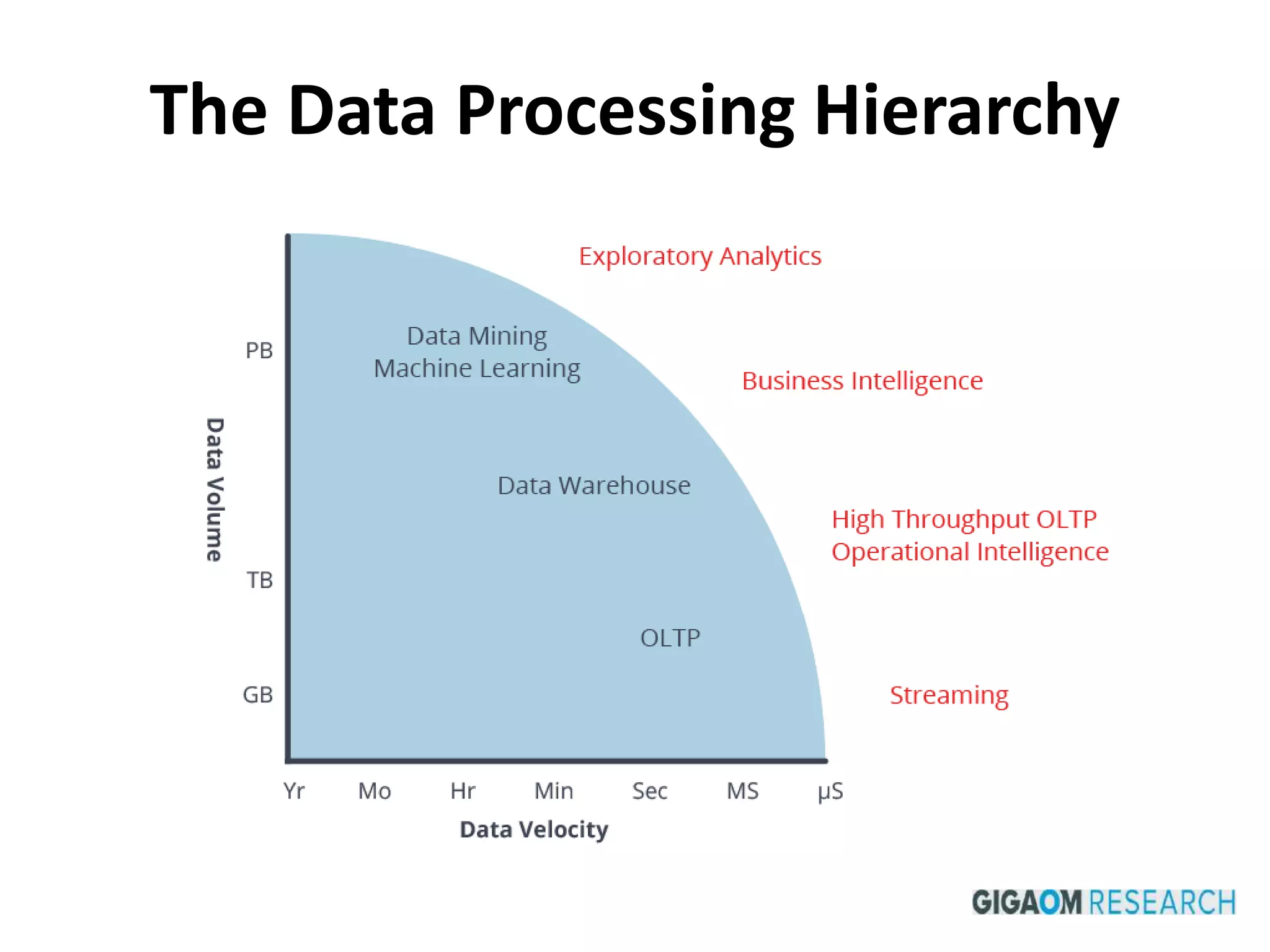
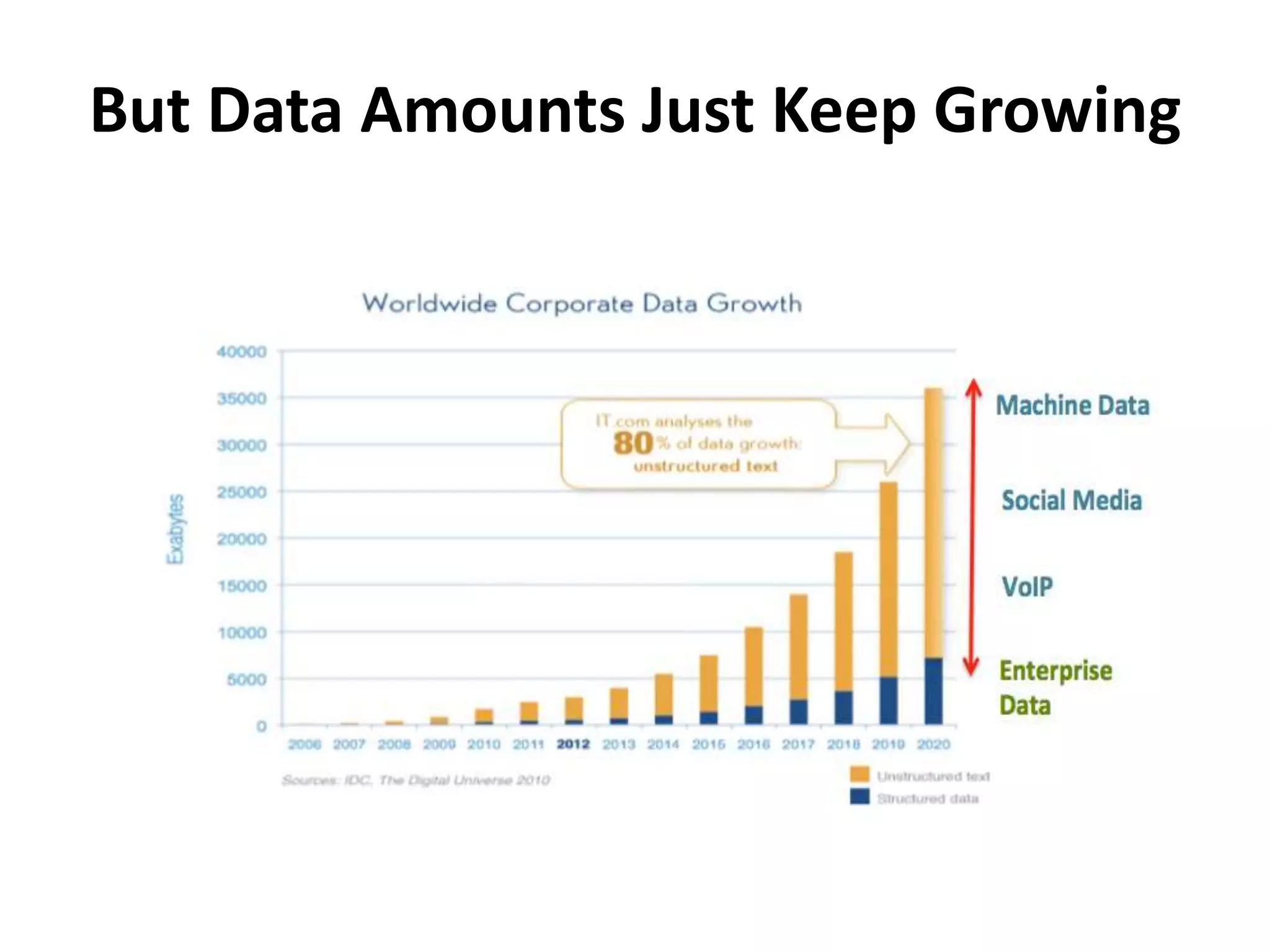
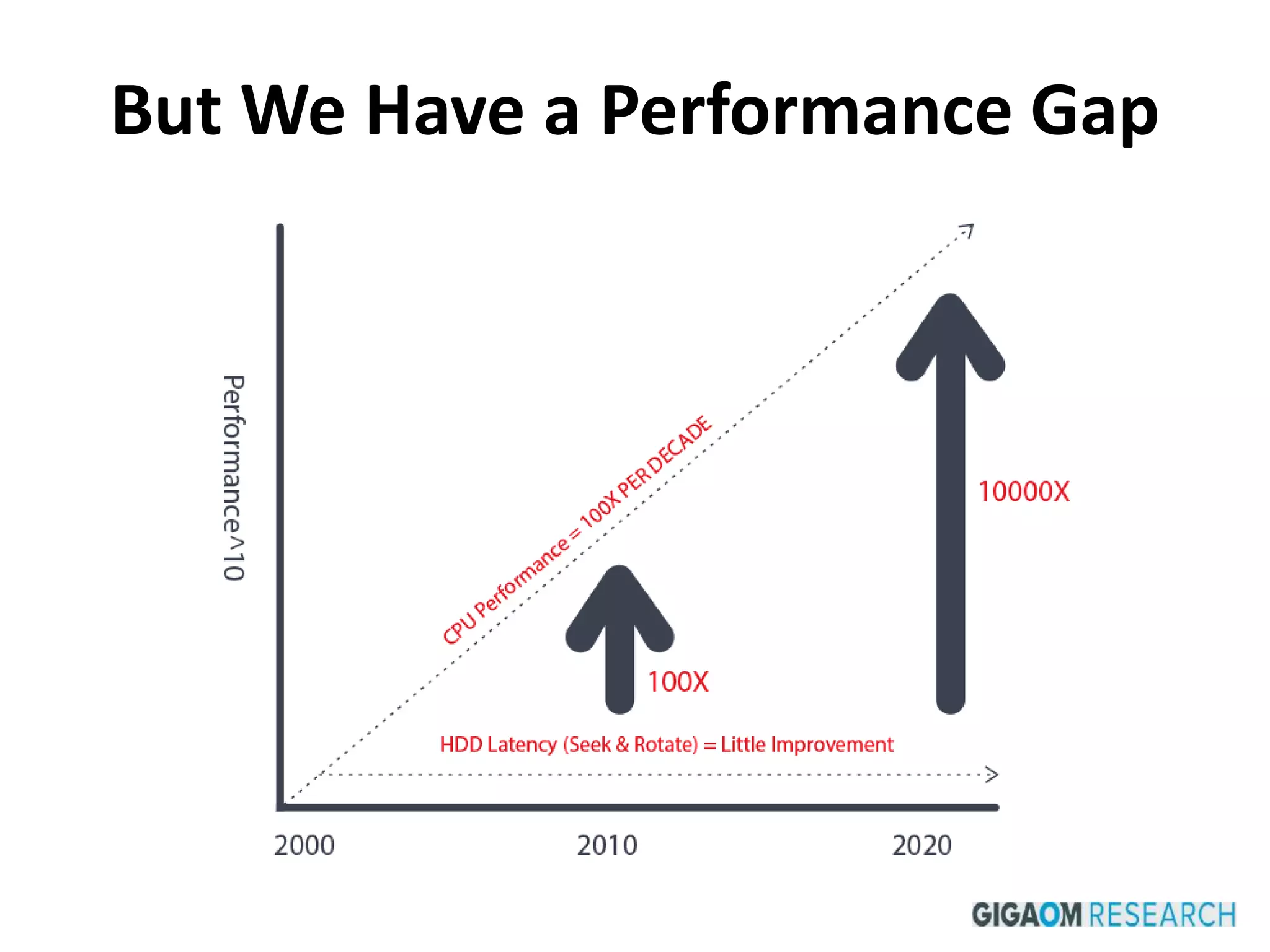
