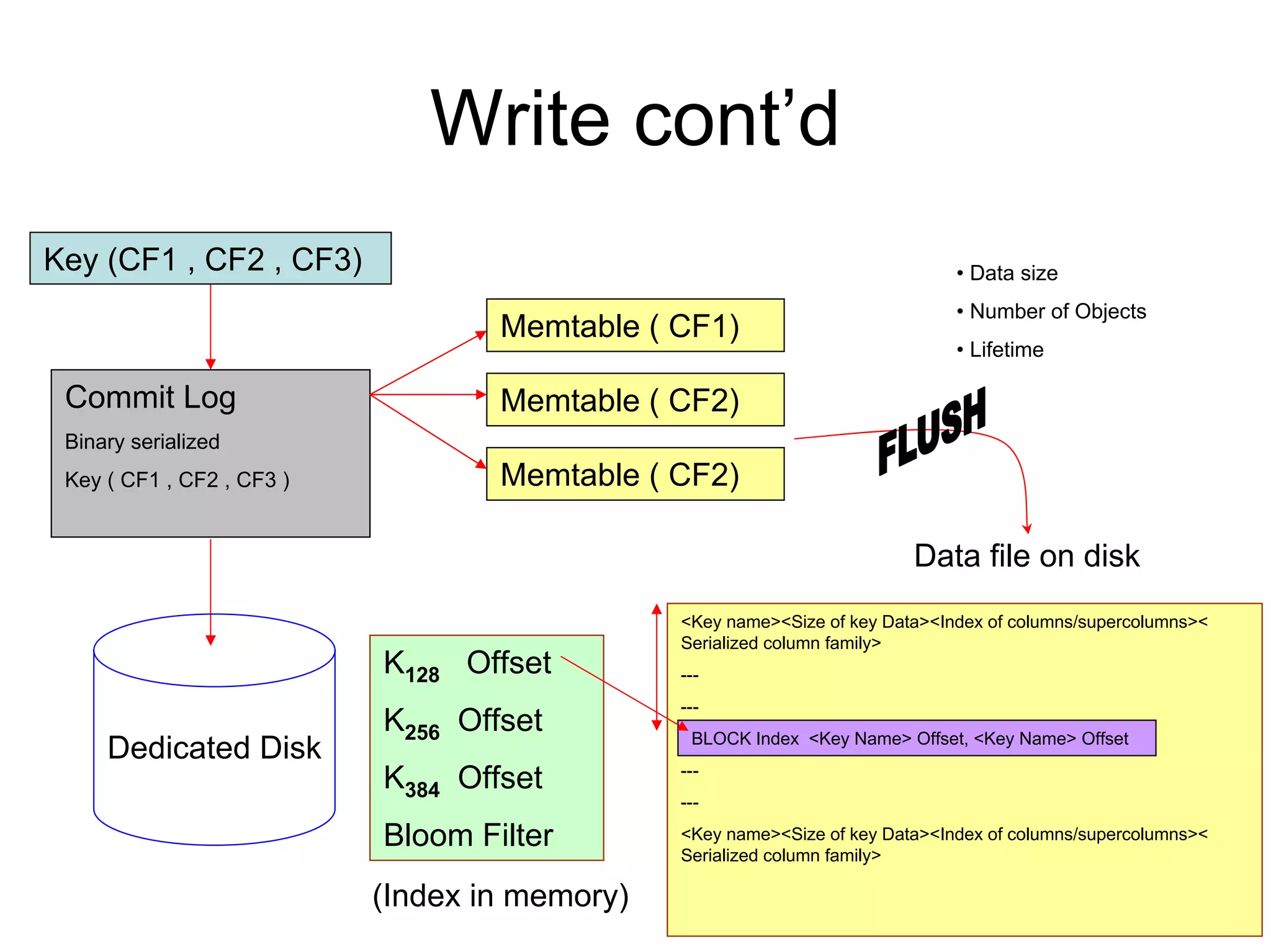
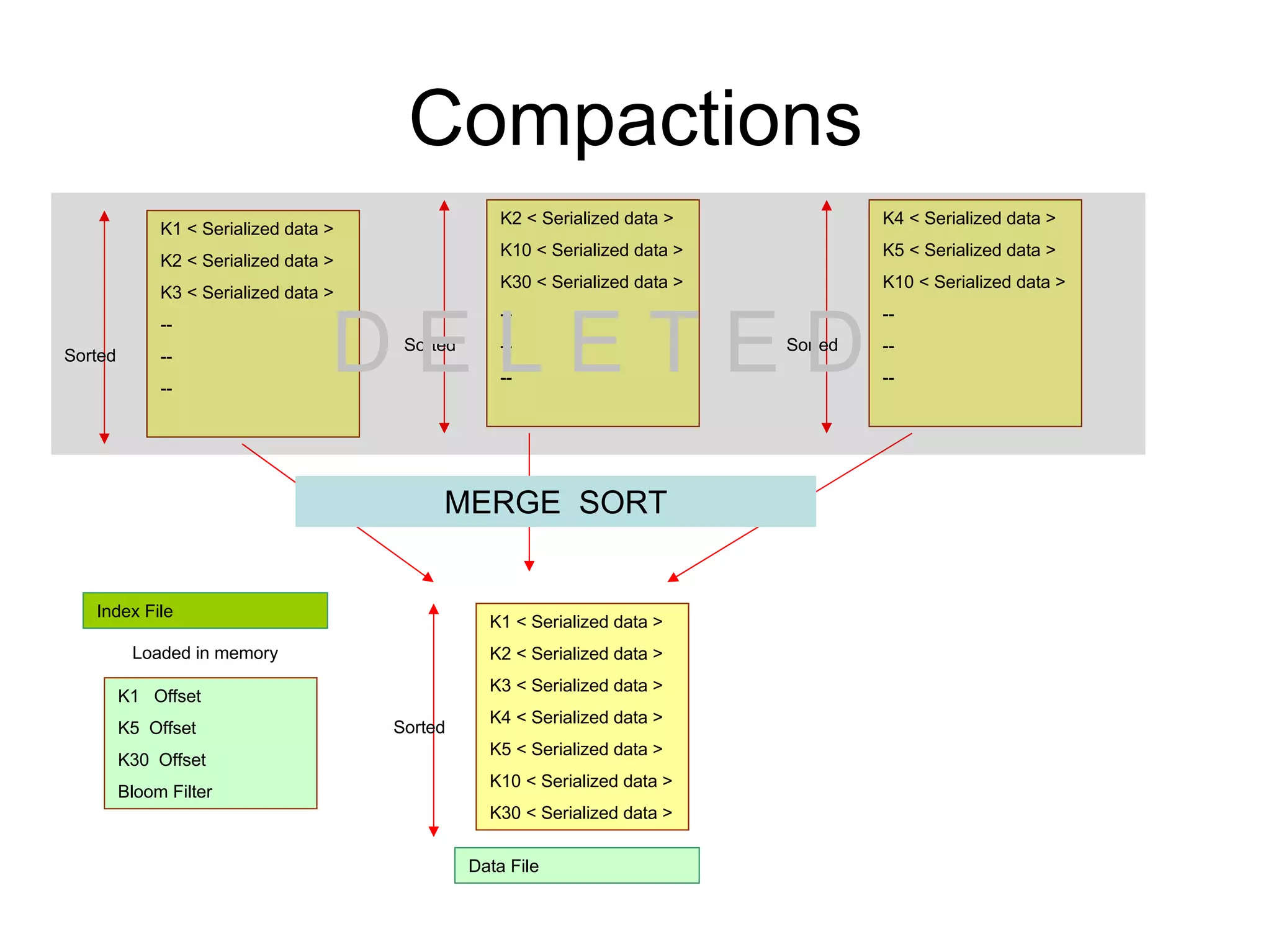

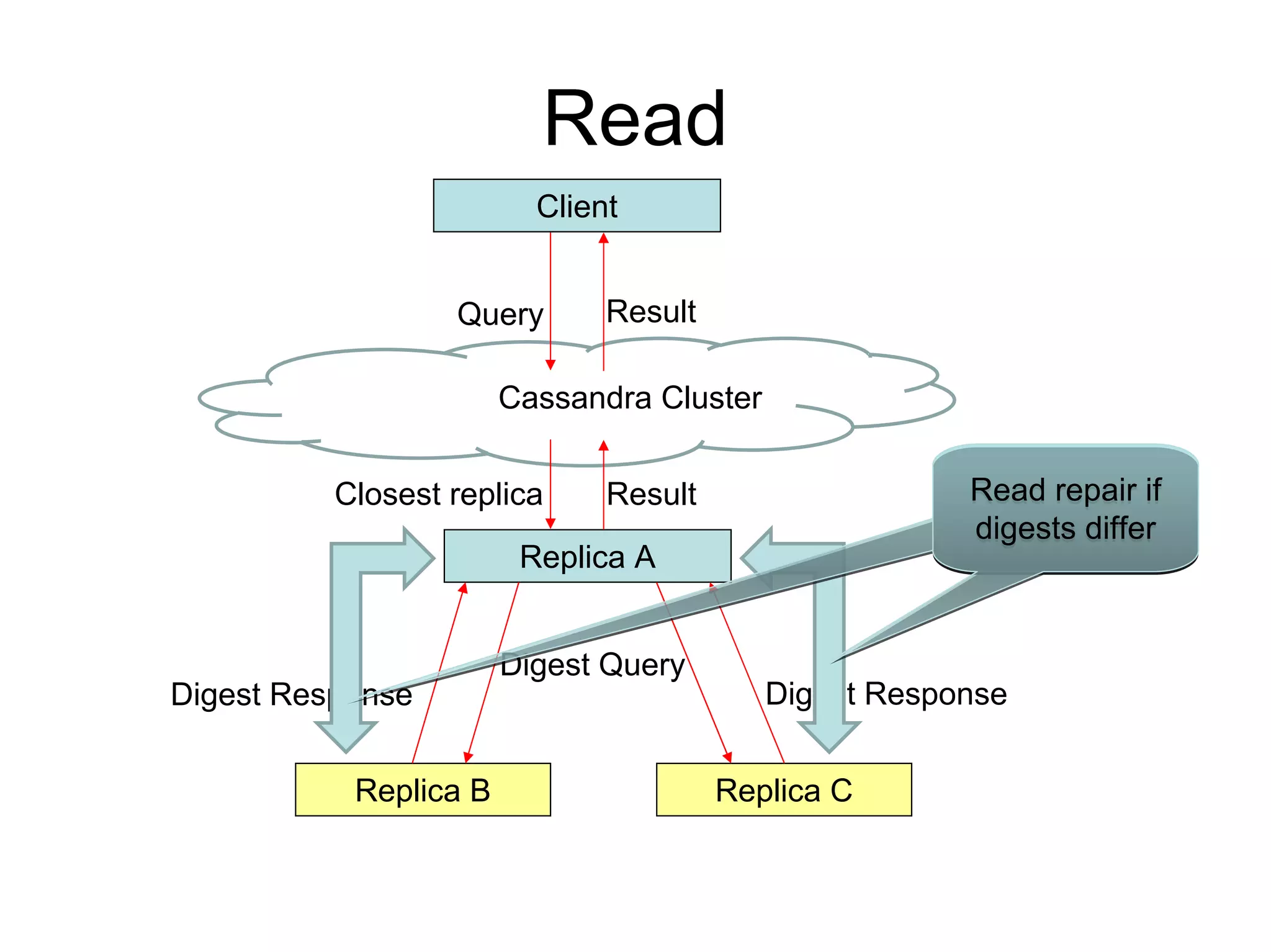
