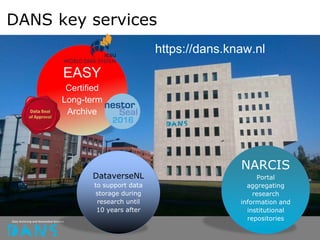
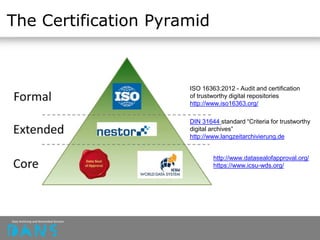
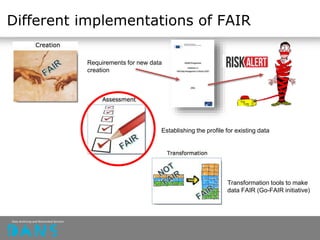
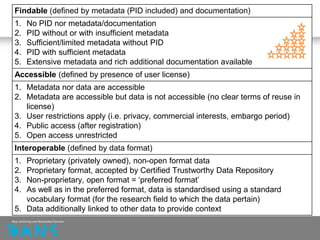
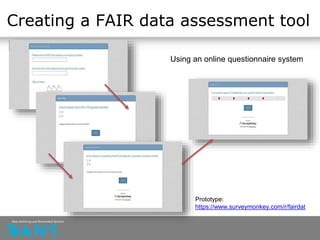
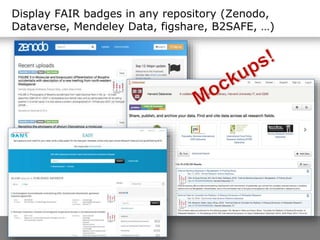
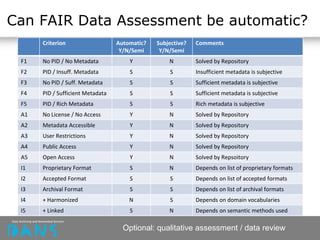
The document discusses the principles of FAIR (Findable, Accessible, Interoperable, Reusable) data and their implementation through trusted digital repositories, particularly focusing on the role of the Data Archiving and Networked Services (DANS) in promoting data quality and access. It outlines the importance of certifications like Data Seal of Approval (DSA) and ISO standards in ensuring data integrity and compliance with ethical norms. Additionally, it illustrates the relationship between DSA criteria and FAIR principles as a framework for evaluating data quality as well as accessibility for research purposes.