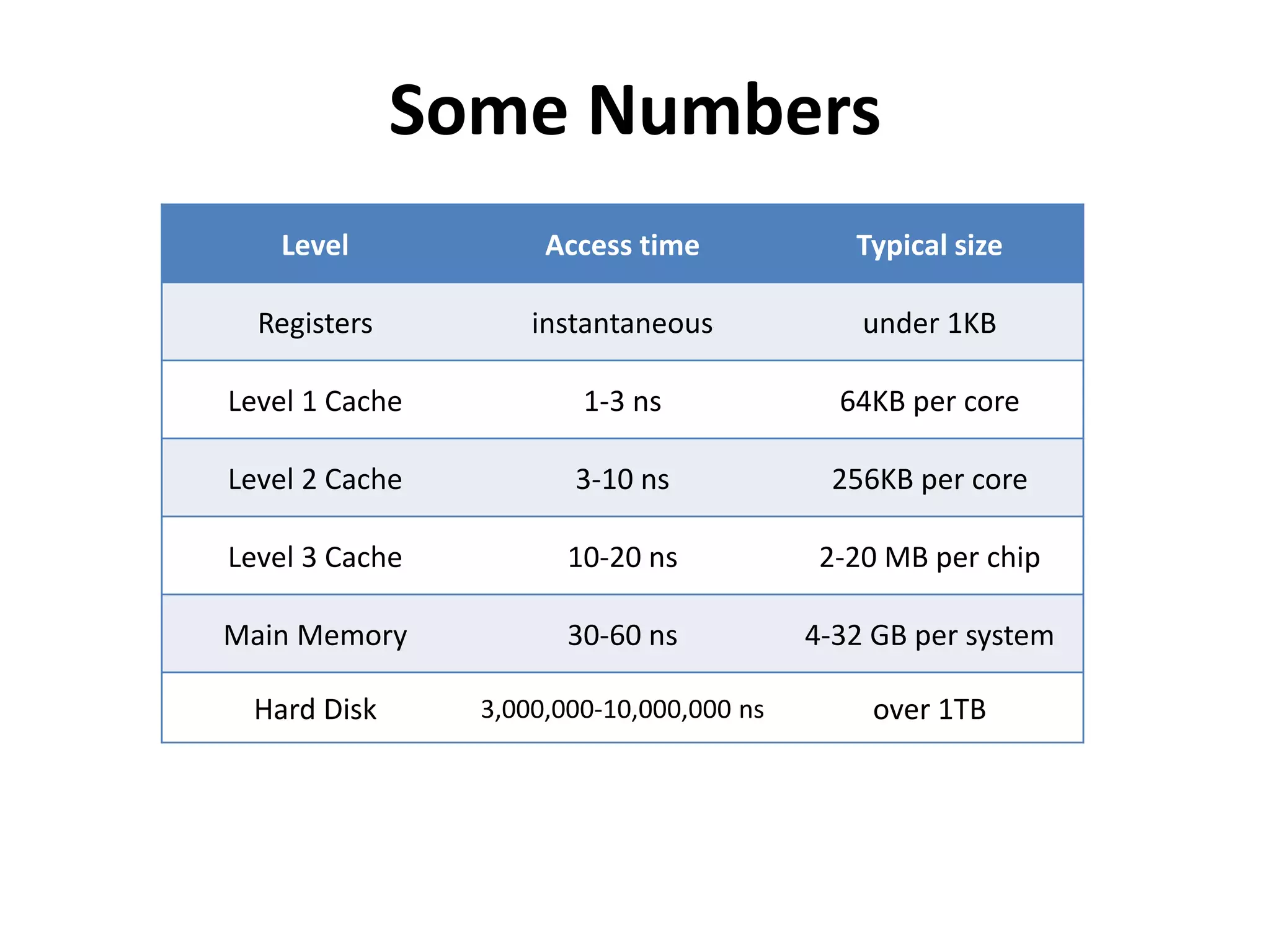
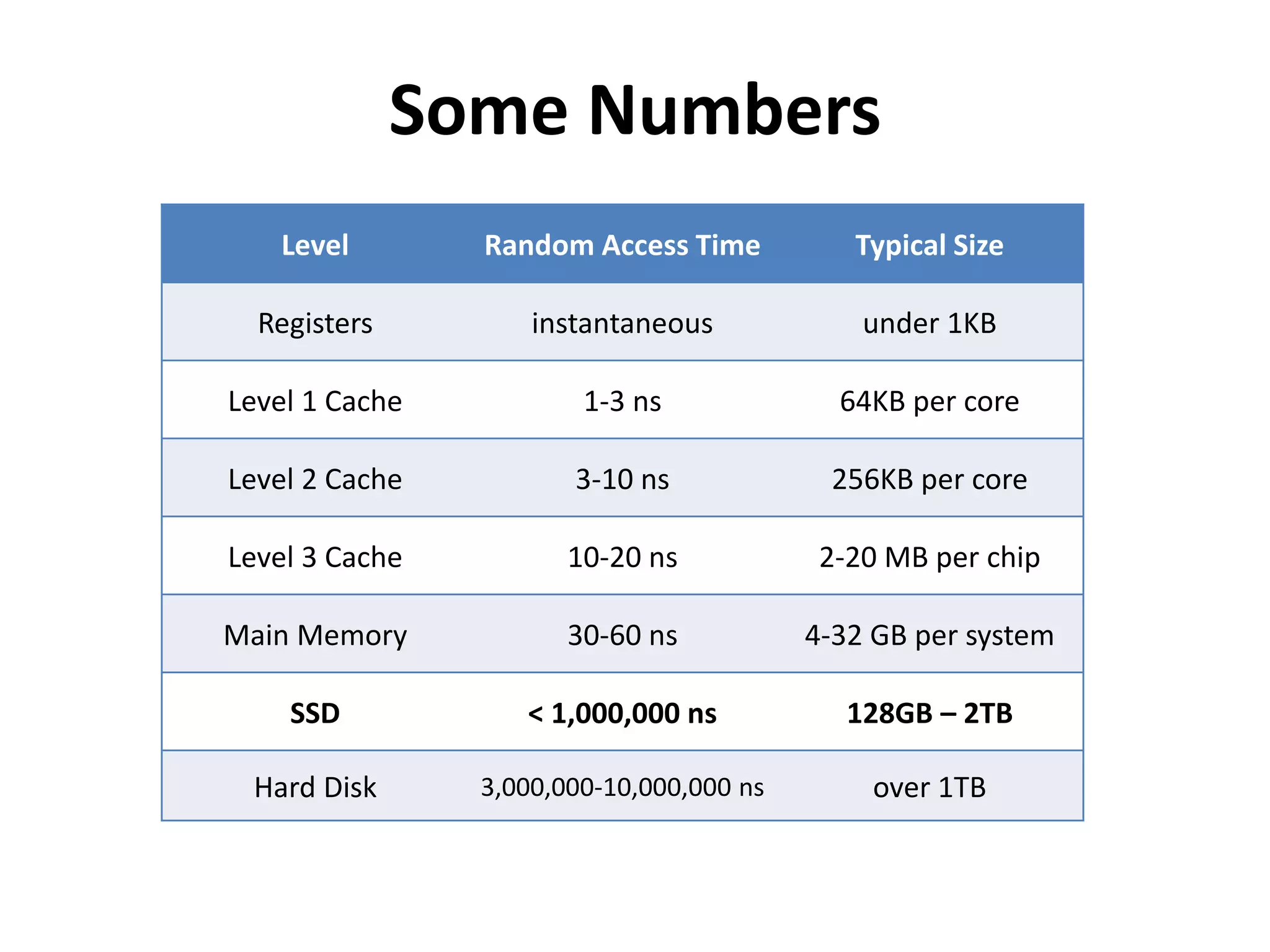
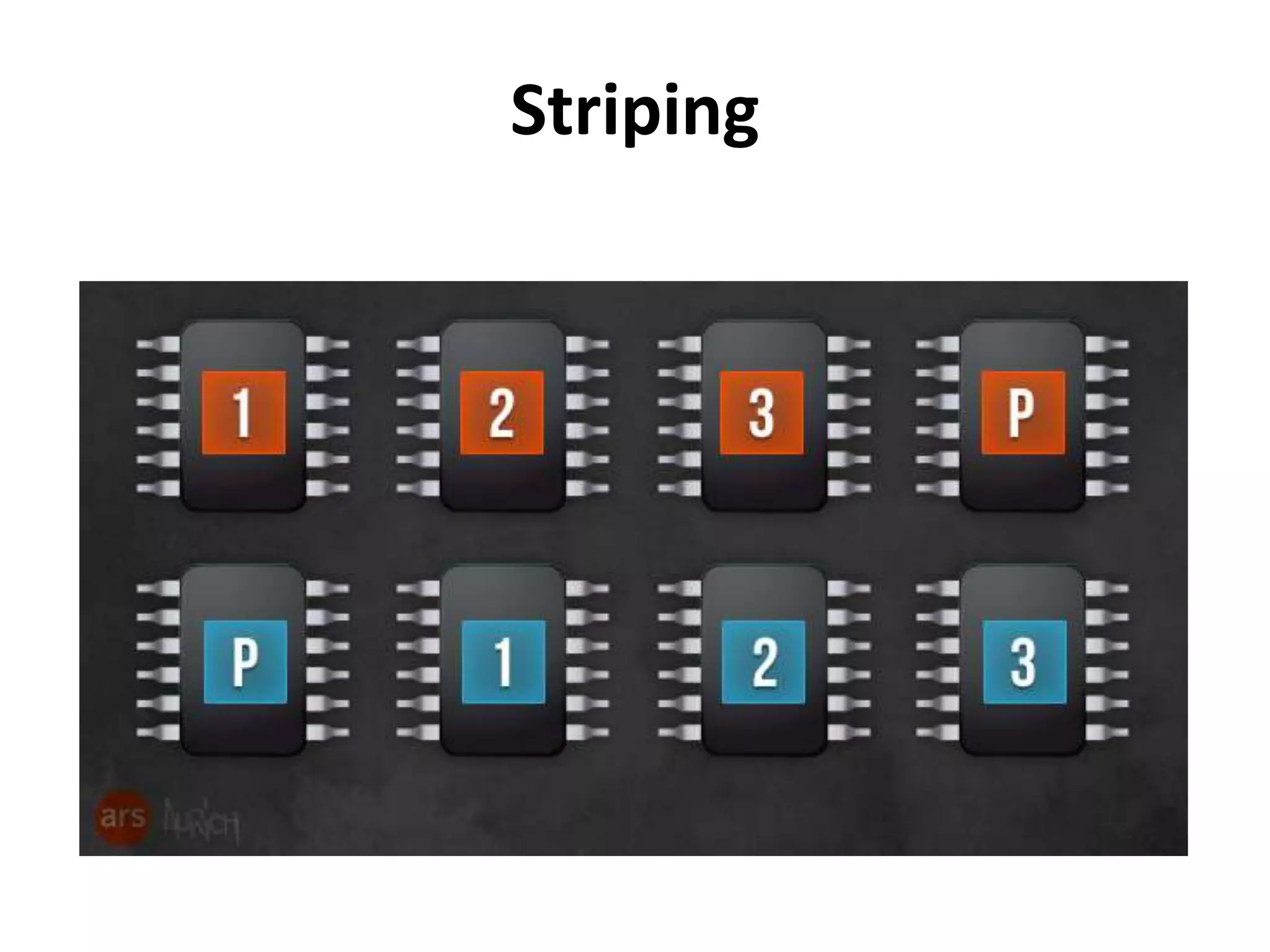
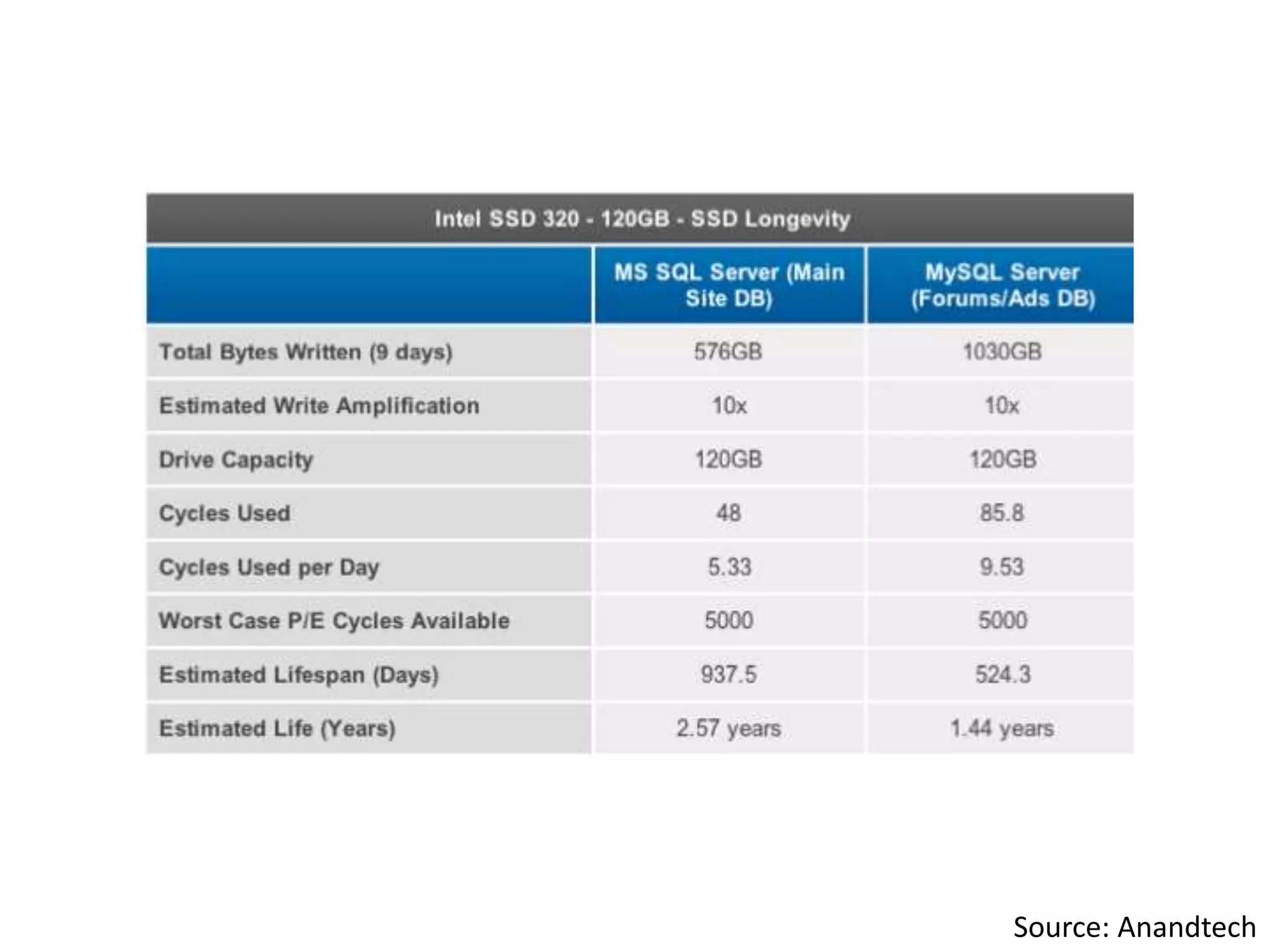