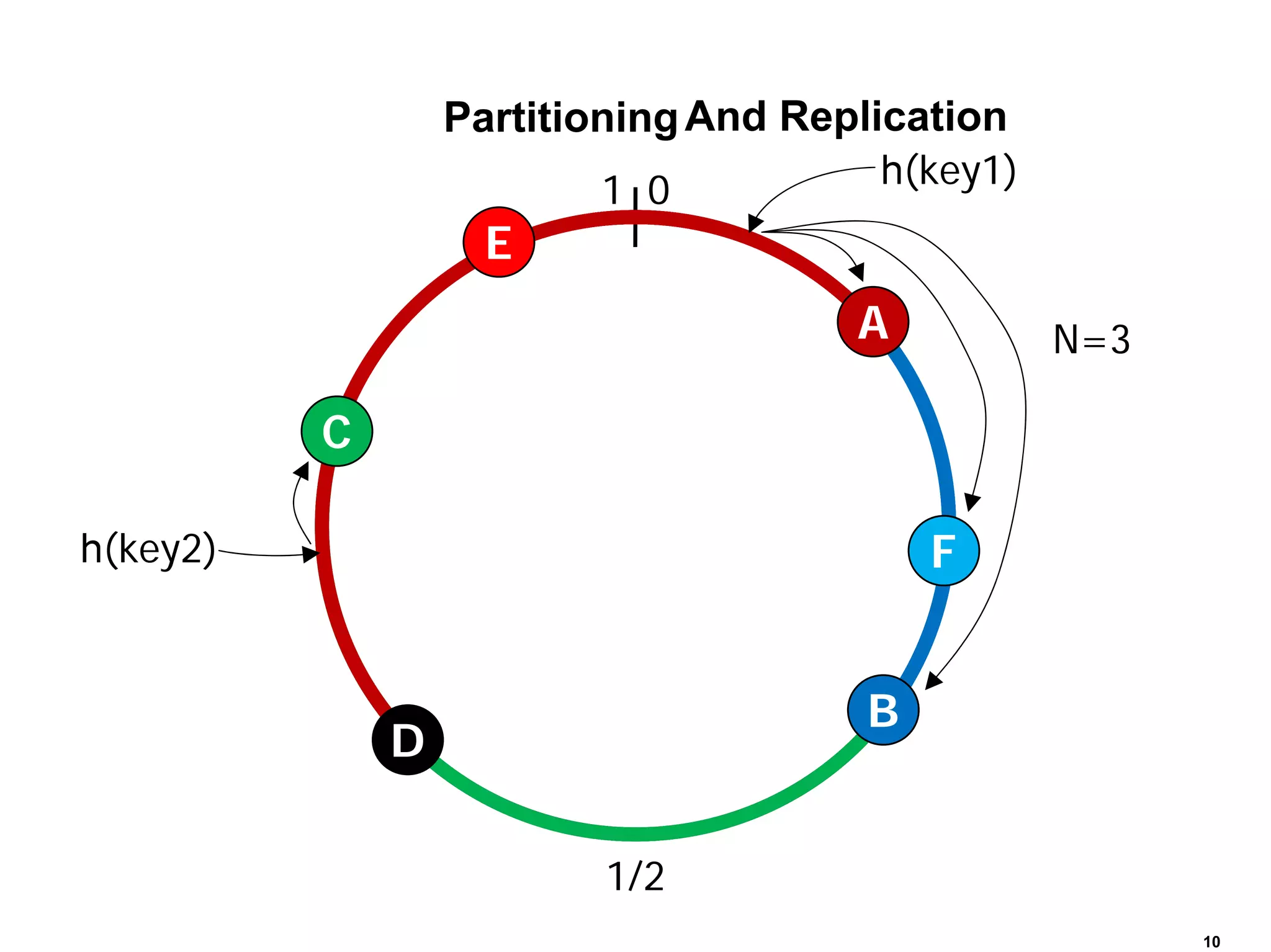

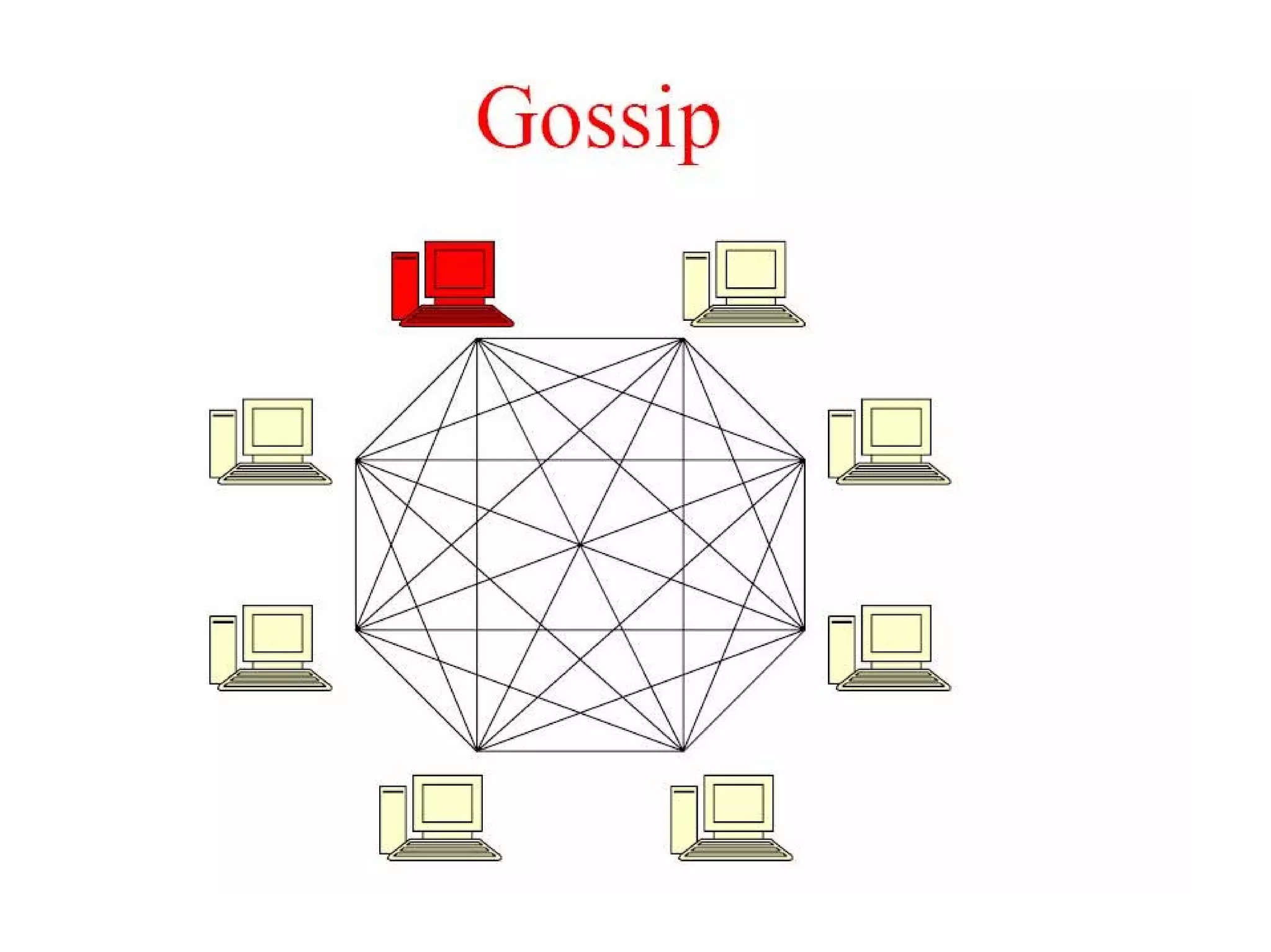
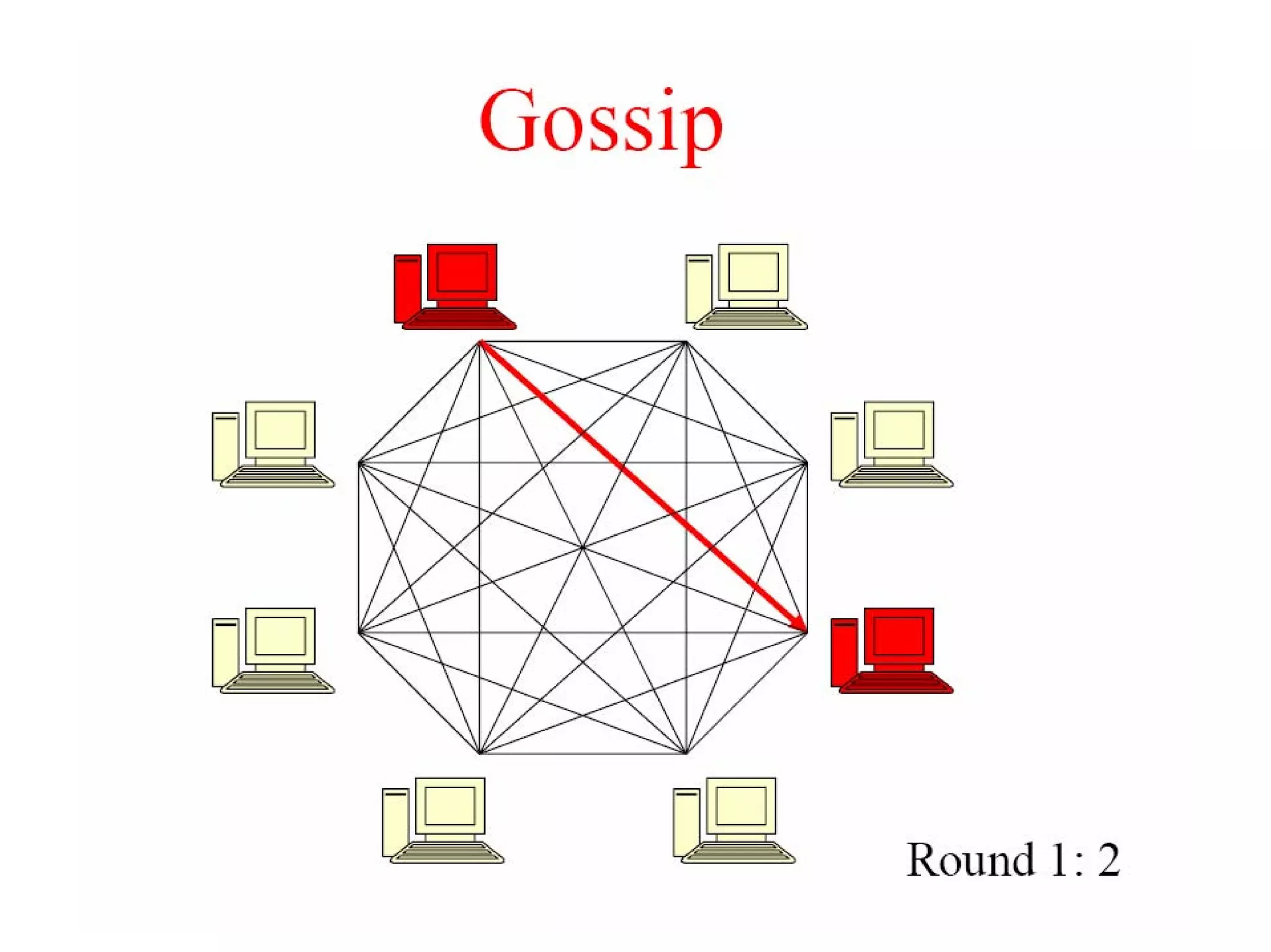
