






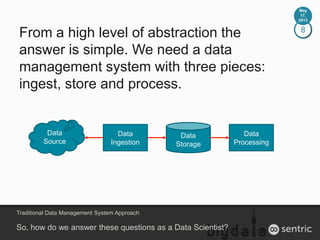









This document contains information about a Hadoop analytics system setup including components like OpenWRT, Flume, HDFS, Hive, Impala, Pentaho and Excel. It describes how data from two WiFi access points is ingested using Flume and stored in HDFS. Pentaho is used to transform and load the data into a Hive data warehouse where the data can be queried using Impala. Various analyses are then performed on the data using Hive and Impala and visualized in Excel. The document also contains announcements about an upcoming Cloudera Administrator training course.






















