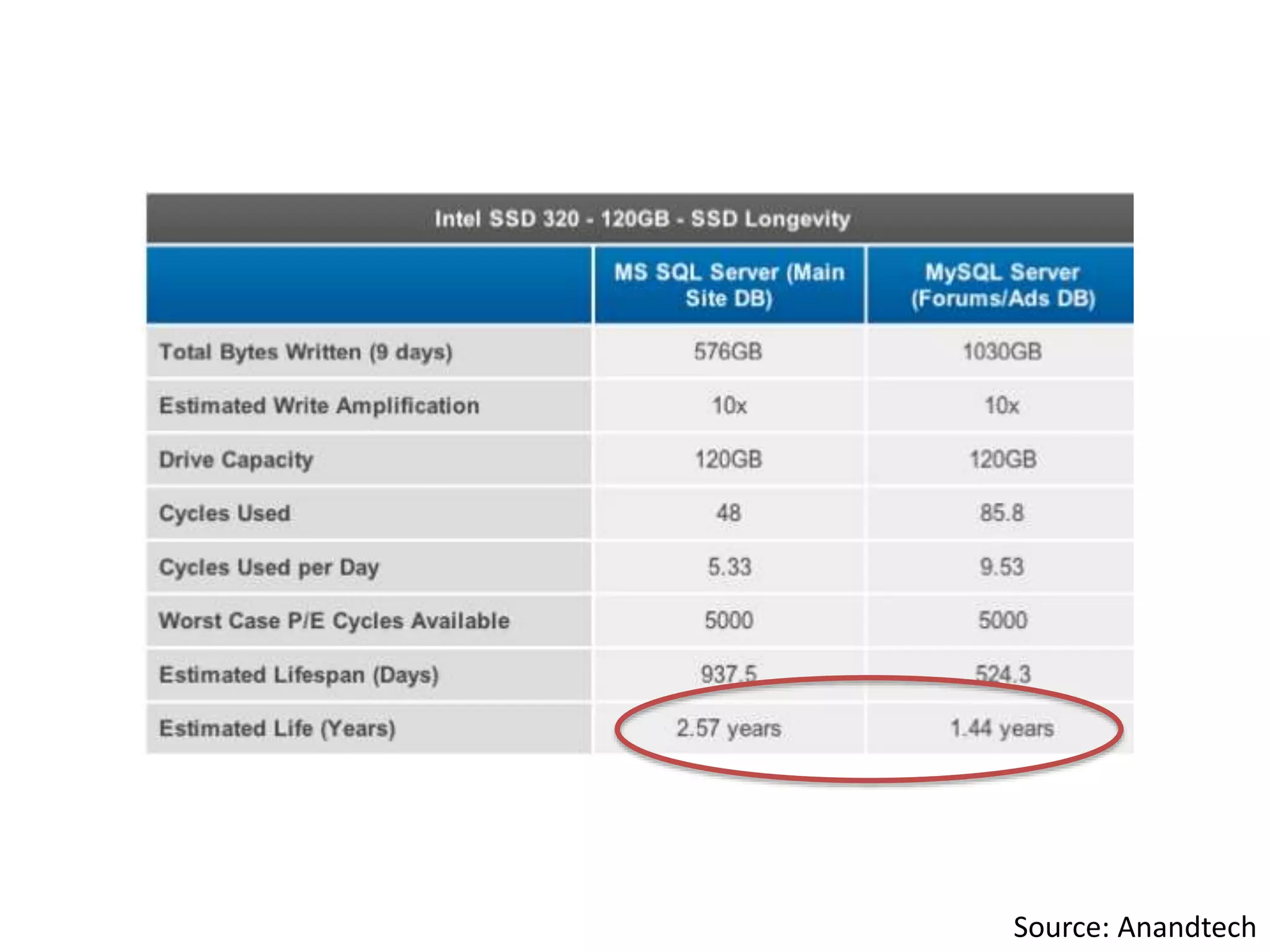
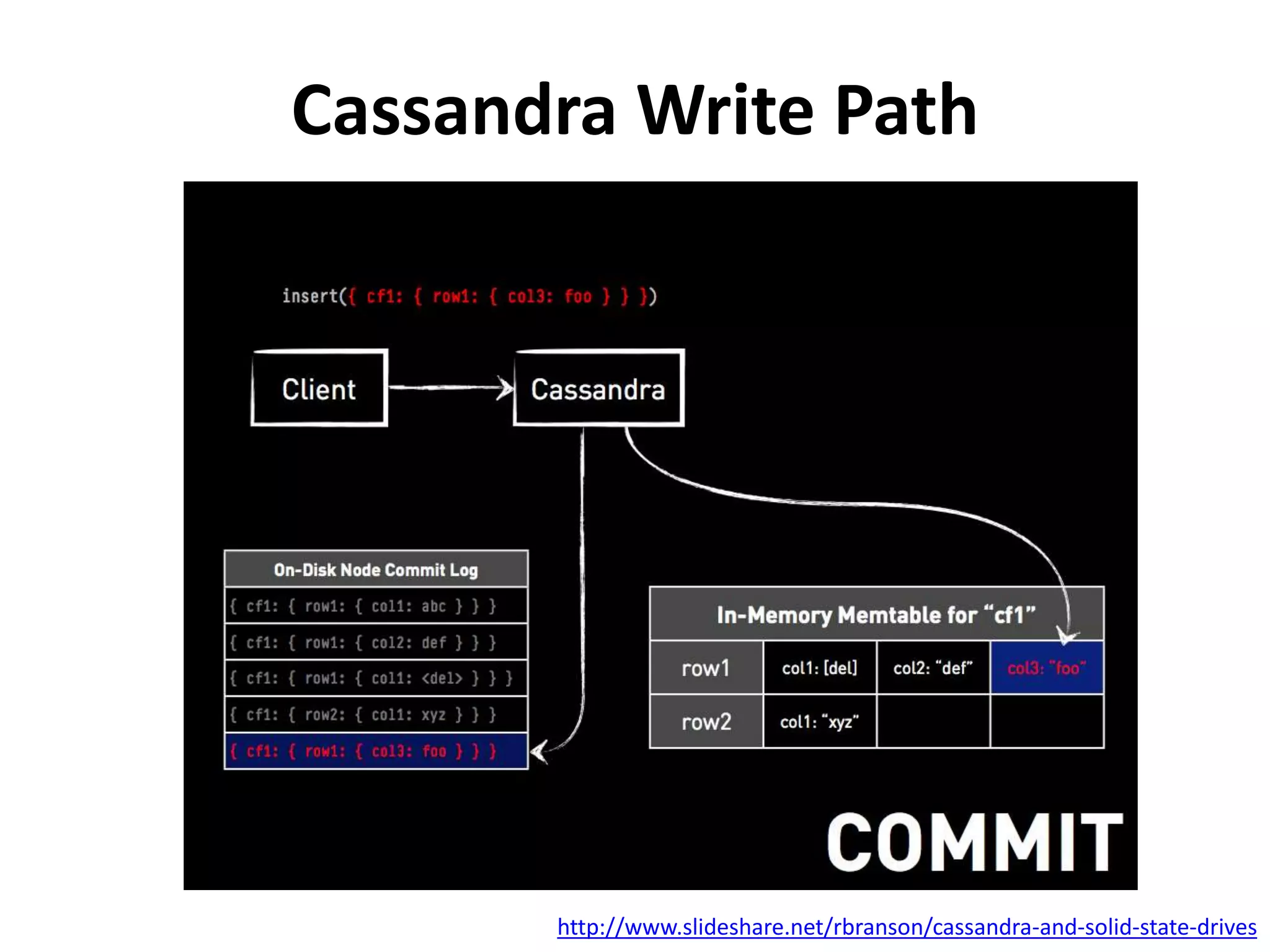
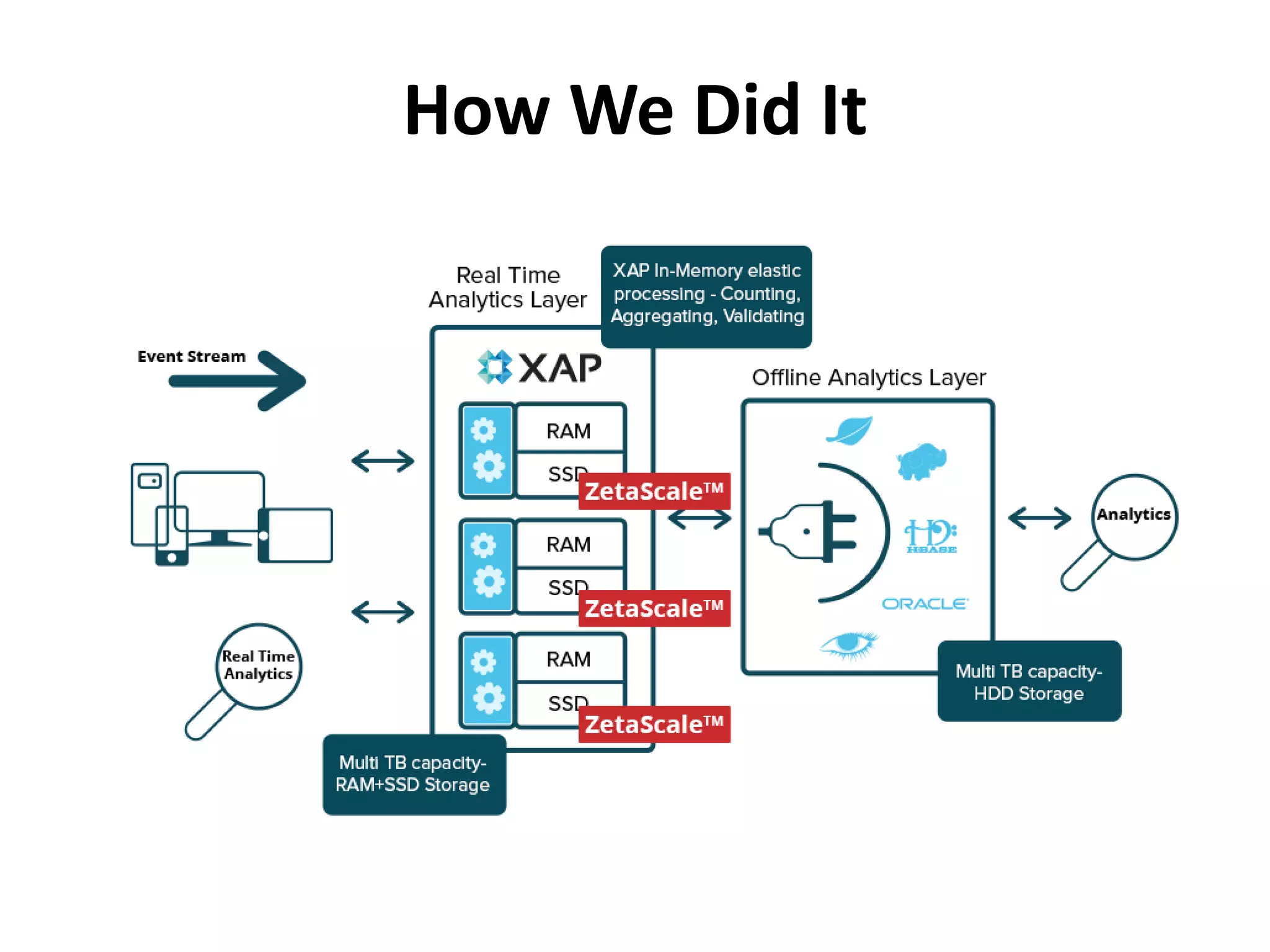