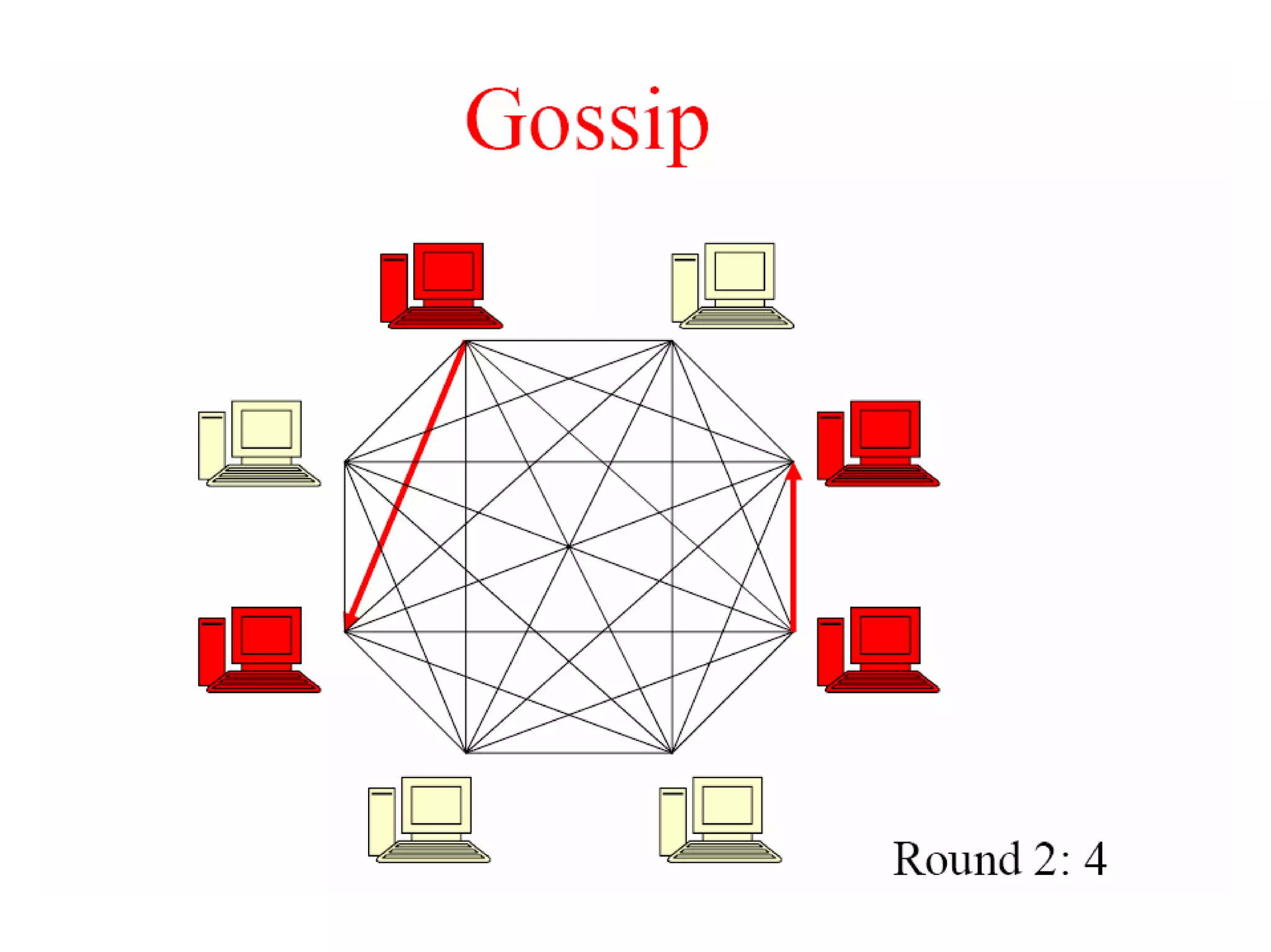



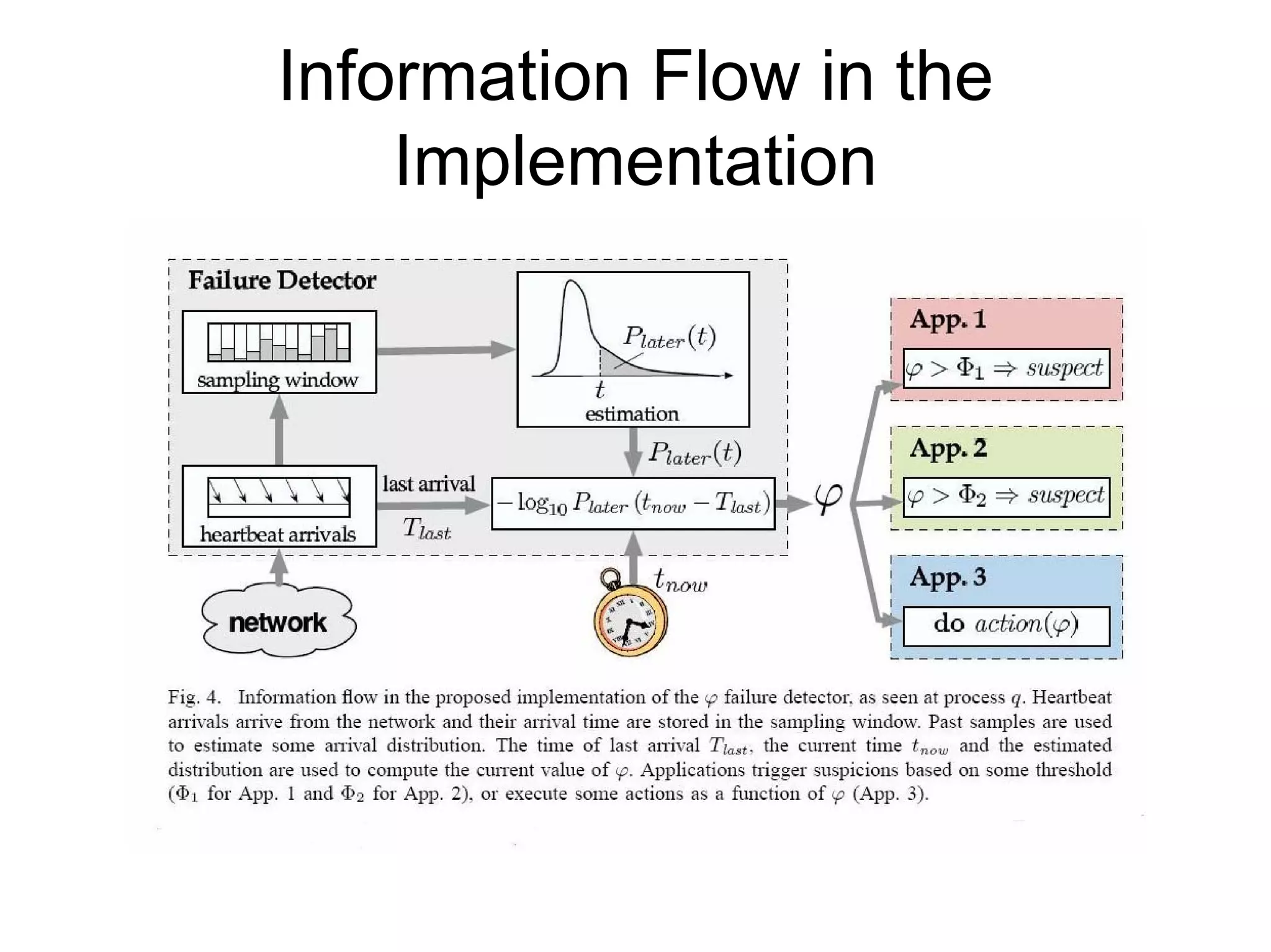



