Download to read offline



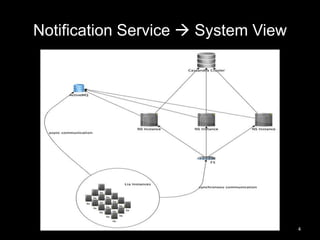



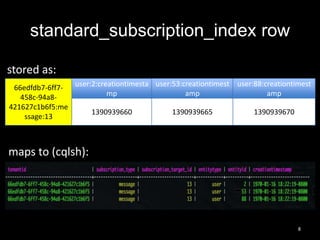

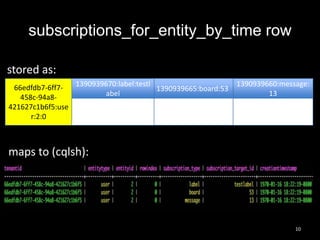

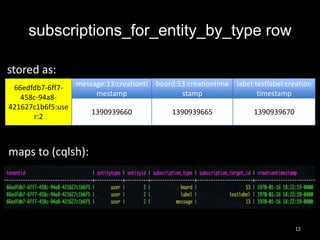



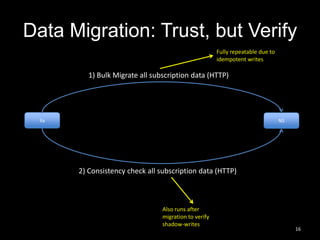
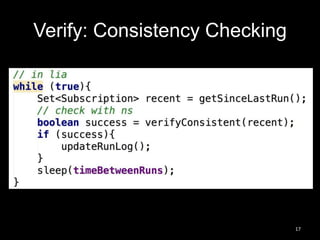
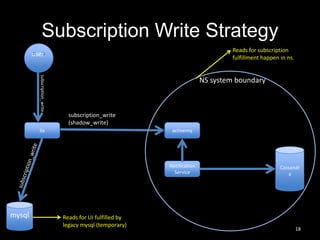


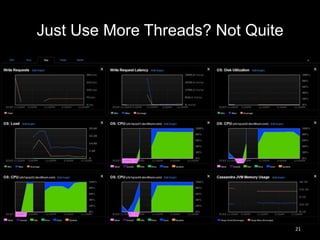












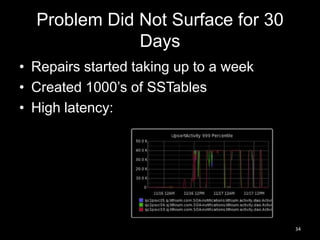





This document summarizes Cassandra usage at Lithium for powering a notification service. It discusses using Cassandra to store subscriptions, activity feeds, and handle high write volumes. Key lessons include having a migration strategy to keep old and new systems live, testing for tombstone buildup over long periods, and understanding how compaction settings impact cleanup. Production issues involved a cluster-wide hard drive failure and activity feed data growth causing repair problems, demonstrating the importance of monitoring and manual cleanup strategies.




































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)