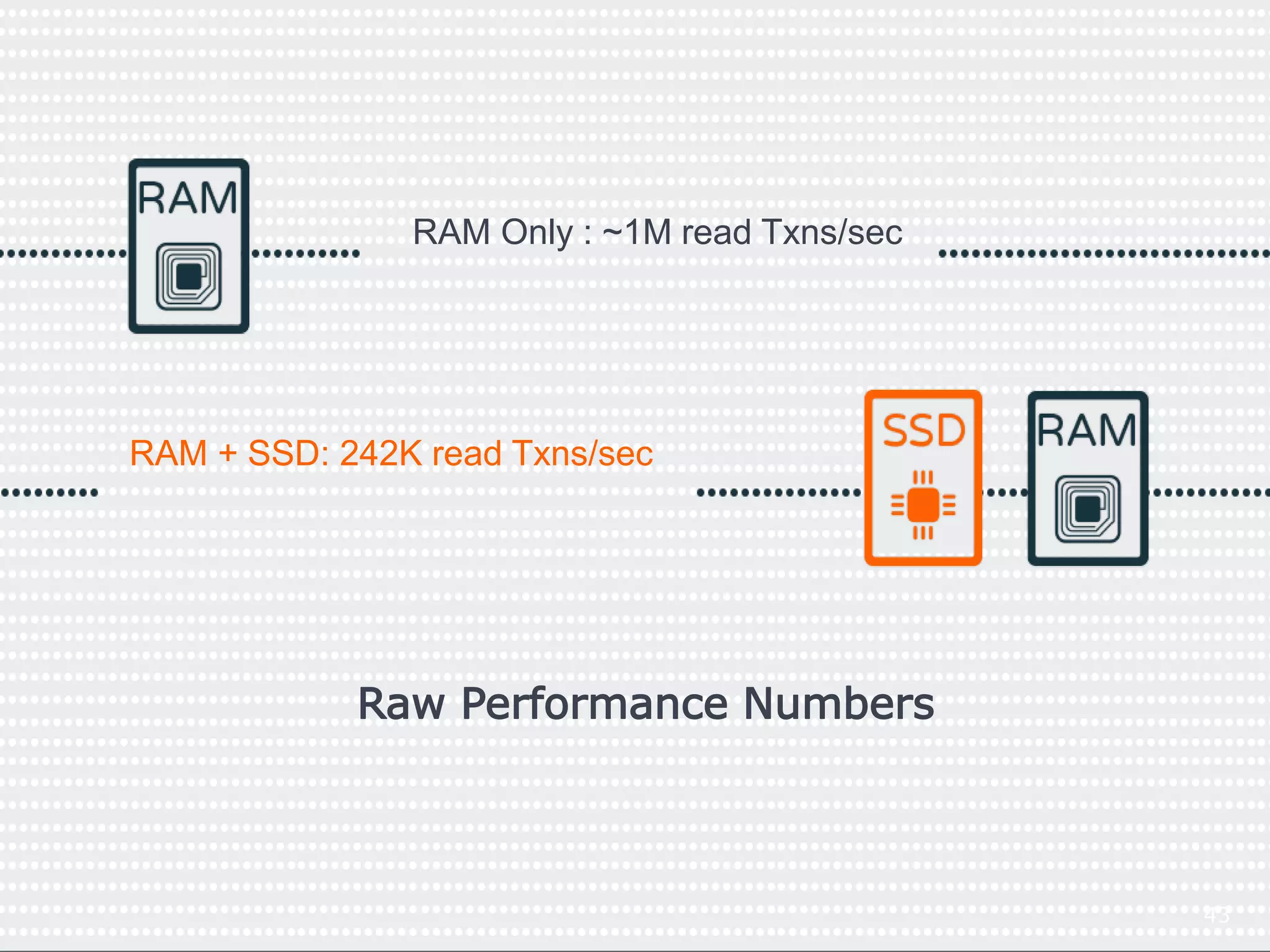
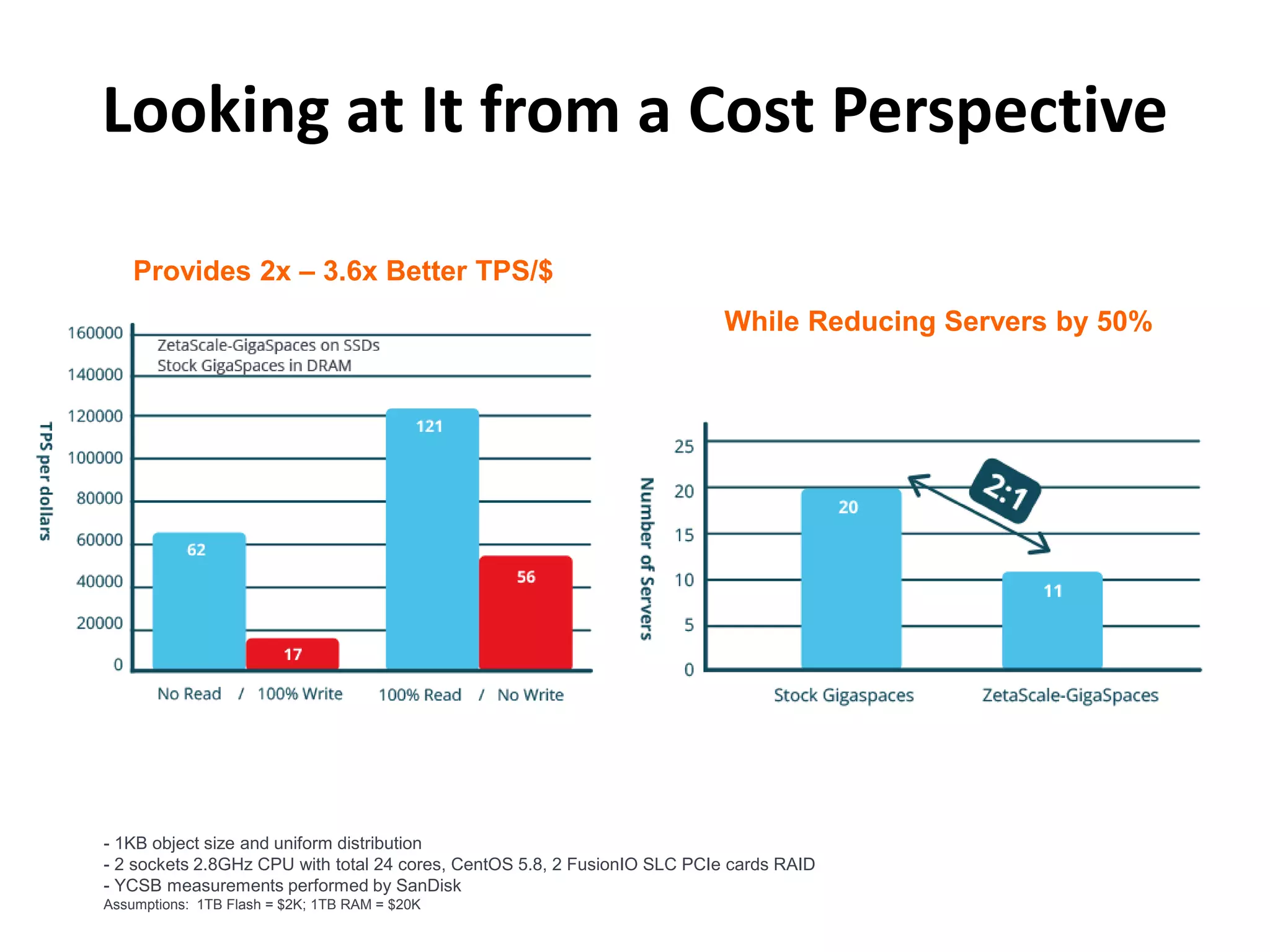
This document discusses how SSDs are improving data processing performance compared to HDDs and memory. It outlines the performance differences between various storage levels like registers, caches, RAM, SSDs, and HDDs. It then discusses some of the challenges with SSDs related to their NAND chip architecture and controllers. It provides examples of how databases like Cassandra and MySQL can be optimized for SSD performance characteristics like sequential writes. The document argues that software needs to better utilize direct SSD access and trim commands to maximize performance.