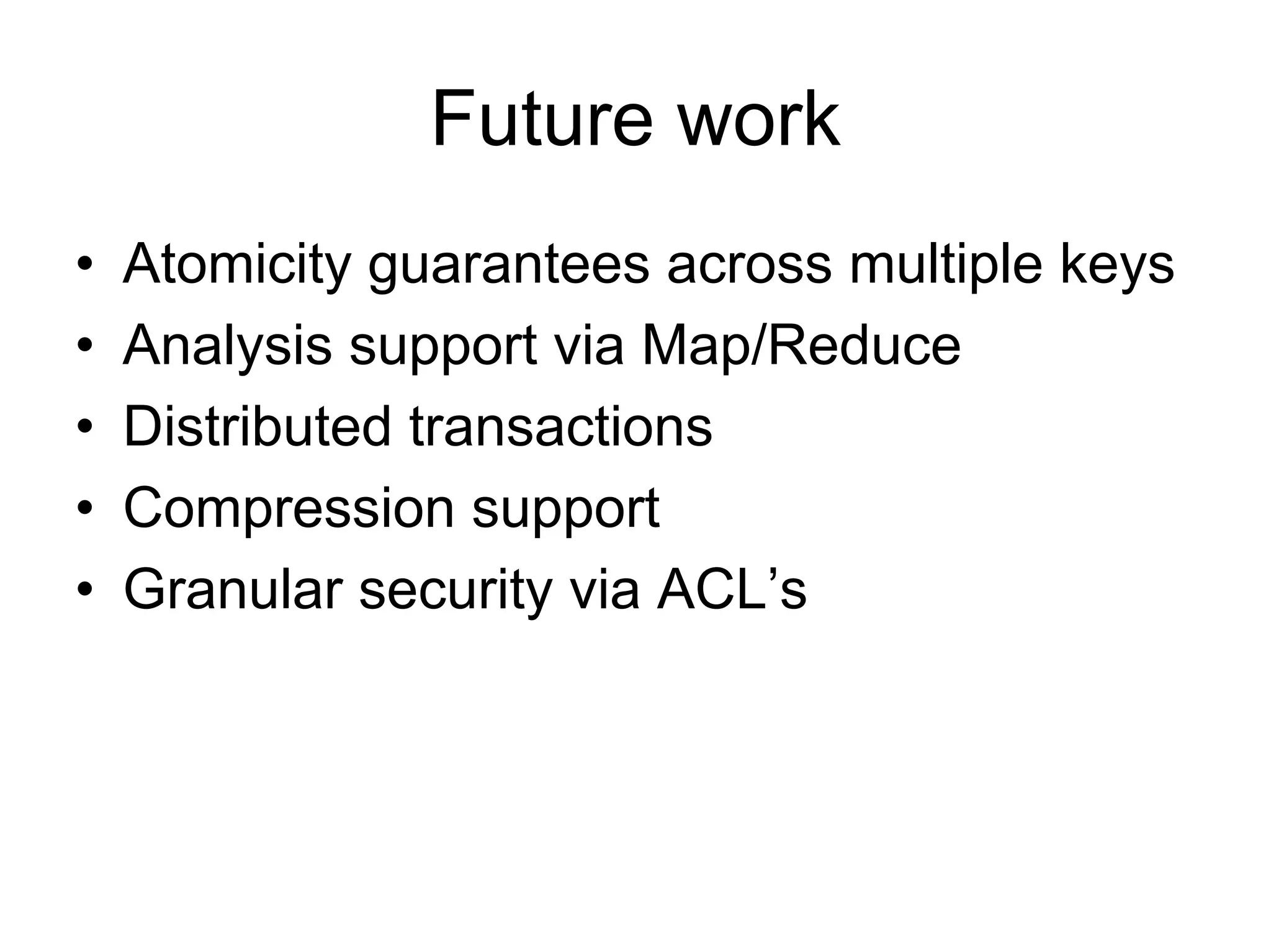


Cassandra is a structured storage system designed to run on a peer-to-peer network. It was created to handle large amounts of data and requests across many servers. Cassandra provides high availability with eventual consistency and incremental scalability. It uses a column-oriented data model and optimizes for writes over reads. Data is partitioned and replicated across nodes using consistent hashing. Failure detection uses a gossip protocol and accrual failure detector.











































































